
Artificial Intelligence
Верность против реализма в видео Deepfake

Не все специалисты по дипфейкам преследуют одну и ту же цель: стимул для исследовательского сектора синтеза изображений, поддерживаемый влиятельными сторонниками, такими как саман, NVIDIA и что его цель – это продвижение современного уровня техники, чтобы методы машинного обучения могли в конечном итоге воссоздать или синтезировать человеческую деятельность с высоким разрешением и в самых сложных условиях (верность).
Напротив, цель тех, кто хочет использовать дипфейк-технологии для распространения дезинформации, состоит в том, чтобы создать правдоподобные симуляции реальных людей многими другими методами, помимо простой правдивости дипфейковых лиц. В этом сценарии дополнительные факторы, такие как контекст и правдоподобие, почти равны потенциалу видео для имитации лиц. (реализм).
Этот метод «ловкости рук» распространяется на ухудшение конечного качества изображения дипфейкового видео, так что все видео (а не только вводящая в заблуждение часть, представленная дипфейковым лицом) имеет целостный «внешний вид», который точно соответствует ожидаемое качество среды.
«Связный» не обязательно означает «хороший» — достаточно, чтобы качество было одинаковым для оригинала и вставленного, фальсифицированного контента и соответствовало ожиданиям. С точки зрения потокового вывода VOIP на таких платформах, как Skype и Zoom, планка может быть удивительно низкой, с заиканием, рывками видео и целым рядом потенциальных артефактов сжатия, а также с алгоритмами «сглаживания», разработанными для уменьшения их эффектов, которые сами по себе представляют собой дополнительный ряд «неподлинных» эффектов, которые мы приняли как следствие ограничений и эксцентричности прямых трансляций.
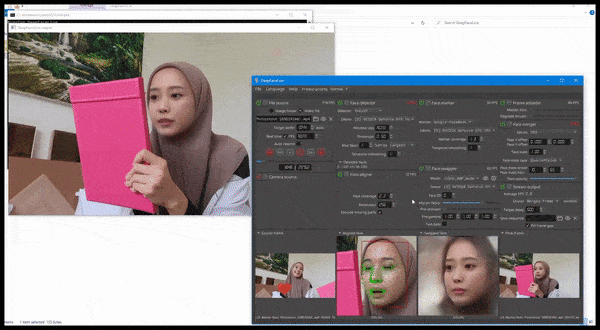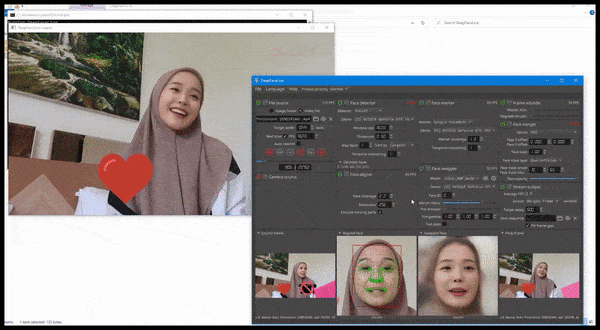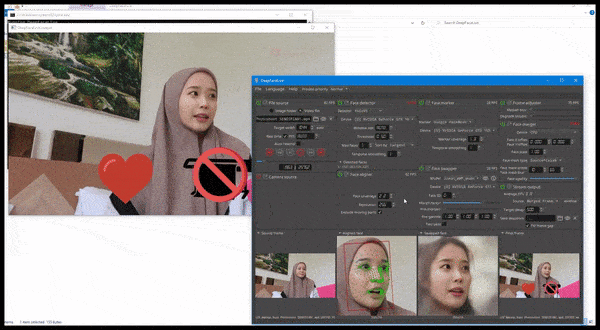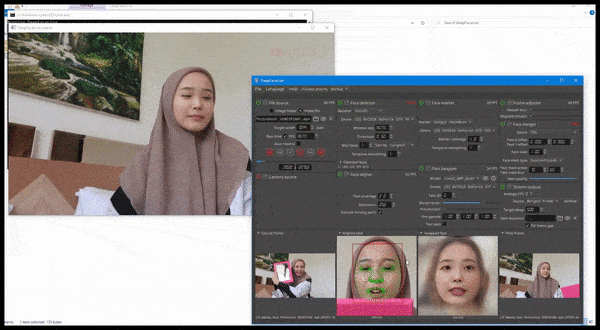
DeepFaceLive в действии: эта потоковая версия лучшего программного обеспечения для дипфейков DeepFaceLab может обеспечить контекстуальный реализм, представляя подделки в контексте ограниченного качества видео, с проблемами воспроизведения и другими повторяющимися артефактами соединения. Источник: https://www.youtube.com/watch?v=IL517EgYH8U
Встроенная деградация
Действительно, два самых популярных пакета дипфейков (оба получены из спорного исходного кода 2017 года) содержат компоненты, предназначенные для интеграции дипфейкового лица в контекст «исторического» или видео более низкого качества путем ухудшения качества сгенерированного лица. В DeepFaceLab, bicubic_degrade_power параметр выполняет это, и в обмен лицами, параметр «зернистость» в конфигурации Ffmpeg также помогает интегрировать фальшивое лицо, сохраняя зернистость во время кодирования*.

Параметр «зернистость» в FaceSwap способствует аутентичной интеграции в видеоконтент не HQ и устаревший контент, который может иметь эффекты зернистости пленки, которые в наши дни относительно редки.
Часто вместо полного и интегрированного дипфейкового видео дипфейкеры выводят изолированную серию файлов PNG с альфа-каналами, каждое изображение показывает только синтетический вывод лица, так что поток изображения может быть преобразован в видео на платформах с более сложными 'унижающие возможности эффектов, такие как Adobe After Effects, до того, как поддельные и настоящие элементы будут объединены для окончательного видео.
Помимо этих преднамеренных искажений, контент дипфейковых работ часто повторно сжимается либо алгоритмически (когда платформы социальных сетей стремятся сэкономить пропускную способность, создавая более легкие версии загрузок пользователей) на таких платформах, как YouTube и Facebook, либо путем повторной обработки исходной работы в анимированные GIF-файлы, разделы с подробными сведениями или другие разнообразные рабочие процессы, в которых первоначальный выпуск рассматривается как отправная точка, а затем вводится дополнительное сжатие.
Реалистичные контексты обнаружения дипфейков
Имея это в виду, в новой статье из Швейцарии предлагается пересмотреть методологию, лежащую в основе подходов к обнаружению дипфейков, путем обучения систем обнаружения изучению характеристик контента дипфейков, когда он представлен в преднамеренно ухудшенных контекстах.

Стохастическое увеличение данных, примененное к одному из наборов данных, используемых в новой статье, включает гауссов шум, гамма-коррекцию и размытие по Гауссу, а также артефакты сжатия JPEG. Источник: https://arxiv.org/pdf/2203.11807.pdf
В новой статье исследователи утверждают, что авангардные пакеты обнаружения дипфейков полагаются на нереалистичные исходные условия для контекста применяемых метрик, и что «ухудшенный» вывод дипфейков может упасть ниже минимального порога качества для обнаружения, даже если их реалистичные «шероховатый» контент может ввести зрителей в заблуждение из-за правильного внимания к контексту.
Исследователи внедрили новый процесс деградации данных «реального мира», который успешно улучшает обобщаемость ведущих детекторов дипфейков с лишь незначительной потерей точности по сравнению с исходными показателями обнаружения, полученными с помощью «чистых» данных. Они также предлагают новую систему оценки, которая может оценить надежность детекторов дипфейков в реальных условиях, что подтверждается обширными исследованиями абляции.
Ассоциация бумаги называется Новый подход к улучшению обнаружения дипфейков на основе обучения в реальных условиях, и исходит от исследователей из Группы обработки мультимедийных сигналов (MMSPG) и Федеральной политехнической школы Лозанны (EPFL), базирующихся в Лозанне.
Полезная путаница
Предыдущие попытки включить ухудшенные выходные данные в подходы к обнаружению дипфейков включают Смешанная нейронная сеть, предложение 2018 года от MIT и FAIR, и авгмикс, сотрудничество 2020 года между DeepMind и Google, оба метода увеличения данных, которые пытаются «запутать» учебный материал таким образом, чтобы способствовать обобщению.
Исследователи новой работы также отмечают предшествующий исследования которые применили гауссовский шум и артефакты сжатия к обучающим данным, чтобы установить границы взаимосвязи между производным признаком и шумом, в который он встроен.
Новое исследование предлагает конвейер, который имитирует скомпрометированные условия как процесса получения изображения, так и сжатия, а также различные другие алгоритмы, которые могут еще больше ухудшить качество вывода изображения в процессе распространения. Включив этот реальный рабочий процесс в оценочную структуру, можно получить обучающие данные для детекторов дипфейков, которые более устойчивы к артефактам.

Концептуальная логика и рабочий процесс для нового подхода.
Процесс деградации был применен к двум популярным и успешным наборам данных, используемым для обнаружения дипфейков: FaceForensics ++ и Знаменитость-DFv2. Кроме того, ведущие фреймворки для обнаружения дипфейков Капсула-судебная экспертиза и XceptionNet были обучены на фальсифицированных версиях двух наборов данных.
Детекторы обучались с помощью оптимизатора Adam на 25 и 10 эпох соответственно. Для преобразования набора данных из каждого обучающего видео были случайным образом выбраны 100 кадров, из которых 32 кадра были извлечены для тестирования до добавления процессов деградации.
Искажения, рассматриваемые для рабочего процесса, были шум, где гауссовский шум с нулевым средним применялся на шести различных уровнях; изменение размера, чтобы имитировать уменьшенное разрешение типичной видеозаписи на открытом воздухе, которая может обычно влияют детекторы; (сила), где к данным применялись различные уровни сжатия JPEG; сглаживающий, где для фреймворка оцениваются три типичных сглаживающих фильтра, используемых при «шумоподавлении»; усиление, где настраивались контрастность и яркость; и комбинации, где любое сочетание трех вышеупомянутых методов одновременно применялось к одному изображению.
Тестирование и результаты
При тестировании данных исследователи использовали три показателя: точность (ACC); Площадь под кривой рабочей характеристики приемника (ППК); а также F1-оценка.
Исследователи проверили стандартно обученные версии двух детекторов дипфейков на фальсифицированных данных и обнаружили, что в них отсутствуют:
«В целом, большинство реалистичных искажений и обработки чрезвычайно вредны для обычно обученных детекторов дипфейков, основанных на обучении. Например, метод Capsule-Forensics показывает очень высокие оценки AUC как на несжатом тестовом наборе FFpp, так и на тестовом наборе Celeb-DFv2 после обучения на соответствующих наборах данных, но затем страдает от резкого падения производительности на модифицированных данных из нашей системы оценки. Аналогичные тенденции наблюдались с детектором XceptionNet».
Напротив, производительность двух детекторов была заметно улучшена за счет обучения на преобразованных данных, и каждый детектор теперь более способен обнаруживать невидимые вводящие в заблуждение носители.
«Схема увеличения данных значительно повышает надежность двух детекторов, и в то же время они по-прежнему сохраняют высокую производительность на исходных неизмененных данных».

Сравнение производительности необработанных и дополненных наборов данных, используемых в двух детекторах дипфейков, оцениваемых в исследовании.
В статье делается вывод:
«Существующие методы обнаружения предназначены для достижения максимально возможной производительности на определенных тестах. Это часто приводит к тому, что способность к обобщению приносится в жертву более реалистичным сценариям. В этой статье предлагается тщательно продуманная схема увеличения данных, основанная на естественном процессе деградации изображения.
«Обширные эксперименты показывают, что простой, но эффективный метод значительно повышает устойчивость модели к различным реалистичным искажениям и операциям обработки в типичных рабочих процессах обработки изображений».
* Соответствие зернистости сгенерированного лица является функцией передачи стиля в процессе преобразования.
Впервые опубликовано 29 марта 2022 г. Обновлено в 8:33 по восточному поясному времени, чтобы прояснить использование зерна в Ffmpeg.















