
Inteligência artificial
InstructIR: restauração de imagem de alta qualidade seguindo instruções humanas

Uma imagem pode transmitir muita coisa, mas também pode ser prejudicada por vários problemas, como desfoque de movimento, neblina, ruído e baixa faixa dinâmica. Esses problemas, comumente chamados de degradações na visão computacional de baixo nível, podem surgir de condições ambientais difíceis, como calor ou chuva, ou de limitações da própria câmera. A restauração de imagens representa um desafio central na visão computacional, buscando recuperar uma imagem limpa e de alta qualidade de uma que exiba tais degradações. A restauração de imagens é complexa porque pode haver várias soluções para restaurar qualquer imagem. Algumas abordagens visam degradações específicas, como a redução de ruído ou a remoção de desfoque ou neblina.
Embora estes métodos possam produzir bons resultados para questões específicas, muitas vezes têm dificuldade em generalizar para diferentes tipos de degradação. Muitas estruturas empregam uma rede neural genérica para uma ampla gama de tarefas de restauração de imagens, mas cada uma dessas redes é treinada separadamente. A necessidade de modelos diferentes para cada tipo de degradação torna esta abordagem computacionalmente cara e demorada, levando ao foco em modelos de restauração All-In-One em desenvolvimentos recentes. Esses modelos utilizam um modelo único de restauração cega profunda que aborda vários níveis e tipos de degradação, geralmente empregando prompts ou vetores de orientação específicos de degradação para melhorar o desempenho. Embora os modelos All-In-One normalmente apresentem resultados promissores, eles ainda enfrentam desafios com problemas inversos.
O InstructIR representa uma abordagem inovadora na área, sendo o primeiro restauração de imagem estrutura projetada para guiar o modelo de restauração por meio de instruções escritas por humanos. Ele pode processar prompts de linguagem natural para recuperar imagens de alta qualidade de imagens degradadas, considerando vários tipos de degradação. O InstructIR estabelece um novo padrão de desempenho para um amplo espectro de tarefas de restauração de imagens, incluindo remoção de drenagem, remoção de ruído, desembaçamento, desfoque e aprimoramento de imagens com pouca luz.
Este artigo tem como objetivo cobrir o framework InstructIR em profundidade, e exploramos o mecanismo, a metodologia, a arquitetura do framework juntamente com sua comparação com frameworks de geração de imagens e vídeos de última geração. Então vamos começar.
InstructIR: Restauração de imagem de alta qualidade
A restauração de imagens é um problema fundamental em visão computacional, pois visa recuperar uma imagem limpa de alta qualidade a partir de uma imagem que apresenta degradações. Na visão computacional de baixo nível, Degradações é um termo usado para representar efeitos desagradáveis observados em uma imagem, como desfoque de movimento, neblina, ruído, baixa faixa dinâmica e muito mais. A razão pela qual a restauração de imagens é um desafio inverso complexo é porque pode haver múltiplas soluções diferentes para restaurar qualquer imagem. Algumas estruturas se concentram em degradações específicas, como reduzir o ruído da instância ou eliminar o ruído da imagem, enquanto outras podem se concentrar mais na remoção de desfoque ou desfoque, ou na eliminação de neblina ou desembaçamento.
Os métodos recentes de aprendizagem profunda têm apresentado um desempenho mais forte e consistente quando comparados aos métodos tradicionais de restauração de imagens. Esses modelos de restauração de imagens de aprendizagem profunda propõem o uso de redes neurais baseadas em Transformadores e Redes Neurais Convolucionais. Esses modelos podem ser treinados de forma independente para diversas tarefas de restauração de imagens e também possuem a capacidade de capturar interações de recursos locais e globais e aprimorá-las, resultando em desempenho satisfatório e consistente. Embora alguns destes métodos possam funcionar adequadamente para tipos específicos de degradação, eles normalmente não extrapolam bem para diferentes tipos de degradação. Além disso, embora muitas estruturas existentes utilizem a mesma rede neural para uma infinidade de tarefas de restauração de imagens, cada formulação de rede neural é treinada separadamente. Portanto, é óbvio que empregar um modelo neural separado para cada degradação concebível é impraticável e demorado, razão pela qual as estruturas recentes de restauração de imagens se concentraram em proxies de restauração All-In-One.
Modelos de restauração de imagem All-In-One ou Multi-degradação ou Multitarefa estão ganhando popularidade no campo da visão computacional, uma vez que são capazes de restaurar vários tipos e níveis de degradações em uma imagem sem a necessidade de treinar os modelos independentemente para cada degradação. . Os modelos de restauração de imagem All-In-One usam um único modelo de restauração de imagem cega profunda para lidar com diferentes tipos e níveis de degradação de imagem. Diferentes modelos All-In-One implementam diferentes abordagens para orientar o modelo cego para restaurar a imagem degradada, por exemplo, um modelo auxiliar para classificar a degradação ou vetores de orientação multidimensionais ou prompts para ajudar o modelo a restaurar diferentes tipos de degradação dentro de um imagem.
Dito isso, chegamos à manipulação de imagens baseada em texto, uma vez que ela foi implementada por vários frameworks nos últimos anos para geração de texto em imagem e tarefas de edição de imagens baseadas em texto. Esses modelos geralmente utilizam prompts de texto para descrever ações ou imagens junto com modelos baseados em difusão para gerar as imagens correspondentes. A principal inspiração para a estrutura InstructIR é a estrutura InstructPix2Pix que permite ao modelo editar a imagem usando instruções do usuário que instruem o modelo sobre qual ação executar em vez de rótulos de texto, descrições ou legendas da imagem de entrada. Como resultado, os usuários podem usar textos escritos naturais para instruir o modelo sobre qual ação executar, sem a necessidade de fornecer imagens de amostra ou descrições adicionais de imagens.
Com base nesses princípios básicos, a estrutura InstructIR é o primeiro modelo de visão computacional que emprega instruções escritas por humanos para obter restauração de imagens e resolver problemas inversos. Para prompts de linguagem natural, o modelo InstructIR pode recuperar imagens de alta qualidade de suas contrapartes degradadas e também leva em consideração vários tipos de degradação. A estrutura InstructIR é capaz de fornecer desempenho de última geração em uma ampla gama de tarefas de restauração de imagens, incluindo remoção de drenagem de imagens, remoção de ruído, desembaçamento, desfoque e aprimoramento de imagens com pouca luz. Em contraste com os trabalhos existentes que conseguem a restauração de imagens usando vetores de orientação aprendidos ou incorporações de prompts, a estrutura InstructIR emprega prompts brutos do usuário em formato de texto. A estrutura do InstructIR é capaz de generalizar para a restauração de imagens usando instruções escritas por humanos, e o modelo único completo implementado pelo InstructIR cobre mais tarefas de restauração do que os modelos anteriores. A figura a seguir demonstra as diversas amostras de restauração da estrutura InstructIR.

InstructIR: Método e Arquitetura
Basicamente, a estrutura InstructIR consiste em um codificador de texto e um modelo de imagem. O modelo usa a estrutura NAFNet, um modelo eficiente de restauração de imagem que segue uma arquitetura U-Net como modelo de imagem. Além disso, o modelo implementa técnicas de roteamento de tarefas para aprender múltiplas tarefas usando um único modelo com sucesso. A figura a seguir ilustra a abordagem de treinamento e avaliação para a estrutura InstructIR.

Inspirando-se no modelo InstructPix2Pix, a estrutura InstructIR adota instruções escritas por humanos como mecanismo de controle, uma vez que não há necessidade de o usuário fornecer informações adicionais. Essas instruções oferecem uma forma de interação expressiva e clara, permitindo ao usuário apontar a localização exata e o tipo de degradação na imagem. Além disso, o uso de prompts de usuário em vez de prompts específicos de degradação fixa melhora a usabilidade e as aplicações do modelo, uma vez que também pode ser usado por usuários que não possuem o conhecimento de domínio necessário. Para equipar a estrutura InstructIR com a capacidade de compreender diversos prompts, o modelo usa GPT-4, um grande modelo de linguagem para criar diversas solicitações, com prompts ambíguos e pouco claros removidos após um processo de filtragem.
Codificador de Texto
Um codificador de texto é usado por modelos de linguagem para mapear os prompts do usuário para uma incorporação de texto ou uma representação vetorial de tamanho fixo. Tradicionalmente, o codificador de texto de um Modelo CLIPE é um componente vital para geração de imagens baseadas em texto e modelos de manipulação de imagens baseados em texto para codificar prompts do usuário, uma vez que a estrutura CLIP é excelente em prompts visuais. No entanto, na maioria das vezes, as solicitações de degradação do usuário apresentam pouco ou nenhum conteúdo visual, tornando os grandes codificadores CLIP inúteis para tais tarefas, uma vez que prejudicarão significativamente a eficiência. Para resolver esse problema, a estrutura InstructIR opta por um codificador de frases baseado em texto que é treinado para codificar frases em um espaço de incorporação significativo. Os codificadores de frases são pré-treinados em milhões de exemplos e, ainda assim, são compactos e eficientes em comparação com os codificadores de texto tradicionais baseados em CLIP, ao mesmo tempo que têm a capacidade de codificar a semântica de diversos prompts do usuário.
Orientação de texto
Um aspecto importante da estrutura InstructIR é a implementação da instrução codificada como um mecanismo de controle para o modelo de imagem. Com base nisso, e inspirado no roteamento de tarefas para o aprendizado de muitas tarefas, a estrutura InstructIR propõe um Bloco de Construção de Instrução ou ICB para permitir transformações específicas de tarefas dentro do modelo. O roteamento de tarefas convencional aplica máscaras binárias específicas de tarefas aos recursos do canal. Porém, como o framework InstructIR não conhece a degradação, esta técnica não é implementada diretamente. Além disso, para recursos de imagem e instruções codificadas, o framework InstructIR aplica roteamento de tarefas e produz a máscara usando uma camada linear ativada usando a função Sigmoid para produzir um conjunto de pesos dependendo dos embeddings de texto, obtendo assim um c-dimensional por máscara binária do canal. O modelo aprimora ainda mais os recursos condicionados usando um NAFBlock e usa o NAFBlock e o bloco condicionado de instrução para condicionar os recursos tanto no bloco codificador quanto no bloco decodificador.
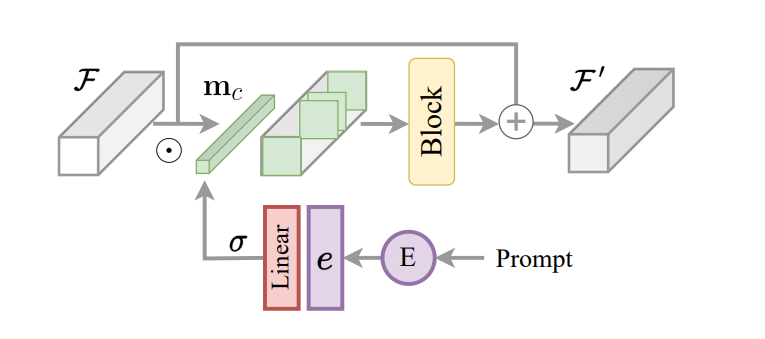
Embora a estrutura InstructIR não condicione explicitamente os filtros da rede neural, a máscara facilita o modelo a selecionar os canais mais relevantes com base nas instruções e informações da imagem.
InstructIR: Implementação e Resultados
O modelo InstructIR pode ser treinado de ponta a ponta e o modelo de imagem não requer pré-treinamento. É apenas o texto que incorpora as projeções e o cabeçalho de classificação que precisa ser treinado. O codificador de texto é inicializado usando um codificador BGE, um codificador semelhante ao BERT que é pré-treinado em uma grande quantidade de dados supervisionados e não supervisionados para codificação de frases de propósito genérico. A estrutura InstructIR usa o modelo NAFNet como modelo de imagem, e a arquitetura do NAFNet consiste em um decodificador codificador de 4 níveis com número variável de blocos em cada nível. O modelo também adiciona 4 blocos intermediários entre o codificador e o decodificador para aprimorar ainda mais os recursos. Além disso, em vez de concatenar para as conexões de salto, o decodificador implementa a adição, e o modelo InstructIR implementa apenas o ICB ou Bloco Condicionado de Instrução para roteamento de tarefas apenas no codificador e no decodificador. Seguindo em frente, o modelo InstructIR é otimizado usando a perda entre a imagem restaurada e a imagem limpa da verdade, e a perda de entropia cruzada é usada para a cabeça de classificação de intenção do codificador de texto. O modelo InstructIR usa o otimizador AdamW com um tamanho de lote de 32 e uma taxa de aprendizado de 5e-4 por quase 500 épocas, e também implementa a redução da taxa de aprendizado de recozimento de cosseno. Como o modelo de imagem na estrutura InstructIR compreende apenas 16 milhões de parâmetros e existem apenas 100 mil parâmetros de projeção de texto aprendidos, a estrutura InstructIR pode ser facilmente treinada em GPUs padrão, reduzindo assim os custos computacionais e aumentando a aplicabilidade.
Resultados de degradação múltipla
Para degradações múltiplas e restaurações multitarefas, a estrutura InstructIR define duas configurações iniciais:
- 3D para modelos de três degradações para resolver problemas de degradação, como remoção de névoa, remoção de ruído e drenagem.
- 5D para cinco modelos de degradação para resolver problemas de degradação, como eliminação de ruído de imagem, aprimoramentos com pouca luz, desembaçamento, eliminação de ruído e drenagem.
O desempenho dos modelos 5D é demonstrado na tabela a seguir e compara-o com restauração de imagem de última geração e modelos multifuncionais.

Como pode ser observado, a estrutura InstructIR com um modelo de imagem simples e apenas 16 milhões de parâmetros pode lidar com cinco tarefas diferentes de restauração de imagens com sucesso graças à orientação baseada em instruções e oferece resultados competitivos. A tabela a seguir demonstra o desempenho da estrutura em modelos 3D e os resultados são comparáveis aos resultados acima.

O principal destaque da estrutura InstructIR é a restauração de imagens baseada em instruções, e a figura a seguir demonstra as incríveis habilidades do modelo InstructIR para compreender uma ampla gama de instruções para uma determinada tarefa. Além disso, para uma instrução adversária, o modelo InstructIR executa uma identidade que não é forçada.

Considerações Finais
A restauração de imagens é um problema fundamental em visão computacional, pois visa recuperar uma imagem limpa de alta qualidade a partir de uma imagem que apresenta degradações. Na visão computacional de baixo nível, Degradações é um termo usado para representar efeitos desagradáveis observados em uma imagem, como desfoque de movimento, neblina, ruído, baixa faixa dinâmica e muito mais. Neste artigo falamos sobre o InstructIR, o primeiro framework de restauração de imagens do mundo que visa orientar o modelo de restauração de imagens usando instruções escritas por humanos. Para prompts de linguagem natural, o modelo InstructIR pode recuperar imagens de alta qualidade de suas contrapartes degradadas e também leva em consideração vários tipos de degradação. A estrutura InstructIR é capaz de fornecer desempenho de última geração em uma ampla gama de tarefas de restauração de imagens, incluindo remoção de drenagem de imagens, remoção de ruído, desembaçamento, desfoque e aprimoramento de imagens com pouca luz.















