IA 101
O que é o Teorema de Bayes?
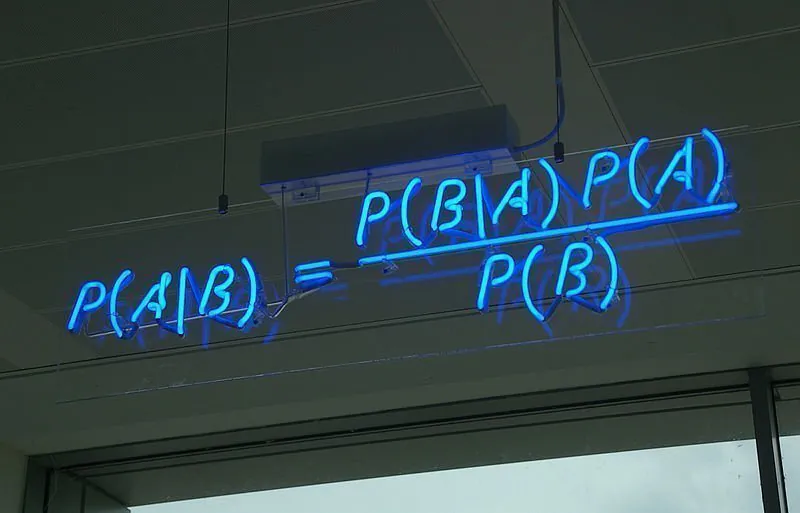
Se você está aprendendo sobre ciência de dados ou aprendizado de máquina, há uma boa chance de que você já tenha ouvido o termo “Teorema de Bayes” antes, ou um “classificador de Bayes”. Esses conceitos podem ser um pouco confusos, especialmente se você não estiver acostumado a pensar em probabilidade de uma perspectiva tradicional, frequentista. Este artigo tentará explicar os princípios por trás do Teorema de Bayes e como ele é usado no aprendizado de máquina.
O que é o Teorema de Bayes?
O Teorema de Bayes é um método de cálculo de probabilidade condicional. O método tradicional de calcular probabilidade condicional (a probabilidade de que um evento ocorra dado o ocorrer de um evento diferente) é usar a fórmula de probabilidade condicional, calculando a probabilidade conjunta do evento um e do evento dois ocorrendo ao mesmo tempo, e então dividindo por da probabilidade do evento dois ocorrer. No entanto, a probabilidade condicional também pode ser calculada de uma maneira ligeiramente diferente usando o Teorema de Bayes.
Quando calculamos a probabilidade condicional com o teorema de Bayes, usamos os seguintes passos:
- Determinar a probabilidade da condição B ser verdadeira, supondo que a condição A seja verdadeira.
- Determinar a probabilidade do evento A ser verdadeiro.
- Multiplicar as duas probabilidades juntas.
- Dividir pela probabilidade do evento B ocorrer.
Isso significa que a fórmula para o Teorema de Bayes pode ser expressa assim:
P(A|B) = P(B|A)*P(A) / P(B)
Calcular a probabilidade condicional assim é especialmente útil quando a probabilidade condicional reversa pode ser facilmente calculada, ou quando calcular a probabilidade conjunta seria muito desafiador.
Exemplo do Teorema de Bayes
Isso pode ser mais fácil de interpretar se passarmos algum tempo olhando para um exemplo de como você aplicaria o raciocínio bayesiano e o Teorema de Bayes. Vamos supor que você estivesse jogando um jogo simples onde vários participantes lhe contam uma história e você tem que determinar quem dos participantes está mentindo para você. Vamos preencher a equação para o Teorema de Bayes com as variáveis nesse cenário hipotético.
Estamos tentando prever se cada indivíduo no jogo está mentindo ou dizendo a verdade, então, se houver três jogadores além de você, as variáveis categóricas podem ser expressas como A1, A2 e A3. A evidência de suas mentiras/verdades é seu comportamento. Como quando se joga pôquer, você procuraria por certos “tells” de que uma pessoa está mentindo e usaria essas informações para informar sua suposição. Ou se você tivesse permissão para questioná-los, seria qualquer evidência de que a história deles não bate. Podemos representar a evidência de que uma pessoa está mentindo como B.
Para ser claro, estamos tentando prever a Probabilidade(A está mentindo/dizendo a verdade|dada a evidência de seu comportamento). Para fazer isso, gostaríamos de descobrir a probabilidade de B dado A, ou a probabilidade de que o comportamento ocorra dado que a pessoa está realmente mentindo ou dizendo a verdade. Você está tentando determinar sob quais condições o comportamento que está vendo faria mais sentido. Se houver três comportamentos que você está testemunhando, você faria o cálculo para cada comportamento. Por exemplo, P(B1, B2, B3 * A). Você faria isso para cada ocorrência de A/para cada pessoa no jogo, além de você. Essa é essa parte da equação acima:
P(B1, B2, B3,|A) * P|A
Finalmente, dividimos isso pela probabilidade de B.
Se recebêssemos alguma evidência sobre as probabilidades reais nessa equação, recriaríamos nosso modelo de probabilidade, levando em conta as novas evidências. Isso é chamado de atualizar nossos priores, pois atualizamos nossas suposições sobre a probabilidade a priori dos eventos observados.
Aplicações de Aprendizado de Máquina para o Teorema de Bayes
O uso mais comum do Teorema de Bayes quando se trata de aprendizado de máquina é na forma do algoritmo Naive Bayes.
Naive Bayes é usado para a classificação de conjuntos de dados binários e multiclasse, Naive Bayes recebe seu nome porque os valores atribuídos às evidências/atributos – Bs em P(B1, B2, B3 * A) – são assumidos como independentes entre si. Assume-se que esses atributos não afetam um ao outro para simplificar o modelo e tornar os cálculos possíveis, em vez de tentar a tarefa complexa de calcular as relações entre cada um dos atributos. Apesar desse modelo simplificado, Naive Bayes tende a se sair muito bem como um algoritmo de classificação, mesmo quando essa suposição provavelmente não é verdadeira (o que é a maior parte do tempo).
Também existem variantes comuns do classificador Naive Bayes, como Multinomial Naive Bayes, Bernoulli Naive Bayes e Gaussian Naive Bayes.
Algoritmos Multinomial Naive Bayes são frequentemente usados para classificar documentos, pois é eficaz na interpretação da frequência de palavras dentro de um documento.
Algoritmos Bernoulli Naive Bayes operam de forma semelhante à Multinomial Naive Bayes, mas as previsões renderizadas pelo algoritmo são booleanas. Isso significa que, ao prever uma classe, os valores serão binários, sim ou não. No domínio da classificação de texto, um algoritmo Bernoulli Naive Bayes atribuiria os parâmetros sim ou não com base na presença ou ausência de uma palavra no documento de texto.
Se o valor dos preditores/recursos não for discreto, mas for contínuo, Gaussian Naive Bayes pode ser usado. Assume-se que os valores dos recursos contínuos foram amostrados a partir de uma distribuição gaussiana.












