
Best Of
10 лучших алгоритмов машинного обучения
Хотя мы живем в эпоху выдающихся инноваций в машинном обучении с ускорением на графических процессорах, в последних исследовательских работах часто (и заметно) представлены алгоритмы, которым уже несколько десятилетий, а в некоторых случаях и 70 лет.
Кто-то может возразить, что многие из этих старых методов относятся к лагерю «статистического анализа», а не к машинному обучению, и предпочитают датировать появление этого сектора только 1957 годом, т. изобретение персептрона.
Учитывая степень, в которой эти старые алгоритмы поддерживают последние тенденции и захватывающие заголовки разработки в области машинного обучения и связаны с ними, это спорная позиция. Итак, давайте взглянем на некоторые из «классических» строительных блоков, лежащих в основе последних инноваций, а также на некоторые новые разработки, которые делают первые заявки на попадание в зал славы ИИ.
1: Трансформеры
В 2017 году Google Research возглавила исследовательское сотрудничество, завершившееся бумаги Внимание это все, что вам нужно. В работе изложена новая архитектура, которая продвигала механизмы внимания от «конвейера» в кодировщике/декодере и рекуррентных сетевых моделях до самостоятельной центральной трансформационной технологии.
Подход получил название трансформатори с тех пор стала революционной методологией в области обработки естественного языка (НЛП), лежащей в основе, среди многих других примеров, авторегрессионной языковой модели и ИИ-плаката GPT-3.
![]()
Трансформеры изящно решили проблему трансдукция последовательности, также называемый «преобразованием», которое занимается обработкой входных последовательностей в выходные последовательности. Преобразователь также получает данные и управляет ими непрерывно, а не последовательными пакетами, обеспечивая «постоянство памяти», для которого не предназначены архитектуры RNN. Более подробный обзор трансформаторов см. наша справочная статья.
В отличие от рекуррентных нейронных сетей (RNN), которые начали доминировать в исследованиях машинного обучения в эпоху CUDA, архитектуру Transformer также можно было легко распараллеленные, открывая способ продуктивной работы с гораздо большим массивом данных, чем RNN.
Популярное использование
Трансформеры захватили общественное внимание в 2020 году с выпуском OpenAI GPT-3, который мог похвастаться рекордным на тот момент 175 миллиарда параметров. Это явно ошеломляющее достижение в конечном итоге было омрачено более поздними проектами, такими как проект 2021 года. освободить Megatron-Turing NLG 530B от Microsoft, который (как следует из названия) имеет более 530 миллиардов параметров.

Хронология гипермасштабных проектов Transformer NLP. Источник: Microsoft
Трансформаторная архитектура также перешла от НЛП к компьютерному зрению, положив начало Новое поколение фреймворков синтеза изображений, таких как OpenAI CLIP и DALL-E, которые используют сопоставление доменов текст>изображение для завершения неполных изображений и синтеза новых изображений из обученных доменов среди растущего числа связанных приложений.

DALL-E пытается завершить частичное изображение бюста Платона. Источник: https://openai.com/blog/dall-e/
2: Генеративно-состязательные сети (GAN)
Хотя трансформаторы получили широкое освещение в СМИ благодаря выпуску и внедрению GPT-3, Генеративная Состязательная Сеть (GAN) стала самостоятельным узнаваемым брендом и может в конечном итоге присоединиться к deepfake как глагол.
Первый предложенный в 2014 и в основном используется для синтеза изображений, генеративно-состязательной сети. архитектура состоит из Генератор и еще один Дискриминатор. Генератор циклически перебирает тысячи изображений в наборе данных, итеративно пытаясь реконструировать их. Для каждой попытки Дискриминатор оценивает работу Генератора и отправляет Генератор обратно, чтобы он работал лучше, но без какого-либо понимания того, как ошиблась предыдущая реконструкция.

Источник: https://developers.google.com/machine-learning/gan/gan_structure.
Это вынуждает Генератор исследовать множество путей вместо того, чтобы идти по потенциальным тупикам, которые возникли бы, если бы Дискриминатор сообщил ему, где что-то идет не так (см. № 8 ниже). К моменту окончания обучения Генератор имеет подробную и исчерпывающую карту взаимосвязей между точками в наборе данных.

Из бумаги Улучшение равновесия GAN за счет повышения пространственной осведомленности: новый фреймворк циклически перемещается по иногда загадочному скрытому пространству GAN, предоставляя гибкие инструменты для архитектуры синтеза изображений. Источник: https://genforce.github.io/eqgan/
По аналогии, в этом и заключается разница между изучением одного скучного пути до центра Лондона и кропотливым приобретением Знание.
Результатом является высокоуровневый набор функций в скрытом пространстве обученной модели. Семантический индикатор для признака высокого уровня может быть «человек», в то время как спуск по специфичности, связанной с признаком, может обнаружить другие изученные характеристики, такие как «мужской» и «женский». На более низких уровнях подфункции могут разбиваться на «блондин», «кавказец» и др.
Запутанность важная проблема в скрытом пространстве GAN и фреймворков кодировщика/декодера: является ли улыбка на сгенерированном GAN женском лице запутанной чертой ее «идентичности» в скрытом пространстве или это параллельная ветвь?

Созданные GAN лица от этого человека не существуют. Источник: https://this-person-does-not-exist.com/en
За последние пару лет появилось все больше новых исследовательских инициатив в этом отношении, что, возможно, проложило путь к редактированию скрытого пространства GAN на уровне функций, в стиле Photoshop, но в настоящее время многие преобразования эффективно « Пакеты «все или ничего». Примечательно, что выпуск NVIDIA EditGAN в конце 2021 года обеспечивает высокий уровень интерпретируемости в скрытом пространстве с помощью масок семантической сегментации.
Популярное использование
Помимо их (на самом деле довольно ограниченного) участия в популярных дипфейковых видео, GAN, ориентированные на изображения/видео, за последние четыре года получили широкое распространение, приводя в восторг как исследователей, так и общественность. Идти в ногу с головокружительной скоростью и частотой новых выпусков — непростая задача, хотя репозиторий GitHub Потрясающие приложения GAN стремится предоставить исчерпывающий список.
Генеративно-состязательные сети теоретически могут извлекать функции из любой хорошо структурированной области. включая текст.
3: СВМ
Порожденный в 1963, Машина опорных векторов (SVM) — это основной алгоритм, который часто появляется в новых исследованиях. В SVM векторы отображают относительное расположение точек данных в наборе данных, а поддержка векторы очерчивают границы между различными группами, признаками или признаками.
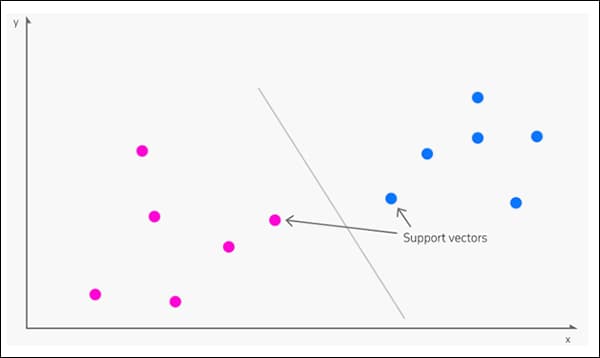
Опорные векторы определяют границы между группами. Источник: https://www.kdnuggets.com/2016/07/support-vector-machines-simple-explanation.html.
Полученная граница называется гиперплоскость.
На низких уровнях функций SVM двумерный (изображение выше), но там, где распознано большее количество групп или типов, становится трехмерный.

Более глубокий массив точек и групп требует трехмерного SVM. Источник: https://cml.rhul.ac.uk/svm.html
Популярное использование
Поскольку векторные машины поддержки могут эффективно и независимо обращаться с многомерными данными многих типов, они широко используются в различных секторах машинного обучения, включая обнаружение дипфейка, классификация изображений, классификация языка ненависти, Анализ ДНК и прогнозирование структуры населения, среди многих других.
4: Кластеризация K-средних
Кластеризация вообще неконтролируемое обучение подход, который стремится классифицировать точки данных через оценка плотности, создание карты распределения изучаемых данных.

Кластеризация K-средних определяет сегменты, группы и сообщества в данных. Источник: https://aws.amazon.com/blogs/machine-learning/k-means-clustering-with-amazon-sagemaker/
Кластеризация K-сред стала самой популярной реализацией этого подхода, объединяя точки данных в отдельные «К-группы», которые могут указывать на демографические секторы, онлайн-сообщества или любые другие возможные секретные агрегации, ожидающие своего обнаружения в необработанных статистических данных.

Кластеры формируются при анализе K-средних. Источник: https://www.geeksforgeeks.org/ml-determine-the-optimal-value-of-k-in-k-means-clustering/
Значение K само по себе является определяющим фактором полезности процесса и определения оптимального значения для кластера. Первоначально значение K присваивается случайным образом, а его признаки и векторные характеристики сравниваются с его соседями. Те соседи, которые больше всего напоминают точку данных со случайно назначенным значением, итеративно назначаются в ее кластер, пока данные не будут сгруппированы во все группы, разрешенные процессом.
График квадрата ошибки или «стоимости» различных значений среди кластеров покажет точка локтя для данных:

«Точка локтя» на кластерном графике. Источник: https://www.scikit-yb.org/en/latest/api/cluster/elbow.html.
Точка локтя по своей концепции аналогична тому, как потери сглаживаются до убывающей отдачи в конце сеанса обучения для набора данных. Он представляет собой точку, в которой дальнейшие различия между группами не станут очевидными, указывая момент, чтобы перейти к последующим этапам в конвейере данных или же сообщить о результатах.
Популярное использование
Кластеризация K-средних по очевидным причинам является основной технологией анализа клиентов, поскольку она предлагает четкую и объяснимую методологию преобразования большого количества коммерческих записей в демографические данные и «лиды».
Помимо этого приложения, кластеризация K-средних также используется для прогноз оползней, сегментация медицинских изображений, синтез изображений с помощью GAN, классификация документови планирование Город, среди многих других потенциальных и фактических применений.
5: Случайный лес
Случайный лес — это обучение ансамблю метод, который усредняет результат из массива деревья решений сделать общий прогноз результата.

Источник: https://www.tutorialandexample.com/wp-content/uploads/2019/10/Decision-Trees-Root-Node.png
Если вы изучили его хотя бы немного, посмотрев Назад в будущее В трилогии само дерево решений довольно легко концептуализировать: перед вами лежит ряд путей, и каждый путь разветвляется к новому результату, который, в свою очередь, содержит дальнейшие возможные пути.
In усиление обучения, вы можете отступить от пути и начать снова с более ранней позиции, в то время как деревья решений совершают свои путешествия.
Таким образом, алгоритм Random Forest, по сути, является спредом для решений. Алгоритм называется «случайным», потому что он делает специальный отбор и наблюдения для того, чтобы понять медиана сумма результатов из массива дерева решений.
Поскольку он учитывает множество факторов, метод случайного леса может быть труднее преобразовать в осмысленные графы, чем дерево решений, но, вероятно, он будет значительно более продуктивным.
Деревья решений подвержены переоснащению, когда полученные результаты зависят от данных и вряд ли будут обобщены. Произвольный выбор точек данных Random Forest борется с этой тенденцией, раскрывая значимые и полезные репрезентативные тенденции в данных.

Регрессия дерева решений. Источник: https://scikit-learn.org/stable/auto_examples/tree/plot_tree_regression.html.
Популярное использование
Как и многие алгоритмы из этого списка, Random Forest обычно действует как «ранний» сортировщик и фильтр данных, и поэтому постоянно появляется в новых исследовательских работах. Некоторые примеры использования Random Forest включают: Синтез магнитно-резонансных изображений, Прогнозирование цены биткойнов, сегментация переписи, классификация текста и обнаружение мошенничества с кредитными картами.
Поскольку Random Forest является низкоуровневым алгоритмом в архитектурах машинного обучения, он также может способствовать повышению производительности других низкоуровневых методов, а также алгоритмов визуализации, в том числе Индуктивная кластеризация, Преобразования функций, классификация текстовых документов использование разреженных функцийи отображение конвейеров.
6: Наивный Байес
В сочетании с оценкой плотности (см. 4, выше), а наивный байесовский классификатор — это мощный, но относительно легкий алгоритм, способный оценивать вероятности на основе рассчитанных характеристик данных.

Отношения признаков в наивном байесовском классификаторе. Источник: https://www.sciencedirect.com/topics/computer-science/naive-bayes-model
Термин «наивный» относится к предположению в Теорема Байеса что функции не связаны между собой, известные как условная независимость. Если вы принимаете эту точку зрения, то того, что вы ходите и говорите, как утка, недостаточно, чтобы установить, что мы имеем дело с уткой, и никакие «очевидные» предположения не принимаются преждевременно.
Такой уровень академической и исследовательской строгости был бы излишним там, где доступен «здравый смысл», но он является ценным стандартом при преодолении многих неясностей и потенциально несвязанных корреляций, которые могут существовать в наборе данных машинного обучения.
В исходной байесовской сети функции подлежат скоринговые функции, включая минимальную длину описания и Байесовская оценка, что может налагать ограничения на данные с точки зрения предполагаемых соединений, найденных между точками данных, и направления, в котором эти соединения протекают.
Наивный байесовский классификатор, наоборот, действует, предполагая, что характеристики данного объекта независимы, и впоследствии использует теорему Байеса для вычисления вероятности данного объекта на основе его характеристик.
Популярное использование
Наивные байесовские фильтры хорошо представлены в прогнозирование заболеваний и категоризация документов, фильтрация спама, классификация настроений, рекомендательные системыи обнаружение мошенничествасреди других приложений.
7: K- Ближайшие соседи (KNN)
Впервые предложен Школой авиационной медицины ВВС США. в 1951, и необходимость приспосабливаться к современному компьютерному оборудованию середины 20-го века, K-Ближайшие соседи (KNN) — это экономичный алгоритм, который по-прежнему занимает видное место в научных статьях и инициативах по исследованию машинного обучения в частном секторе.
KNN называют «ленивым учеником», поскольку он полностью сканирует набор данных, чтобы оценить отношения между точками данных, а не требует обучения полноценной модели машинного обучения.

Группировка KNN. Источник: https://scikit-learn.org/stable/modules/neighbors.html
Хотя KNN архитектурно стройна, ее систематический подход предъявляет заметные требования к операциям чтения/записи, и ее использование в очень больших наборах данных может быть проблематичным без дополнительных технологий, таких как анализ основных компонентов (PCA), который может преобразовывать сложные и объемные наборы данных. в репрезентативные группы что KNN может пройти с меньшими усилиями.
A Недавнее исследование оценил эффективность и экономичность ряда алгоритмов, которым было поручено предсказать, покинет ли сотрудник компанию, и обнаружил, что семидесятилетний KNN по-прежнему превосходит более современные соперники с точки зрения точности и эффективности прогнозирования.
Популярное использование
При всей своей популярной простоте концепции и исполнения, KNN не застрял в 1950-х годах — он был адаптирован в более ориентированный на DNN подход в предложении Пенсильванского государственного университета в 2018 году и остается центральным процессом на ранней стадии (или аналитическим инструментом постобработки) во многих гораздо более сложных средах машинного обучения.
В различных конфигурациях KNN использовался или для онлайн проверка подписи, классификация изображений, добыча текста, предсказание урожаяи распознавания лиц, помимо других приложений и включений.

Система распознавания лиц на основе KNN в процессе обучения. Source: https://pdfs.semanticscholar.org/6f3d/d4c5ffeb3ce74bf57342861686944490f513.pdf
8: Марковский процесс принятия решений (MDP)
Математическая основа, представленная американским математиком Ричардом Беллманом. в 1957, Марковский процесс принятия решений (MDP) является одним из самых основных блоков усиление обучения архитектуры. Сам по себе концептуальный алгоритм, он был адаптирован для большого количества других алгоритмов и часто повторяется в текущих исследованиях AI/ML.
MDP исследует среду данных, используя свою оценку ее текущего состояния (т. е. «где» она находится в данных), чтобы решить, какой узел данных исследовать дальше.

Источник: https://www.sciencedirect.com/science/article/abs/pii/S0888613X18304420
Базовый марковский процесс принятия решений будет отдавать приоритет краткосрочным преимуществам, а не более желательным долгосрочным целям. По этой причине оно обычно встроено в контекст более комплексной архитектуры политики обучения с подкреплением и часто подвержено ограничивающим факторам, таким как: вознаграждение со скидкой, и другие изменяющие переменные среды, которые не позволят ему спешить к непосредственной цели без учета более широкого желаемого результата.
Популярное использование
Концепция низкого уровня MDP широко распространена как в исследованиях, так и в активном развертывании машинного обучения. Это было предложено для Системы защиты безопасности IoT, лов рыбыи прогнозирование рынка.
Помимо его очевидная применимость шахматам и другим строго последовательным играм, MDP также является естественным претендентом на процедурное обучение робототехнических комплексов, как мы можем видеть на видео ниже.

9: Частота термина, обратная частоте документа
Срок Частота (TF) делит количество раз, которое слово встречается в документе, на общее количество слов в этом документе. Таким образом, слово появляясь один раз в статье из тысячи слов, частота терминов составляет 0.001. Сам по себе TF в значительной степени бесполезен в качестве индикатора важности термина из-за того, что бессмысленные статьи (такие как a, и, домени it) преобладают.
Чтобы получить значимое значение для термина, обратная частота документа (IDF) вычисляет TF слова в нескольких документах в наборе данных, присваивая низкий рейтинг очень высокой частоте. игнорируемые слова, такие как статьи. Результирующие векторы признаков нормализуются до целых значений, при этом каждому слову присваивается соответствующий вес.

TF-IDF взвешивает релевантность терминов на основе их частоты в ряде документов, при этом более редкое появление является показателем значимости. Источник: https://moz.com/blog/inverse-document-frequency-and-the-importance-of-uniqueness.
Хотя этот подход предотвращает потерю семантически важных слов, поскольку выбросы, инвертирование частотного веса не означает автоматически, что низкочастотный член не выброс, потому что некоторые вещи редки и бесполезный. Следовательно, низкочастотный термин должен будет доказать свою ценность в более широком архитектурном контексте, появляясь (даже с низкой частотой в документе) в ряде документов в наборе данных.
Несмотря на его возраст, TF-IDF — это мощный и популярный метод начальной фильтрации проходов в средах обработки естественного языка.
Популярное использование
Поскольку TF-IDF сыграл по крайней мере некоторую роль в разработке в значительной степени скрытого алгоритма Google PageRank за последние двадцать лет, он стал очень широкое распространение как манипулятивная тактика SEO, несмотря на то, что Джон Мюллер в 2019 г. отречение его важности для результатов поиска.
Из-за секретности PageRank нет четких доказательств того, что TF-IDF не в настоящее время эффективная тактика для повышения рейтинга Google. Зажигательный обсуждение среди ИТ-специалистов в последнее время указывает на популярное понимание, верное или нет, что злоупотребление термином все еще может привести к улучшению позиции SEO (хотя дополнительные обвинения в злоупотреблении монопольным положением и чрезмерная реклама размыть границы этой теории).
10: Стохастический градиентный спуск
Стохастический градиентный спуск (SGD) становится все более популярным методом оптимизации обучения моделей машинного обучения.
Градиентный спуск сам по себе является методом оптимизации и последующей количественной оценки улучшения, которое модель делает во время обучения.
В этом смысле «градиент» указывает на наклон вниз (а не на градацию на основе цвета, см. изображение ниже), где самая высокая точка «холма» слева представляет собой начало тренировочного процесса. На этом этапе модель еще ни разу не просмотрела все данные целиком и недостаточно узнала о взаимосвязях между данными, чтобы произвести эффективные преобразования.

Градиентный спуск на тренировке FaceSwap. Мы можем видеть, что во второй половине обучение на какое-то время стабилизировалось, но в конечном итоге восстановило свой путь вниз по градиенту к приемлемой конвергенции.
Самая нижняя точка справа представляет собой конвергенцию (точка, в которой модель настолько эффективна, насколько это возможно при наложенных ограничениях и настройках).
Градиент действует как запись и предиктор несоответствия между частотой ошибок (насколько точно модель в настоящее время отображает отношения данных) и весами (настройками, которые влияют на то, как модель будет учиться).
Эта запись о прогрессе может быть использована для информирования график скорости обучения, автоматический процесс, который заставляет архитектуру становиться более детализированной и точной по мере того, как ранние расплывчатые детали превращаются в четкие отношения и сопоставления. По сути, потеря градиента обеспечивает своевременную карту того, где обучение должно идти дальше и как оно должно проходить.
Инновация стохастического градиентного спуска заключается в том, что он обновляет параметры модели в каждом обучающем примере за итерацию, что обычно ускоряет путь к сходимости. В связи с появлением в последние годы гипермасштабируемых наборов данных, в последнее время SGD приобрела популярность как один из возможных методов решения возникающих логистических проблем.
С другой стороны, SGD имеет негативные последствия для масштабирования функций и может потребовать большего количества итераций для достижения того же результата, что требует дополнительного планирования и дополнительных параметров по сравнению с обычным градиентным спуском.
Популярное использование
Благодаря своей настраиваемости и, несмотря на свои недостатки, SGD стал самым популярным алгоритмом оптимизации для подбора нейронных сетей. Одной из конфигураций SGD, которая становится доминирующей в новых исследованиях AI/ML, является выбор оценки адаптивного момента (ADAM, представленный в 2015) оптимизатор.
ADAM динамически адаптирует скорость обучения для каждого параметра («адаптивная скорость обучения»), а также включает результаты предыдущих обновлений в последующую конфигурацию («импульс»). Кроме того, его можно настроить для использования более поздних инноваций, таких как Нестеров Импульс.
Однако некоторые утверждают, что использование импульса также может ускорить работу ADAM (и подобных алгоритмов) до неоптимальный вывод. Как и в случае с большинством передовых технологий в области исследований в области машинного обучения, SGD находится в стадии разработки.
Впервые опубликовано 10 февраля 2022 г. Исправлено 10 февраля 20.05 EET — форматирование.















