Искусственный интеллект
Изменение эмоций в видеозаписях с помощью ИИ

Исследователи из Греции и Великобритании разработали новый подход глубокого обучения к изменению выражений и настроений людей в видеозаписях, сохраняя при этом точность движений губ в соответствии с исходным аудио, что не удалось сделать предыдущим попыткам.

Из видео, сопровождающего статью (встроено в конце этой статьи), короткий клип актера Аль Пачино, чье выражение тонко изменено с помощью NED, основанного на высокоуровневых семантических концепциях, определяющих индивидуальные выражения лица и связанные с ними эмоции. Метод “Reference-Driven” справа принимает интерпретированную эмоцию источника видео и применяет ее ко всему видео последовательности. Источник: https://www.youtube.com/watch?v=Li6W8pRDMJQ
Эта конкретная область входит в категорию deepfaked эмоций, где сохраняется идентичность исходного говорящего, но изменяются его выражения и микровыражения. По мере совершенствования этой технологии ИИ появляется возможность для кинопроизводства и телепроизводства вносить тонкие изменения в выражения актеров – но также открывается новая категория “эмоционально измененных” видео deepfakes.
Изменение лиц
Выражения лиц для публичных деятелей, таких как политики, тщательно курируются; в 2016 году выражения лица Хиллари Клинтон подверглись интенсивному медиа скрутиню за их потенциальное негативное влияние на ее избирательные перспективы; выражения лица, оказывается, также являются темой интереса для ФБР; и они являются критическим индикатором на собеседованиях, что делает (далекий) перспективу живого фильтра “контроля выражения” желательным развитием для соискателей, пытающихся пройти предварительный экран на Zoom.
Исследование 2005 года из Великобритании утверждало, что внешний вид лица влияет на решения о голосовании, в то время как статья Washington Post 2019 года рассмотрела использование видеоклипов “вне контекста”, что в настоящее время является ближайшим к тому, что фальсификаторы новостей имеют возможность фактически изменить, как публичная фигура кажется ведет себя, реагирует или чувствует.
К нейронному манипулированию выражением
На данный момент состояние искусства в манипулировании лицевым аффектом довольно примитивно, поскольку оно включает в себя решение проблемы дезентанглемента высокоуровневых концепций (таких как грустный, злой, счастливый, улыбающийся) из фактического видео контента. Хотя традиционные архитектуры deepfake кажутся достигают этого дезентанглемента довольно хорошо, зеркалирование эмоций через разные идентичности все еще требует, чтобы два набора данных лиц содержали соответствующие выражения для каждой идентичности.

Типичные примеры изображений лиц в наборах данных, используемых для обучения deepfake. В настоящее время вы можете изменить выражение лица человека, создавая идентификатор-специфические пути выражениявыражения в нейронной сети deepfake. Программное обеспечение deepfake 2017 года не имеет внутреннего, семантического понимания “улыбки” – оно просто сопоставляет и соответствует воспринимаемым изменениям геометрии лица между двумя субъектами.
Что желательно, и еще не было идеально достигнуто, – это признание того, как субъект Б (например) улыбается, и просто создание ‘улыбки’ переключателя в архитектуре, без необходимости сопоставлять его с эквивалентным изображением субъекта А, улыбающегося.
Новая статья называется Нейронный директор эмоций: Спич-презервирующий семантический контроль лицевых выражений в “в дикой природе” видео, и исходит от исследователей из Школы электротехники и компьютерных наук Национального технического университета Афин, Института компьютерных наук Фонда исследований и технологий Hellas (FORTH), и Колледжа инженерии, математики и физических наук Университета Эксетера в Великобритании.
Команда разработала框架 под названием Нейронный директор эмоций (NED), включающий 3D-основанную сеть перевода эмоций, 3D-Основанный манипулятор эмоциями.
NED принимает полученную последовательность параметров выражения и переводит их в целевую область. Он обучен на не параллельных данных, что означает, что не обязательно обучать на наборах данных, где каждая идентичность имеет соответствующие лицевые выражения.
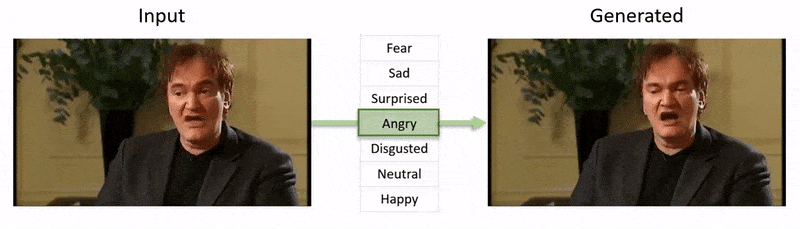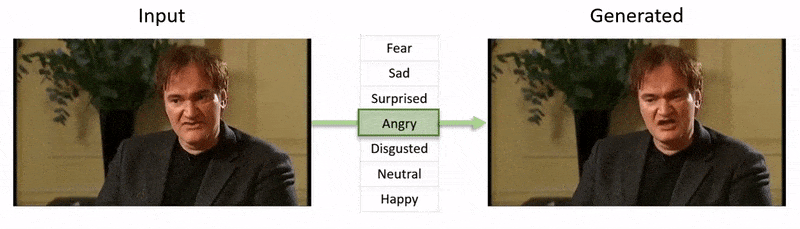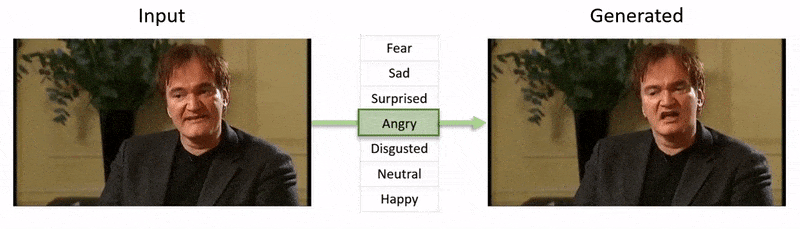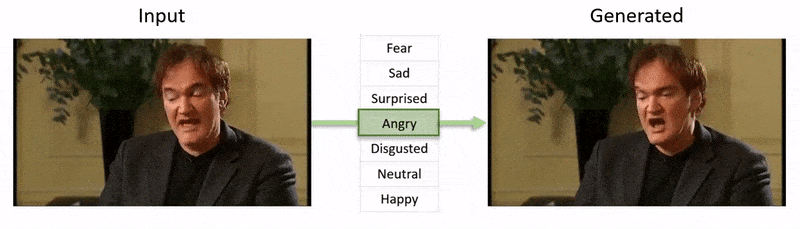
Видео, показанное в конце этой статьи, проходит через ряд тестов, где NED навязывает видимое эмоциональное состояние кадрам из набора данных YouTube.
Авторы утверждают, что NED является первым видео-основанным методом для “направления” актеров в случайных и непредсказуемых ситуациях, и разместили код на странице проекта NED.
Метод и архитектура
Система обучена на двух больших видео наборах данных, которые были аннотированы метками “эмоций”.
Выход осуществляется с помощью видео рендерера лица, который рендерит желаемую эмоцию в видео, используя традиционные методы синтеза лицевых изображений, включая сегментацию лица, выравнивание ориентиров и смешивание, где синтезируется только область лица, и затем наложена на исходное видео.

Архитектура для конвейера Нейронного детектора эмоций (NED). Источник: https://arxiv.org/pdf/2112.00585.pdf
Первоначально система получает 3D-восстановление лица и навязывает выравнивание ориентиров на входных кадрах, чтобы определить выражение. После этого эти восстановленные параметры выражения передаются в 3D-основанный манипулятор эмоциями, и вычисляется вектор стиля средствами либо семантической метки (такой как “счастливый”), либо ссылочного файла.
Ссылочный файл – это видео, изображающее конкретно признанное выражение/эмоцию, которое затем наложено на всю целевую видео, заменяя исходное выражение.

Этапы в конвейере передачи эмоций, в которых участвуют различные актеры, отобранные из видео YouTube.
Наконец, сгенерированная 3D форма лица затем объединяется с Нормализованными средними координатами лица (NMFC) и изображениями глаз (красные точки на изображении выше), и передается нейронному рендереру, который выполняет окончательную манипуляцию.
Результаты
Исследователи провели обширные исследования, включая пользовательские и абляционные исследования, чтобы оценить эффективность метода по сравнению с предыдущей работой, и обнаружили, что в большинстве категорий NED превосходит текущее состояние искусства в этом подсекторе нейронной манипуляции лица.

Авторы статьи предполагают, что более поздние реализации этой работы, и инструменты подобного рода, будут полезны в первую очередь в телевизионной и кинопроизводстве, заявляя:
‘Наш метод открывает множество новых возможностей для полезных приложений технологий нейронного рендеринга, от пост-продакшна фильмов и видеоигр до фотореалистичных аффективных аватаров.’
Это ранняя работа в этой области, но одна из первых, которая попыталась изменить выражение лица на видео, а не на статичных изображениях. Хотя видео по сути являются многими статичными изображениями, следующими друг за другом очень быстро, есть временные соображения, которые делают предыдущие применения передачи эмоций менее эффективными. В сопровождающем видео и примерах в статье авторы включают визуальные сравнения вывода NED с другими сравнимыми недавними методами.

Более подробные сравнения и многие больше примеры NED можно найти в полном видео ниже:
3 декабря 2021 года, 18:30 GMT+2 – По просьбе одного из авторов статьи были внесены исправления относительно “ссылочного файла”, который я ошибочно указал как статичную фотографию (когда на самом деле это видеоклип). Также внесено исправление в название Института компьютерных наук Фонда исследований и технологий.
3 декабря 2021 года, 20:50 GMT+2 – Вторая просьба от одного из авторов статьи о дальнейшем исправлении названия вышеупомянутого учреждения.












