Ângulo de Anderson
Como o Stable Diffusion Pode se Desenvolver como um Produto de Consumo de Ponta

Ironicamente, o Stable Diffusion, o novo framework de síntese de imagens de IA que conquistou o mundo, não é estável nem realmente “difundido” – pelo menos, não ainda.
A gama completa de capacidades do sistema está espalhada por uma variedade de ofertas mutáveis de uma handful de desenvolvedores que trocam as últimas informações e teorias em colóquios diversificados no Discord – e a maioria dos procedimentos de instalação para os pacotes que estão criando ou modificando está longe de ser “plug and play”.
Em vez disso, tendem a exigir instalação via linha de comando ou arquivos BAT via GIT, Conda, Python, Miniconda e outros frameworks de desenvolvimento de ponta – pacotes de software tão raros entre os consumidores comuns que sua instalação é frequentemente sinalizada por fornecedores de antivírus e anti-malware como evidência de um sistema comprometido.

Apenas uma pequena seleção de etapas no desafio que a instalação padrão do Stable Diffusion atualmente exige. Muitas das distribuições também exigem versões específicas do Python, que podem entrar em conflito com as versões existentes instaladas na máquina do usuário – embora isso possa ser evitado com instalações baseadas em Docker e, em certa medida, com o uso de ambientes Conda.
As threads de mensagens em ambas as comunidades SFW e NSFW do Stable Diffusion estão inundadas de dicas e truques relacionados à manipulação de scripts Python e instalações padrão, para habilitar funcionalidades melhoradas ou resolver erros de dependência frequentes e outros problemas.
Isso deixa o consumidor médio, interessado em criar imagens incríveis a partir de prompts de texto, praticamente à mercê do número crescente de interfaces de API da web monetizadas, a maioria das quais oferece um número mínimo de gerações de imagens gratuitas antes de exigir a compra de tokens.
Além disso, quase todas essas ofertas baseadas na web se recusam a produzir conteúdo NSFW (muito do qual pode se relacionar a assuntos de interesse geral, como “guerra”) que distingue o Stable Diffusion dos serviços censurados da OpenAI DALL-E 2.
‘Photoshop para Stable Diffusion’
Tentados pelas imagens fabulosas, ousadas ou de outro mundo que povoam o hashtag #stablediffusion do Twitter diariamente, o que o mundo mais amplo está argumentavelmente esperando é ‘Photoshop para Stable Diffusion’ – um aplicativo instalável cross-platform que incorpora a melhor e mais poderosa funcionalidade da arquitetura da Stability.ai, bem como as inovações ingentes da comunidade de desenvolvimento emergente do SD, sem janelas de linha de comando flutuantes, rotinas de instalação e atualização obscuras e mutáveis ou recursos faltantes.
O que temos atualmente, na maioria das instalações mais capazes, é uma página da web variadamente elegante straddled por uma janela de linha de comando desencarnada, e cuja URL é um porto localhost:

Semelhante aos aplicativos de síntese de CLI, como FaceSwap, e ao DeepFaceLab centrado em BAT, a instalação ‘prepack’ do Stable Diffusion mostra suas raízes de linha de comando, com a interface acessada via um porto localhost (veja o topo da imagem acima) que se comunica com a funcionalidade do Stable Diffusion baseada em CLI.
Sem dúvida, um aplicativo mais refinado está a caminho. Já existem vários aplicativos integrais baseados em Patreon que podem ser baixados, como GRisk e NMKD (veja a imagem abaixo) – mas nenhum que, ainda, integre a gama completa de recursos que algumas das implementações mais avançadas e menos acessíveis do Stable Diffusion podem oferecer.

Aplicativos iniciais do Stable Diffusion, levemente ‘aplicativados’. O NMKD é o primeiro a integrar a saída da CLI diretamente na GUI.
Vamos dar uma olhada no que uma implementação mais polida e integral do Stable Diffusion pode eventualmente parecer – e quais desafios ela pode enfrentar.
Considerações Legais para um Aplicativo Comercial de Stable Diffusion Totalmente Financiado
O Fator NSFW
O código-fonte do Stable Diffusion foi lançado sob uma licença extremamente permissiva que não proíbe reimplementações comerciais e obras derivadas que se baseiam extensivamente no código-fonte.
Além das mencionadas e crescentes construções baseadas em Patreon do Stable Diffusion, bem como o número extensivo de plugins de aplicativos em desenvolvimento para Figma, Krita, Photoshop, GIMP e Blender (entre outros), não há razão prática pela qual uma casa de desenvolvimento de software bem financiada não pudesse desenvolver um aplicativo do Stable Diffusion muito mais sofisticado e capaz. Do ponto de vista do mercado, há todos os motivos para acreditar que várias dessas iniciativas já estão bem em andamento.
Aqui, tais esforços enfrentam imediatamente o dilema de saber se o aplicativo permitirá ou não que o filtro NSFW nativo do Stable Diffusion (um fragmento de código) seja desativado.
‘Enterrando’ o Switch NSFW
Embora a licença de código aberto da Stability.ai para o Stable Diffusion inclua uma lista amplamente interpretável de aplicações para as quais ele não pode ser usado (argumentavelmente incluindo conteúdo pornográfico e deepfakes), a única maneira pela qual um fornecedor poderia efetivamente proibir tal uso seria compilar o filtro NSFW em um executável opaco em vez de um parâmetro em um arquivo Python, ou aplicar uma comparação de checksum no arquivo Python ou DLL que contém a diretiva NSFW, de modo que os renders não possam ocorrer se os usuários alterarem essa configuração.
Isso deixaria o aplicativo putativo “castrado” de maneira semelhante à como o DALL-E 2 atualmente está, diminuindo seu apelo comercial. Além disso, inevitavelmente, versões descompiladas e “manipuladas” desses componentes (seja elementos de tempo de execução Python originais ou arquivos DLL compilados, como os usados na linha de ferramentas de melhoria de imagem AI da Topaz) provavelmente surgiriam na comunidade de torrent/hacking para desbloquear tais restrições, simplesmente substituindo os elementos obstrutivos e negando quaisquer requisitos de checksum.
No final, o fornecedor pode escolher simplesmente repetir o aviso da Stability.ai contra o mau uso que caracteriza a primeira execução de muitas distribuições atuais do Stable Diffusion.
No entanto, os pequenos desenvolvedores de código aberto que atualmente usam declarações informais dessa forma têm pouco a perder em comparação com uma empresa de software que investiu quantias significativas de tempo e dinheiro para tornar o Stable Diffusion completo e acessível – o que convida a uma consideração mais profunda.
Responsabilidade por Deepfakes
Como recentemente notamos, o banco de dados LAION-aesthetics, parte dos 4,2 bilhões de imagens nos quais os modelos em andamento do Stable Diffusion foram treinados, contém um grande número de imagens de celebridades, permitindo que os usuários criem efetivamente deepfakes, incluindo pornografia de celebridades.

De nosso artigo recente, quatro estágios de Jennifer Connelly ao longo de quatro décadas de sua carreira, inferidos do Stable Diffusion.
Isso é uma questão separada e mais controversa do que a geração de (geralmente) pornografia “abstrata” legal, que não retrata “pessoas reais” (embora tais imagens sejam inferidas a partir de várias fotos reais no material de treinamento).
Desde que um número crescente de estados dos EUA e países estão desenvolvendo ou instituindo leis contra pornografia de deepfakes, a capacidade do Stable Diffusion de criar pornografia de celebridades pode significar que um aplicativo comercial que não esteja completamente censurado (ou seja, que possa criar material pornográfico) ainda pode precisar de alguma capacidade de filtrar rostos de celebridades.
Um método seria fornecer uma lista negra incorporada de termos que não serão aceitos em um prompt do usuário, relacionados a nomes de celebridades e a personagens fictícias com as quais elas podem estar associadas. Presumivelmente, tais configurações precisariam ser instituídas em mais idiomas do que apenas o inglês, desde que os dados originais apresentam outros idiomas. Outra abordagem poderia ser incorporar sistemas de reconhecimento de celebridades, como os desenvolvidos pela Clarifai.
Pode ser necessário que os produtores de software incorporem tais métodos, talvez inicialmente desativados, como pode ajudar a prevenir que um aplicativo autônomo do Stable Diffusion gere rostos de celebridades, pendente de nova legislação que possa tornar tal funcionalidade ilegal.
Mais uma vez, no entanto, tal funcionalidade poderia inevitavelmente ser descompilada e revertida por partes interessadas; no entanto, o produtor de software poderia, nesse caso, alegar que isso é essencialmente vandalismo não sancionado – desde que tal engenharia reversa não seja feita excessivamente fácil.
Recursos que Podem Ser Incluídos
A funcionalidade principal em qualquer distribuição do Stable Diffusion seria esperada de qualquer aplicativo comercial bem financiado. Esses incluem a capacidade de usar prompts de texto para gerar imagens apropriadas (texto-para-imagem); a capacidade de usar esboços ou outras imagens como diretrizes para novas imagens geradas (imagem-para-imagem); os meios para ajustar o quão “imaginativo” o sistema é instruído a ser; uma maneira de fazer um trade-off entre tempo de renderização e qualidade; e outros “básicos”, como arquivamento de imagem/prompt automático opcional e escalonamento via RealESRGAN, e pelo menos “correção de face” básica com GFPGAN ou CodeFormer.
Isso é uma instalação “vanilla” bastante básica. Vamos dar uma olhada em alguns dos recursos mais avançados que estão sendo desenvolvidos ou estendidos, que poderiam ser incorporados em um aplicativo “tradicional” completo do Stable Diffusion.
Congelamento Estocástico
Mesmo que você reutilize uma semente de uma renderização bem-sucedida anterior, é terrivelmente difícil fazer com que o Stable Diffusion repita com precisão uma transformação se qualquer parte do prompt ou da imagem de origem (ou ambos) for alterada para uma renderização subsequente.
Isso é um problema se você quiser usar EbSynth para impor transformações do Stable Diffusion em vídeo real de forma temporalmente coerente – embora a técnica possa ser muito eficaz para tiros simples de ombros e cabeça:

Movimento limitado pode tornar o EbSynth um meio eficaz para transformar transformações do Stable Diffusion em vídeo realista. Fonte: https://streamable.com/u0pgzd
O EbSynth funciona extrapolando uma pequena seleção de “quadros alterados” em um vídeo que foi renderizado em uma série de arquivos de imagem (e que pode ser posteriormente recompilado em um vídeo).

Neste exemplo do site do EbSynth, um punhado de frames de um vídeo foram pintados de maneira artística. O EbSynth usa esses frames como guias de estilo para alterar o vídeo inteiro para que ele combine com o estilo pintado. Fonte: https://www.youtube.com/embed/eghGQtQhY38
No exemplo abaixo, que apresenta quase nenhum movimento da (real) instrutora de yoga loira à esquerda, o Stable Diffusion ainda tem dificuldade em manter uma face consistente, porque os três quadros sendo transformados como “quadros-chave” não são completamente idênticos, embora compartilhem a mesma semente numérica.

Aqui, mesmo com o mesmo prompt e semente em todas as três transformações, e muito poucas alterações entre os quadros de origem, os músculos do corpo variam em tamanho e forma, mas mais importante, a face é inconsistente, dificultando a consistência temporal em uma renderização potencial do EbSynth.
Embora o vídeo do SD/EbSynth abaixo seja muito inventivo, onde os dedos do usuário se transformam em (respectivamente) uma perna de calça ambulante e um pato, a inconsistência das calças é típica do problema que o Stable Diffusion tem em manter a consistência entre diferentes quadros-chave, mesmo quando os quadros de origem são semelhantes entre si e a semente é consistente.

Os dedos de um homem se tornam um homem ambulante e um pato, via Stable Diffusion e EbSynth. Fonte: https://old.reddit.com/r/StableDiffusion/comments/x92itm/proof_of_concept_using_img2img_ebsynth_to_animate/
O usuário que criou este vídeo comentou que a transformação do pato, que é mais eficaz das duas, exigiu apenas um quadro-chave transformado, enquanto foi necessário renderizar 50 imagens do Stable Diffusion para criar as calças ambulantes, que exibem mais inconsistência temporal. O usuário também notou que levou cinco tentativas para alcançar a consistência para cada um dos 50 quadros-chave.
Portanto, seria um grande benefício para um aplicativo do Stable Diffusion realmente abrangente fornecer funcionalidade que preserve as características ao máximo entre os quadros-chave.
Uma possibilidade é permitir que o usuário “congele” o encode estocástico para a transformação em cada quadro, o que atualmente só pode ser alcançado modificando o código-fonte manualmente. Como o exemplo abaixo mostra, isso ajuda na consistência temporal, embora certamente não a resolva:

Um usuário do Reddit transformou footage de webcam de si mesmo em diferentes pessoas famosas, não apenas persistindo a semente (o que qualquer implementação do Stable Diffusion pode fazer), mas garantindo que o parâmetro stochastic_encode() fosse idêntico em cada transformação. Isso foi alcançado modificando o código, mas poderia facilmente se tornar um interruptor acessível ao usuário. Claramente, no entanto, isso não resolve todos os problemas temporais. Fonte: https://old.reddit.com/r/StableDiffusion/comments/wyeoqq/turning_img2img_into_vid2vid/
Inversão Textual Baseada em Nuvem
Uma solução melhor para elicitar personagens e objetos temporalmente consistentes é “assar” eles em uma Inversão Textual – um arquivo de 5KB que pode ser treinado em algumas horas com base em apenas cinco imagens anotadas, que podem então ser evocadas por um prompt especial ‘*’, permitindo, por exemplo, a aparência persistente de personagens novos para inclusão em uma narrativa.

Imagens associadas a tags apropriadas podem ser convertidas em entidades discretas via Inversão Textual, e convocadas sem ambiguidade, e no contexto e estilo corretos, por palavras especiais de token. Fonte: https://huggingface.co/docs/diffusers/training/text_inversion
As Inversões Textuais são arquivos adjunctos ao modelo grande e totalmente treinado que o Stable Diffusion usa, e são efetivamente “slipstreamed” no processo de elicitação/prompting, de modo que possam participar em cenas derivadas do modelo e se beneficiar do enorme banco de dados de conhecimento do modelo sobre objetos, estilos, ambientes e interações.
No entanto, embora uma Inversão Textual não leve muito tempo para treinar, ela exige uma grande quantidade de VRAM; de acordo com vários walkthroughs atuais, em algum lugar entre 12, 20 e até 40GB.
Como a maioria dos usuários casuais não tem esse tipo de capacidade de GPU à sua disposição, serviços de nuvem já estão surgindo que lidarão com a operação, incluindo uma versão da Hugging Face. Embora existam implementações do Colab do Google que podem criar inversões textuais para o Stable Diffusion, os requisitos de VRAM e tempo podem torná-los desafiadores para usuários do Colab de nível gratuito.
Para um aplicativo do Stable Diffusion completo e bem investido, passar essa tarefa pesada para os servidores de nuvem da empresa parece uma estratégia de monetização óbvia (supondo que um aplicativo do Stable Diffusion de baixo ou nenhum custo seja permeado por tal funcionalidade não gratuita, o que parece provável em muitos aplicativos que surgirão dessa tecnologia nos próximos 6-9 meses).
Além disso, o processo complicado de anotar e formatar as imagens e texto submetidos poderia se beneficiar da automação em um ambiente integrado. O fator “viciante” de criar elementos únicos que podem explorar e interagir com os vastos mundos do Stable Diffusion pareceria potencialmente compulsivo, tanto para entusiastas em geral quanto para usuários mais jovens.
Pesagem de Prompt Versátil
Existem muitas implementações atuais que permitem que o usuário atribua maior ênfase a uma seção de um prompt de texto longo, mas o instrumento varia muito entre elas e é frequentemente desajeitado ou pouco intuitivo.
A popular fork do Stable Diffusion por AUTOMATIC1111, por exemplo, pode diminuir ou aumentar o valor de uma palavra de prompt, cercando-a com colchetes simples ou múltiplos (para desvalorização) ou colchetes quadrados para ênfase extra.

Colchetes quadrados e/ou parênteses podem transformar o seu café da manhã nessa versão dos pesos do prompt do Stable Diffusion, mas é um pesadelo de colesterol de qualquer maneira.
Outras iterações do Stable Diffusion usam pontos de exclamação para ênfase, enquanto as mais versáteis permitem que os usuários atribuam pesos a cada palavra no prompt por meio da GUI.
O sistema também deve permitir pesos de prompt negativos – não apenas para fãs de terror, mas porque pode haver mistérios mais edificantes no espaço latente do Stable Diffusion do que o nosso uso limitado da linguagem pode evocar.
Pintura Fora da Tela
Logo após a sensacional abertura do código do Stable Diffusion, a OpenAI tentou – em grande parte em vão – recuperar um pouco do seu trovão DALL-E 2 anunciando ‘pintura fora da tela’, que permite que um usuário estenda uma imagem além de seus limites com lógica semântica e coerência visual.
Naturalmente, isso já foi implementado em várias formas para o Stable Diffusion, bem como no Krita, e certamente deve ser incluído em uma versão abrangente e estilo Photoshop do Stable Diffusion.
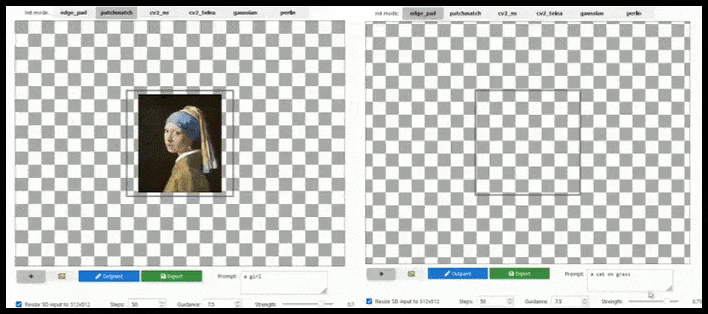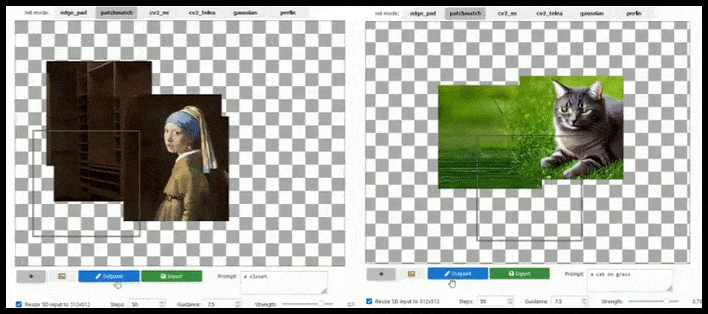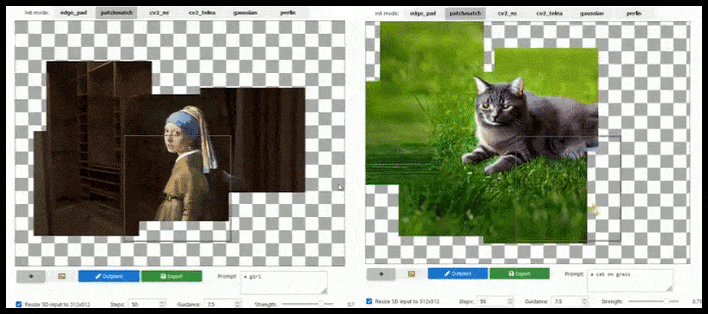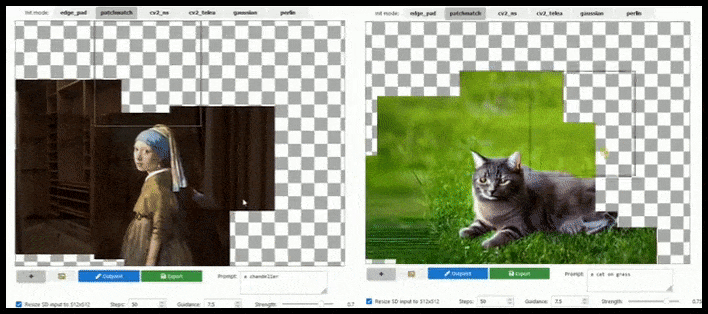
Aumento baseado em azulejos pode estender uma renderização padrão de 512×512 quase infinitamente, desde que os prompts, imagem existente e lógica semântica permitam. Fonte: https://github.com/lkwq007/stablediffusion-infinity
Porque o Stable Diffusion é treinado em imagens de 512x512px (e por uma variedade de outros motivos), ele frequentemente corta as cabeças (ou outras partes essenciais do corpo) de sujeitos humanos, mesmo onde o prompt claramente indicou ‘ênfase na cabeça’, etc..

Exemplos típicos de ‘decapitação’ do Stable Diffusion; mas a pintura fora da tela poderia colocar George de volta na imagem.
Qualquer implementação de pintura fora da tela do tipo ilustrado na imagem animada acima (que é baseada exclusivamente em bibliotecas Unix, mas deve ser capaz de ser replicada no Windows) também deve ser ferramentada como um remédio de um clique/prompt para isso.
Atualmente, vários usuários estendem a tela de ‘decapitações’ para cima, preenchem a área da cabeça aproximadamente e usam img2img para completar a renderização falha.
Máscara Eficaz que Entende o Contexto
A máscara pode ser um assunto muito imprevisível no Stable Diffusion, dependendo da fork ou versão em questão. Frequentemente, onde é possível desenhar uma máscara coesa, a área especificada acaba sendo repintada com conteúdo que não leva em conta o contexto geral da imagem.
Em uma ocasião, eu mascarei os córneos de uma imagem de rosto e forneceu o prompt ‘olhos azuis’ como uma máscara de repintura – apenas para descobrir que eu parecia estar olhando através de dois olhos humanos cortados para uma imagem distante de um lobo com aparência sobrenatural. Eu acho que eu sou sortudo por não ser Frank Sinatra.
Edição semântica também é possível identificando o ruído que construiu a imagem em primeiro lugar, o que permite ao usuário abordar elementos estruturais específicos em uma renderização sem interferir com o resto da imagem:

Alterando um elemento em uma imagem sem máscara tradicional e sem alterar o conteúdo adjacente, identificando o ruído que originou a imagem e abordando as partes que contribuíram para a área de destino. Fonte: https://old.reddit.com/r/StableDiffusion/comments/xboy90/a_better_way_of_doing_img2img_by_finding_the/
Este método é baseado no amostrador K-Diffusion.
Filtros Semânticos para Erros Fisiológicos
Como mencionamos anteriormente, o Stable Diffusion pode frequentemente adicionar ou subtrair membros, principalmente devido a problemas de dados e limitações nas anotações que acompanham as imagens que o treinaram.

Assim como o garoto travesso que colocou a língua para fora na foto de grupo da escola, as atrocidades biológicas do Stable Diffusion nem sempre são imediatamente óbvias, e você pode ter compartilhado sua última obra-prima de IA no Instagram antes de notar as mãos extras ou membros derretidos.
É tão difícil consertar esses tipos de erros que seria útil se um aplicativo do Stable Diffusion completo contivesse algum tipo de sistema de reconhecimento anatômico que empregasse segmentação semântica para calcular se a imagem de entrada apresenta deficiências anatômicas graves (como na imagem acima), e a descarta em favor de uma nova renderização antes de apresentá-la ao usuário.

É claro que você pode querer renderizar a deusa Kali, ou Doutor Octopus, ou até mesmo resgatar uma parte não afetada de uma imagem com membros afetados, então esse recurso deve ser um toggle opcional.
Se os usuários pudessem tolerar o aspecto de telemetria, tais disparos poderiam ser transmitidos anonimamente em um esforço coletivo de aprendizado federativo que pode ajudar os modelos futuros a melhorar sua compreensão da lógica anatômica.
Melhoria Automática de Rostos Baseada em LAION
Como eu notei em minha análise anterior de três coisas que o Stable Diffusion poderia abordar no futuro, não deve ser deixado apenas para alguma versão do GFPGAN tentar “melhorar” rostos renderizados em renderizações de primeira instância.
As “melhorias” do GFPGAN são terrivelmente genéricas, frequentemente minam a identidade do indivíduo retratado e operam apenas em um rosto que recebeu tanto tempo de processamento ou atenção quanto qualquer outra parte da imagem.
Portanto, um programa profissional para o Stable Diffusion deve ser capaz de reconhecer um rosto (com uma biblioteca padrão e relativamente leve, como YOLO), aplicar o peso total da capacidade de GPU disponível para re-renderizar, e ou mesclar o rosto melhorado na renderização original de contexto completo, ou salvá-lo separadamente para re-composição manual. Atualmente, isso é uma operação bastante “hands on”.
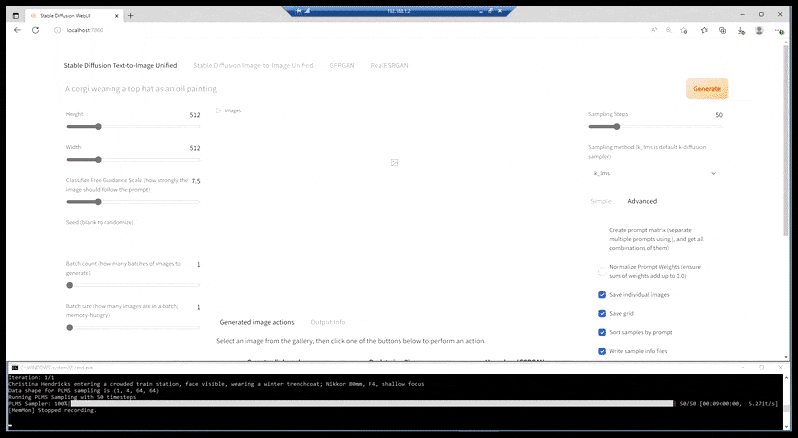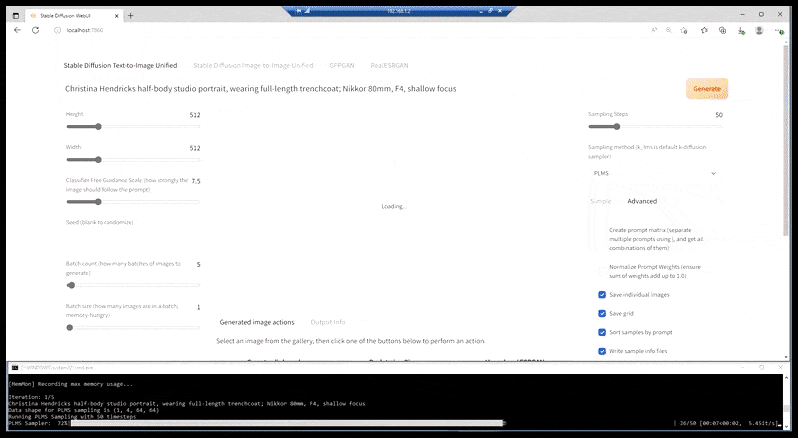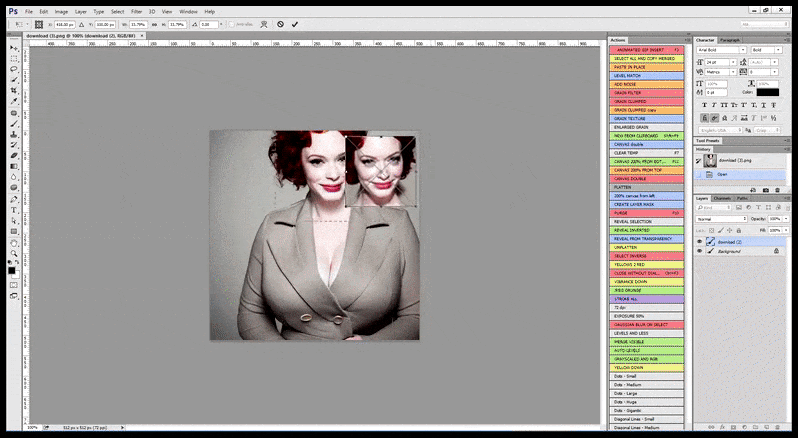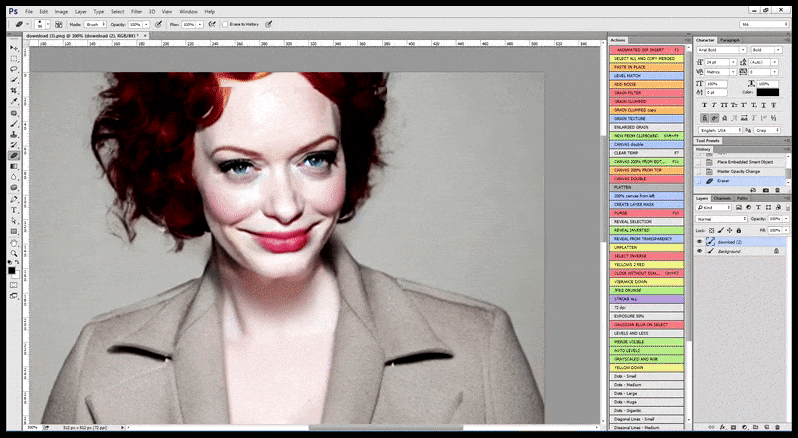
Em casos em que o Stable Diffusion foi treinado em um número adequado de imagens de uma celebridade, é possível focar a capacidade total da GPU em uma renderização subsequente apenas do rosto da imagem renderizada, o que geralmente é uma melhoria notável – e, ao contrário do GFPGAN, desenha informações a partir de dados treinados com LAION, em vez de simplesmente ajustar os pixels renderizados.
Pesquisas de LAION no Aplicativo
Desde que os usuários começaram a perceber que procurar no banco de dados LAION por conceitos, pessoas e temas poderia ser uma ajuda para um melhor uso do Stable Diffusion, vários exploradores de LAION online foram criados, incluindo haveibeentrained.com.

A função de pesquisa em haveibeentrained.com permite que os usuários explorem as imagens que alimentam o Stable Diffusion e descubram se objetos, pessoas ou ideias que eles gostariam de evocar do sistema são prováveis de terem sido treinadas nele. Fonte: https://haveibeentrained.com/?search_text=bowl%20of%20fruit
Embora tais bancos de dados baseados na web frequentemente revelem algumas das tags que acompanham as imagens, o processo de generalização que ocorre durante o treinamento do modelo significa que é improvável que qualquer imagem particular possa ser convocada usando sua tag como um prompt.
Além disso, a remoção de ‘palavras de parada’ e a prática de stemming e lemmatization no Processamento de Linguagem Natural significa que muitas das frases exibidas foram divididas ou omitidas antes de serem treinadas no Stable Diffusion.
No entanto, a forma como os agrupamentos estéticos se unem nesses interfaces pode ensinar ao usuário final muito sobre a lógica (ou, argumentavelmente, a “personalidade”) do Stable Diffusion e provar uma ajuda para uma melhor produção de imagens.
Conclusão
Existem muitos outros recursos que eu gostaria de ver em uma implementação nativa de desktop completa do Stable Diffusion, como análise de imagem baseada em CLIP nativa, que reverte o processo padrão do Stable Diffusion e permite que o usuário elicie frases e palavras que o sistema naturalmente associaria à imagem de origem ou à renderização.
Além disso, o escalonamento baseado em azulejos real seria uma adição bem-vinda, pois o ESRGAN é quase tão bruto quanto o GFPGAN. Felizmente, planos para integrar a implementação do txt2imghd do GOBIG estão rapidamente tornando isso uma realidade em todas as distribuições, e parece uma escolha óbvia para uma iteração de desktop.
Outros pedidos populares das comunidades do Discord me interessam menos, como dicionários de prompts integrados e listas aplicáveis de artistas e estilos, embora um caderno interno ou um léxico personalizável de frases pareça uma adição lógica.
Da mesma forma, as limitações atuais da animação humana centrada no Stable Diffusion, embora iniciadas pelo CogVideo e vários outros projetos, ainda são incrivelmente nascentes e à mercê da pesquisa upstream sobre priors temporais relacionados ao movimento humano autêntico.
Por agora, o vídeo do Stable Diffusion é estritamente psicodélico, embora possa ter um futuro brilhante na marionetagem de deepfakes, via EbSynth e outras iniciativas de texto-para-vídeo relativamente nascentes (e vale notar a falta de pessoas sintetizadas ou ‘alteradas’ no vídeo promocional mais recente da Runway).
Outra funcionalidade valiosa seria a passagem transparente do Photoshop, estabelecida há muito tempo no editor de textura do Cinema4D, entre outras implementações semelhantes. Com isso, é possível transferir imagens entre aplicativos facilmente e usar cada aplicativo para realizar as transformações que ele executa melhor.
Finalmente, e talvez mais importante, um programa de desktop do Stable Diffusion completo deve ser capaz não apenas de trocar facilmente entre checkpoints (ou seja, versões do modelo subjacente que alimenta o sistema), mas também deve ser capaz de atualizar Inversões Textuais personalizadas que funcionavam com lançamentos anteriores oficiais do modelo, mas que podem ser quebradas por versões posteriores do modelo (como os desenvolvedores no Discord oficial indicaram que poderia ser o caso).
Ironicamente, a organização na melhor posição para criar tal matriz poderosa e integrada de ferramentas para o Stable Diffusion, a Adobe, se alinhou tão fortemente à Iniciativa de Autenticidade de Conteúdo que pode parecer um passo de relações públicas retrógrado para a empresa – a menos que ela estivesse disposta a limitar os poderes gerativos do Stable Diffusion tão completamente quanto a OpenAI fez com o DALL-E 2, e posicioná-lo em vez disso como uma evolução natural de seus consideráveis investimentos em fotografia de estoque.
Publicado pela primeira vez em 15 de setembro de 2022.












