Cibersegurança
Por que os ataques de imagem adversários não são brincadeira
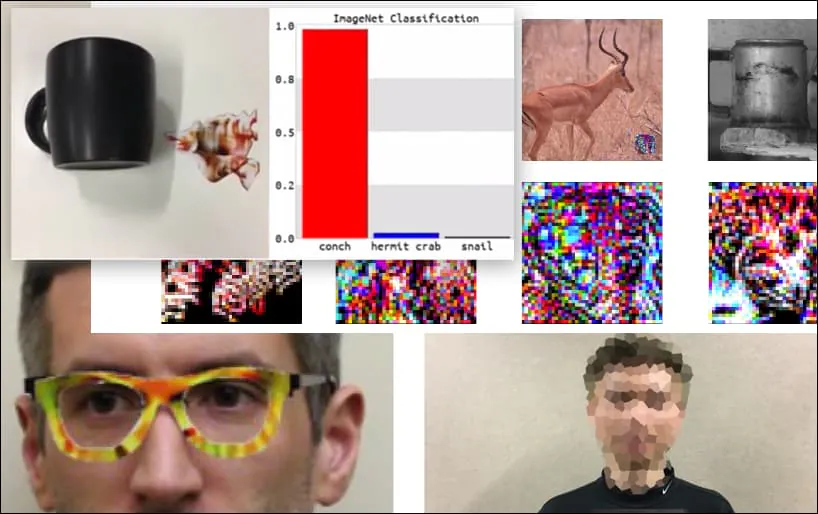
Atacar sistemas de reconhecimento de imagens com imagens adversárias cuidadosamente elaboradas tem sido considerado uma demonstração divertida, mas trivial, nos últimos cinco anos. No entanto, uma nova pesquisa da Austrália sugere que o uso casual de conjuntos de dados de imagem altamente populares para projetos comerciais de IA pode criar um novo problema de segurança duradouro.
Há alguns anos, um grupo de acadêmicos da Universidade de Adelaide vem tentando explicar algo realmente importante sobre o futuro dos sistemas de reconhecimento de imagens baseados em IA.
É algo que seria difícil (e muito caro) consertar agora, e que seria inconcebivelmente caro para remediar uma vez que as tendências atuais em pesquisas de reconhecimento de imagens tenham sido totalmente desenvolvidas em implantações comercializadas e industrializadas em 5-10 anos.
Antes de entrarmos nisso, vamos dar uma olhada em uma flor sendo classificada como o presidente Barack Obama, de um dos seis vídeos que a equipe publicou na página do projeto:
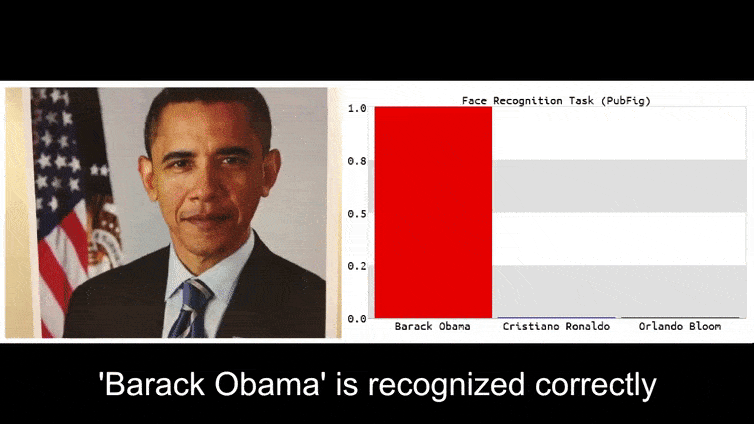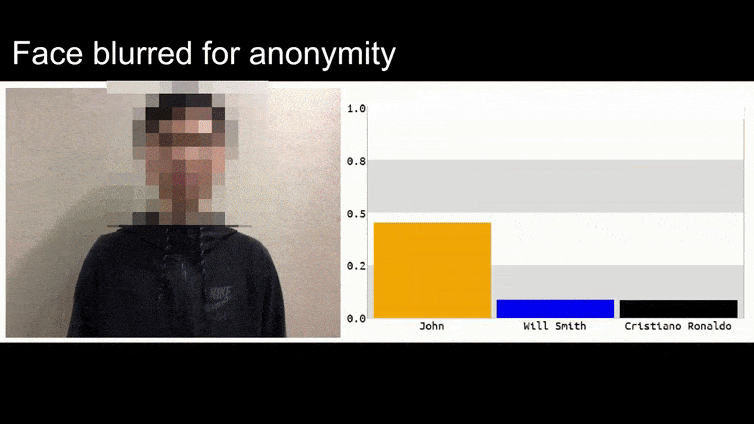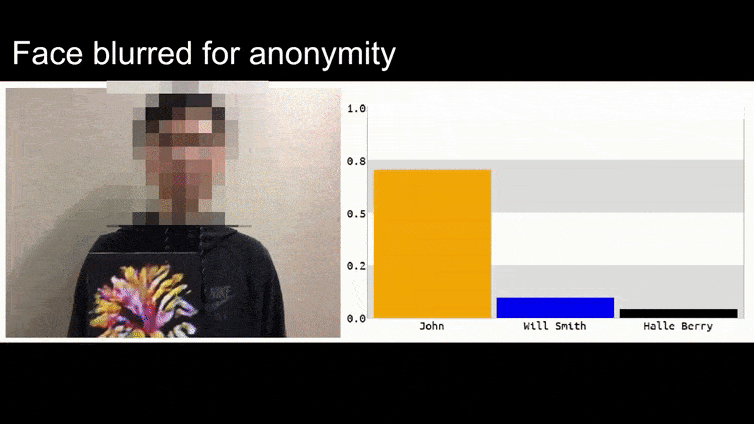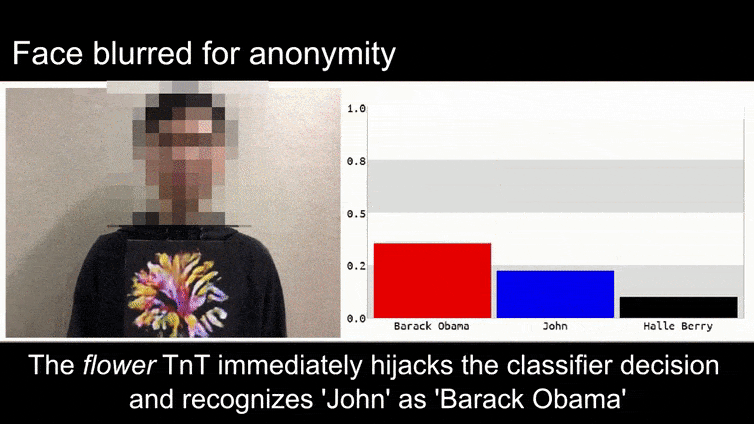
Fonte: https://www.youtube.com/watch?v=Klepca1Ny3c
Na imagem acima, um sistema de reconhecimento facial que claramente sabe como reconhecer Barack Obama é enganado com 80% de certeza de que um homem anônimo segurando uma imagem adversária impressa de uma flor também é Barack Obama. O sistema não se importa que a “falsa face” esteja no peito do sujeito, em vez de nos ombros.
Embora seja impressionante que os pesquisadores tenham conseguido realizar esse tipo de captura de identidade gerando uma imagem coerente (uma flor) em vez do usual ruído aleatório, parece que explorações engraçadas como essa surgem regularmente em pesquisas de segurança sobre visão computacional. Por exemplo, aqueles óculos com padrões estranhos que conseguiram enganar o reconhecimento facial em 2016, ou imagens adversárias especialmente elaboradas que tentam reescrever placas de trânsito.
Se você estiver interessado, o modelo de rede neural convolucional (CNN) sendo atacado no exemplo acima é o VGGFace (VGG-16), treinado no conjunto de dados PubFig da Universidade de Columbia. Outras amostras de ataques desenvolvidas pelos pesquisadores usaram recursos diferentes em combinações diferentes.

Um teclado é reclassificado como um búzio, em um modelo WideResNet50 no ImageNet. Os pesquisadores também garantiram que o modelo não tenha viés para búzios. Veja o vídeo completo para demonstrações estendidas e adicionais em https://www.youtube.com/watch?v=dhTTjjrxIcU
Reconhecimento de imagem como um vetor de ataque emergente
Os muitos ataques impressionantes que os pesquisadores esboçam e ilustram não são críticas a conjuntos de dados ou arquiteturas de aprendizado de máquina específicas que os utilizam. Nem podem ser facilmente defendidos contra mudanças de conjuntos de dados ou modelos, retreinamento de modelos ou qualquer outra “solução simples” que cause que práticos de ML zombem de demonstrações esporádicas desse tipo de truque.
Em vez disso, as explorações da equipe de Adelaide exemplificam uma fraqueza central na arquitetura atual de desenvolvimento de IA de reconhecimento de imagens; uma fraqueza que poderia expor muitos sistemas de reconhecimento de imagens futuros à manipulação fácil por atacantes e colocar quaisquer medidas defensivas subsequentes em desvantagem.
Imagine as últimas imagens de ataques adversários (como a flor acima) sendo adicionadas como “exploits de zero dia” aos sistemas de segurança do futuro, assim como os frameworks atuais de antivírus e anti-malware atualizam suas definições de vírus todos os dias.
O potencial para novos ataques de imagens adversárias seria inesgotável, porque a arquitetura de base do sistema não antecipou problemas downstream, como ocorreu com a internet, o Bug do Milênio e a Torre Inclinada de Pisa.
De que forma, então, estamos preparando o cenário para isso?
Obtendo os dados para um ataque
Imagens adversárias, como o exemplo de “flor” acima, são geradas tendo acesso aos conjuntos de dados que treinaram os modelos de computador. Você não precisa de acesso “privilegiado” aos dados de treinamento (ou arquiteturas de modelo), desde que os conjuntos de dados mais populares (e muitos modelos treinados) estejam amplamente disponíveis em uma torrente robusta e constantemente atualizada.
Por exemplo, o gigante da visão computacional, o ImageNet, está disponível para torrent em todas as suas muitas iterações, contornando suas restrições habituais restritas, e tornando disponíveis elementos secundários cruciais, como conjuntos de validação.

Fonte: https://academictorrents.com
Se você tiver os dados, pode (como observam os pesquisadores de Adelaide) efetivamente “reverter” qualquer conjunto de dados popular, como CityScapes ou CIFAR.
No caso do PubFig, o conjunto de dados que permitiu a “flor de Obama” no exemplo anterior, a Universidade de Columbia abordou uma tendência crescente em questões de direitos autorais em torno da redistribuição de conjuntos de dados de imagem, instruindo os pesquisadores sobre como reproduzir o conjunto de dados por meio de links curados, em vez de tornar a compilação diretamente disponível, observando ‘Isso parece ser o caminho como outros grandes bancos de dados baseados na web parecem estar evoluindo’.
Na maioria dos casos, isso não é necessário: o Kaggle estima que os dez conjuntos de dados de imagem mais populares em visão computacional são: CIFAR-10 e CIFAR-100 (ambos diretamente baixáveis); CALTECH-101 e 256 (ambos disponíveis e atualmente disponíveis como torrents); MNIST (oficialmente disponível, também em torrents); ImageNet (veja acima); Pascal VOC (disponível, também em torrents); MS COCO (disponível, e em torrents); Sports-1M (disponível); e YouTube-8M (disponível).
Essa disponibilidade também é representativa da gama mais ampla de conjuntos de dados de visão computacional disponíveis, desde que a obscuridade é a morte em uma cultura de desenvolvimento de código aberto “publique ou pereça”.
Em qualquer caso, a escassez de conjuntos de dados gerenciáveis, o alto custo do desenvolvimento de conjuntos de imagens, a dependência de “velhos favoritos” e a tendência a simplesmente adaptar conjuntos de dados mais antigos todos exacerbam o problema esboçado no novo artigo de Adelaide.
Críticas típicas de métodos de ataque de imagem adversária
A crítica mais frequente e persistente dos engenheiros de aprendizado de máquina contra a eficácia da última técnica de ataque de imagem adversária é que o ataque é específico para um conjunto de dados particular, um modelo particular ou ambos; que não é “generalizável” para outros sistemas; e, consequentemente, representa apenas uma ameaça trivial.
A segunda crítica mais frequente é que o ataque de imagem adversária é ‘caixa branca’, significando que você precisaria de acesso direto ao ambiente de treinamento ou dados. Isso é de fato um cenário improvável, na maioria dos casos – por exemplo, se você quisesse explorar o processo de treinamento para os sistemas de reconhecimento facial da polícia metropolitana de Londres, você teria que hackear seu caminho para NEC, seja com uma console ou um machado.
O ‘DNA’ de longo prazo dos conjuntos de dados de visão computacional populares
Em relação à primeira crítica, devemos considerar não apenas que um punhado de conjuntos de dados de visão computacional dominam a indústria por setor ano a ano (ou seja, ImageNet para vários tipos de objetos, CityScapes para cenas de direção e FFHQ para reconhecimento facial); mas também que, como dados de imagem simples anotados, eles são “independentes de plataforma” e altamente transferíveis.
Dependendo de suas capacidades, qualquer arquitetura de treinamento de visão computacional encontrará algumas características de objetos e classes no conjunto de dados ImageNet. Algumas arquiteturas podem encontrar mais características do que outras, ou fazer conexões mais úteis do que outras, mas todas devem encontrar pelo menos as características de nível mais alto:

Dados do ImageNet, com o número mínimo de identificações corretas – características de ‘nível alto’.
São essas características “de nível alto” que distinguem e “imprimem digitalmente” um conjunto de dados, e que são os “ganchos” confiáveis para pendurar uma metodologia de ataque de imagem adversária de longo prazo que possa atravessar diferentes sistemas e crescer em tandem com o “velho” conjunto de dados à medida que este é perpetuado em novas pesquisas e produtos.
Uma arquitetura mais sofisticada produzirá identificações, características e classes mais precisas e granulares:

No entanto, quanto mais um gerador de ataque adversário confiar nesses recursos mais baixos (ou seja, “Jovem Macho Caucasiano” em vez de “Rosto”), menos eficaz será em sistemas de crossover ou arquiteturas posteriores que usam versões diferentes do conjunto de dados original – como um subconjunto ou conjunto filtrado, onde muitas das imagens originais do conjunto de dados completo não estão presentes:

Ataques adversários em modelos ‘zerados’, pré-treinados
E quanto aos casos em que você simplesmente baixa um modelo pré-treinado que foi originalmente treinado em um conjunto de dados altamente popular e fornece novos dados?
O modelo já foi treinado no ImageNet, por exemplo, e tudo o que resta são os pesos, que podem ter levado semanas ou meses para treinar e agora estão prontos para ajudá-lo a identificar objetos semelhantes aos que existiam nos dados originais (agora ausentes).

Com os dados originais removidos da arquitetura de treinamento, o que resta é a ‘predisposição’ do modelo para classificar objetos da maneira como ele originalmente aprendeu a fazer, o que essencialmente fará com que muitas das ‘assinaturas’ originais se reformem e se tornem vulneráveis novamente aos mesmos métodos de ataque de imagem adversária.
Esses pesos são valiosos. Sem os dados ou os pesos, você basicamente tem uma arquitetura vazia sem dados. Você terá que treinar novamente, ao grande custo de tempo e recursos de computação, assim como os autores originais fizeram (provavelmente em hardware mais poderoso e com um orçamento maior do que o seu).
O problema é que os pesos já estão bem formados e resilientes. Embora eles adaptem um pouco no treinamento, eles vão se comportar de forma semelhante em seus novos dados como fizeram nos dados originais, produzindo características de assinatura que um sistema de ataque adversário pode chavear novamente.
No longo prazo, isso também preserva o “DNA” dos conjuntos de dados de visão computacional que têm doze ou mais anos e podem ter passado por uma evolução notável desde esforços de código aberto até implantações comercializadas – mesmo onde os dados de treinamento originais foram completamente descartados no início do projeto. Algumas dessas implantações comerciais podem não ocorrer por anos ainda.
Nenhuma caixa branca necessária
Em relação à segunda crítica comum dos sistemas de ataque de imagem adversária, os autores do novo artigo descobriram que sua capacidade de enganar sistemas de reconhecimento com imagens elaboradas é altamente transferível em várias arquiteturas.
Enquanto observam que seu método “Universal NaTuralistic adversarial paTches” (TnT) é o primeiro a usar imagens reconhecíveis (em vez de ruído de perturbação aleatório) para enganar sistemas de reconhecimento de imagens, os autores também afirmam:
‘[TnTs] são eficazes contra vários classificadores de estado da arte, desde o amplamente utilizado WideResNet50 na tarefa de Reconhecimento Visual em Grande Escala do conjunto de dados ImageNet ao VGG-face models na tarefa de reconhecimento facial do conjunto de dados PubFig em ataques direcionados e indirecionados.
‘TnTs podem possuir: i) o naturalismo alcançável [com] gatilhos usados em métodos de ataque Trojan; e ii) a generalização e transferibilidade de exemplos adversários para outras redes.
‘Isso levanta preocupações de segurança e segurança com relação a DNNs já implantados, bem como implantações futuras de DNNs, onde os atacantes podem usar patches de objetos naturais e imperceptíveis para desviar sistemas de rede neural sem alterar o modelo e arriscar a descoberta.’
Os autores sugerem que contramedidas convencionais, como degradar a Clean Acc. de uma rede, poderiam teoricamente fornecer alguma defesa contra patches TnT, mas que ‘TnTs ainda podem contornar essa defesa SOTA comprovada com a maioria dos sistemas defensores alcançando 0% de Robustez’.
Possíveis outras soluções incluem aprendizado federado, onde a proveniência das imagens contribuintes é protegida, e novas abordagens que possam diretamente “criptografar” dados no momento do treinamento, como uma recentemente sugerida pela Universidade de Aeronáutica e Astronautica de Nanjing.
Mesmo nesses casos, seria importante treinar em dados de imagem novos e genuínos – agora as imagens e anotações associadas nos pequenos conjuntos de dados de visão computacional mais populares estão tão incorporados nos ciclos de desenvolvimento em todo o mundo que se assemelham mais a software do que a dados; software que muitas vezes não foi notavelmente atualizado em anos.
Conclusão
Os ataques de imagem adversária estão sendo tornados possíveis não apenas por práticas de código aberto de aprendizado de máquina, mas também por uma cultura de desenvolvimento de IA corporativa que é motivada a reutilizar conjuntos de dados de visão computacional bem estabelecidos por várias razões: eles já provaram ser eficazes; são muito mais baratos do que “começar do zero”; e são mantidos e atualizados por mentes e organizações vanguardas em academia e indústria, em níveis de financiamento e pessoal que seriam difíceis para uma única empresa replicar.
Além disso, em muitos casos onde os dados não são originais (ao contrário do CityScapes), as imagens foram coletadas antes de controvérsias recentes sobre práticas de coleta e privacidade de dados, deixando esses conjuntos de dados mais antigos em uma espécie de purgatório semi-legal que pode parecer um “porto seguro”, do ponto de vista de uma empresa.
TnT Attacks! Universal Naturalistic Adversarial Patches Against Deep Neural Network Systems é coautoria de Bao Gia Doan, Minhui Xue, Ehsan Abbasnejad, Damith C. Ranasinghe da Universidade de Adelaide, juntamente com Shiqing Ma do Departamento de Ciência da Computação da Universidade de Rutgers.
Atualizado em 1º de dezembro de 2021, 7:06h GMT+2 – corrigido erro de digitação.












