Inteligência artificial
Treinamento de Modelos de Visão Computacional com Ruído Aleatório em vez de Imagens Reais

Pesquisadores do Laboratório de Ciência da Computação e Inteligência Artificial do MIT (CSAIL) experimentaram o uso de imagens de ruído aleatório em conjuntos de dados de visão computacional para treinar modelos de visão computacional, e descobriram que, em vez de produzir lixo, o método é surpreendentemente eficaz:

Modelos gerativos do experimento, classificados por desempenho. Fonte: https://openreview.net/pdf?id=RQUl8gZnN7O
Alimentar o que aparenta ser ‘lixo visual’ em arquiteturas de visão computacional populares não deve resultar nesse tipo de desempenho. À direita da imagem acima, as colunas pretas representam pontuações de precisão (no Imagenet-100) para quatro conjuntos de dados ‘reais’. Embora os conjuntos de dados de ‘ruído aleatório’ que os precedem (ilustrados em várias cores, veja índice no canto superior esquerdo) não possam igualar isso, eles estão quase todos dentro de limites respeitáveis de precisão (linhas tracejadas vermelhas).
Nesse sentido, ‘precisão’ não significa que um resultado necessariamente se pareça com um rosto, uma igreja, uma pizza ou qualquer outro domínio particular para o qual você possa estar interessado em criar um sistema de síntese de imagens, como uma Rede Adversária Gerativa ou uma estrutura de codificador/decodificador.
Em vez disso, significa que os modelos do CSAIL derivaram ‘verdades’ centrais amplamente aplicáveis a partir de dados de imagem tão aparentemente não estruturados que não deveriam ser capazes de fornecê-los.
Diversidade vs. Naturalismo
Esses resultados também não podem ser atribuídos a sobreajuste: uma discussão animada discussão entre os autores e revisores no Open Review revela que misturar diferentes conteúdos de conjuntos de dados visualmente diversos (como ‘folhas mortas’, ‘fractais’ e ‘ruído procedural’ – veja imagem abaixo) em um conjunto de dados de treinamento melhora a precisão nesses experimentos.
Isso sugere (e é um pouco de uma noção revolucionária) um novo tipo de ‘subajuste’, onde ‘diversidade’ supera ‘naturalismo’.
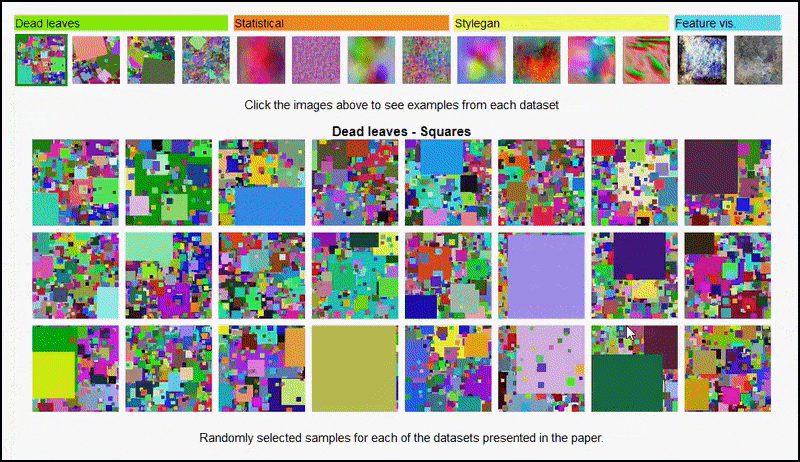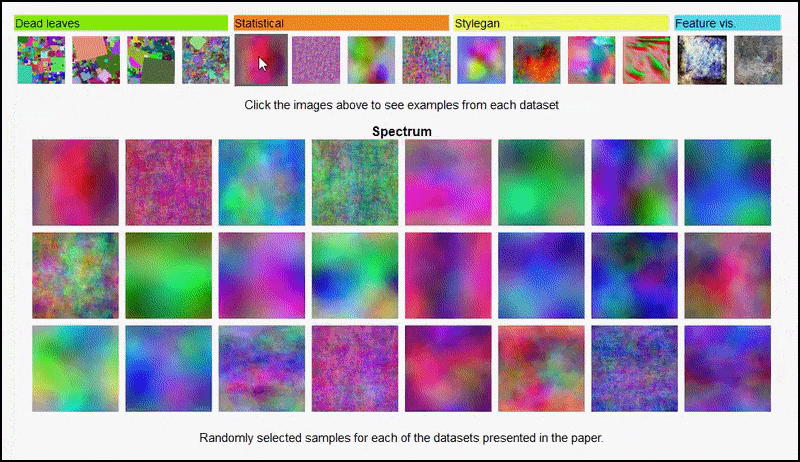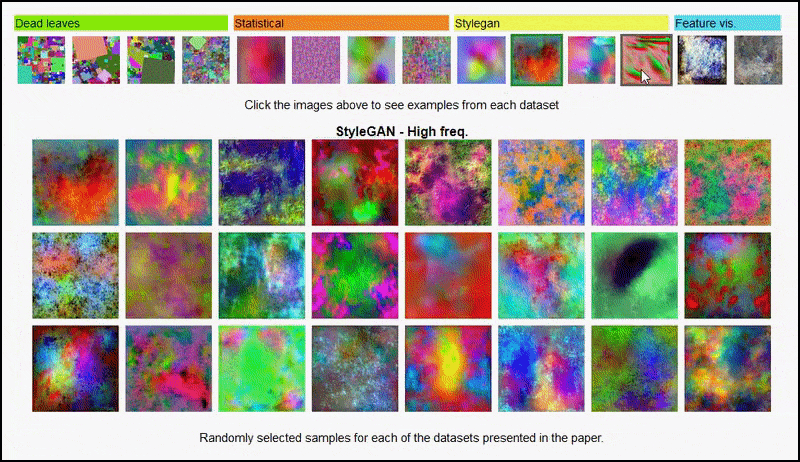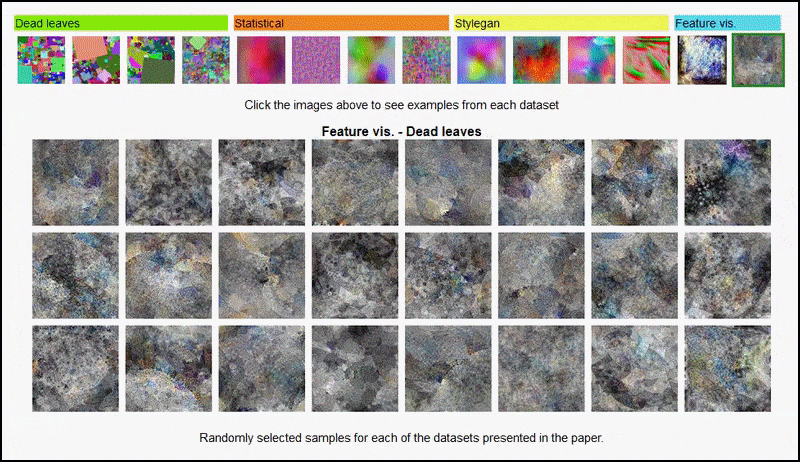
A página do projeto permite visualizar interativamente os diferentes tipos de conjuntos de dados de imagens aleatórias usados no experimento. Fonte: https://mbaradad.github.io/learning_with_noise/
Os resultados obtidos pelos pesquisadores questionam a relação fundamental entre redes neurais baseadas em imagens e as ‘imagens do mundo real’ que são jogadas nelas em volumes cada vez maiores a cada ano, e implicam que a necessidade de obter, curar e manipular conjuntos de dados de imagens em larga escala pode eventualmente se tornar redundante. Os autores afirmam:
‘Os sistemas de visão atuais são treinados em conjuntos de dados enormes, e esses conjuntos de dados vêm com custos: a curação é cara, eles herdam vieses humanos e há preocupações sobre privacidade e direitos de uso. Para contrariar esses custos, surgiu um interesse em aprender a partir de fontes de dados mais baratas, como imagens não rotuladas.’
‘Neste artigo, vamos um passo além e perguntamos se podemos nos livrar completamente de conjuntos de dados de imagens reais, aprendendo a partir de processos de ruído procedural.’
Os pesquisadores sugerem que a atual safra de arquiteturas de aprendizado de máquina pode estar inferindo algo muito mais fundamental (ou, pelo menos, inesperado) a partir de imagens do que se pensava anteriormente, e que ‘imagens sem sentido’ podem potencialmente transmitir muito desse conhecimento de forma muito mais barata, mesmo com o possível uso de dados sintéticos ad hoc, por meio de arquiteturas de geração de conjuntos de dados que geram imagens aleatórias durante o treinamento:
‘Nós identificamos duas propriedades-chave que tornam os dados sintéticos bons para treinar sistemas de visão: 1) naturalismo, 2) diversidade. Interessantemente, os dados mais naturalistas nem sempre são os melhores, pois o naturalismo pode vir com o custo da diversidade.’
‘O fato de que os dados naturalistas ajudam pode não ser surpreendente, e sugere que, de fato, os grandes conjuntos de dados reais têm valor. No entanto, descobrimos que o que é crucial não é que os dados sejam reais, mas que sejam naturalistas, ou seja, devem capturar certas propriedades estruturais dos dados reais.’
‘Muitas dessas propriedades podem ser capturadas em modelos de ruído simples.’

Visualizações de recursos resultantes de um codificador derivado do AlexNet em alguns dos vários conjuntos de dados de ‘imagens aleatórias’ usados pelos autores, cobrindo a 3ª e 5ª (final) camada convolucional. A metodologia usada aqui segue a estabelecida na pesquisa do Google AI de 2017.
O artigo, apresentado na 35ª Conferência sobre Processamento de Informações Neurais (NeurIPS 2021) em Sydney, é intitulado Aprendendo a Ver Olhando para o Ruído, e vem de seis pesquisadores do CSAIL, com contribuição igual.
O trabalho foi recomendado por consenso para uma seleção de destaque no NeurIPS 2021, com comentaristas peer caracterizando o artigo como ‘uma quebra científica’ que abre um ‘grande área de estudo’, mesmo que levante tantas questões quanto respostas.
No artigo, os autores concluem:
‘Nós mostramos que, quando projetados usando resultados de pesquisas anteriores sobre estatísticas de imagens naturais, esses conjuntos de dados podem treinar com sucesso representações visuais. Esperamos que este artigo motive o estudo de novos modelos gerativos capazes de produzir ruído estruturado que atinja um desempenho ainda maior quando usado em uma variedade de tarefas visuais.’
‘Será que seria possível igualar o desempenho obtido com o pré-treinamento do ImageNet? Talvez, na ausência de um grande conjunto de treinamento específico para uma tarefa particular, o melhor pré-treinamento não seja usar um conjunto de dados real padrão como o ImageNet.’












