Inteligência artificial
Três Desafios à Frente para a Difusão Estável

A liberação do modelo de síntese de imagem de difusão latente da stability.ai, Difusão Estável, há um par de semanas, pode ser uma das mais significativas divulgações tecnológicas desde DeCSS em 1999; certamente é o maior evento em imagens geradas por IA desde o código de deepfakes em 2017 foi copiado para o GitHub e bifurcado no que se tornaria DeepFaceLab e FaceSwap, bem como o software de transmissão de deepfakes em tempo real DeepFaceLive.
Com um único golpe, a frustração do usuário sobre as restrições de conteúdo na API de síntese de imagem do DALL-E 2 foram eliminadas, pois se descobriu que o filtro NSFW da Difusão Estável podia ser desativado alterando uma única linha de código. Reddits de Difusão Estável com foco em pornografia surgiram quase imediatamente e foram rapidamente eliminados, enquanto o desenvolvedor e a comunidade de usuários se dividiram no Discord em comunidades oficiais e NSFW, e o Twitter começou a ser preenchido com criações fantásticas da Difusão Estável.
No momento, cada dia parece trazer alguma inovação incrível dos desenvolvedores que adotaram o sistema, com plugins e adjuntos de terceiros sendo escritos apressadamente para Krita, Photoshop, Cinema4D, Blender e muitas outras plataformas de aplicativos.
Enquanto isso, promptcraft – a agora profissional arte de ‘sussurro de IA’, que pode acabar sendo a opção de carreira mais curta desde ‘Filofax binder’ – já está sendo comercializada, enquanto a monetização inicial da Difusão Estável está ocorrendo no nível Patreon, com a certeza de que haverá ofertas mais sofisticadas por vir, para aqueles que não estão dispostos a navegar por instalações baseadas em Conda do código-fonte, ou os filtros NSFW proibitivos de implementações baseadas na web.
A velocidade do desenvolvimento e o senso de exploração livre dos usuários estão ocorrendo a uma velocidade tão vertiginosa que é difícil ver muito à frente. Essencialmente, não sabemos exatamente com o que estamos lidando ainda, ou quais são todas as limitações ou possibilidades.
No entanto, vamos dar uma olhada em três dos que podem ser os obstáculos mais interessantes e desafiadores para a comunidade da Difusão Estável, rapidamente formada e em crescimento, enfrentar e, esperançosamente, superar.
1: Otimizando Pipelines Baseadas em Blocos
Apresentados com recursos de hardware limitados e limites rígidos na resolução das imagens de treinamento, parece provável que os desenvolvedores encontrem soluções para melhorar tanto a qualidade quanto a resolução da saída da Difusão Estável. Muitos desses projetos estão prestes a envolver a exploração das limitações do sistema, como sua resolução nativa de apenas 512×512 pixels.
Como é sempre o caso com iniciativas de visão computacional e síntese de imagem, a Difusão Estável foi treinada em imagens com razão de aspecto quadrada, neste caso, reamostradas para 512×512, para que as imagens de origem pudessem ser regularizadas e capazes de se encaixar nas restrições dos GPUs que treinaram o modelo.
Portanto, a Difusão Estável ‘pensa’ (se é que pensa) em termos de 512×512, e certamente em termos quadrados. Muitos usuários que atualmente exploram os limites do sistema relatam que a Difusão Estável produz os resultados mais confiáveis e menos problemáticos nessa razão de aspecto bastante restrita (veja ‘endereçando extremidades’ abaixo).
Embora várias implementações apresentem escalonamento via RealESRGAN (e possam consertar faces mal renderizadas via GFPGAN), vários usuários estão atualmente desenvolvendo métodos para dividir imagens em seções de 512x512px e costurar as imagens para formar obras compostas maiores.

Esta renderização de 1024×576, uma resolução normalmente impossível em uma única renderização da Difusão Estável, foi criada copiando e colando o arquivo attention.py Python do fork DoggettX da Difusão Estável (uma versão que implementa escalonamento baseado em blocos) em outro fork. Fonte: https://old.reddit.com/r/StableDiffusion/comments/x6yeam/1024x576_with_6gb_nice/
Embora algumas iniciativas desse tipo usem código original ou outras bibliotecas, a porta txt2imghd do GOBIG (um modo no ProgRockDiffusion voraz de VRAM) está prestes a fornecer essa funcionalidade ao ramo principal em breve. Enquanto o txt2imghd é uma porta dedicada do GOBIG, outros esforços de desenvolvedores da comunidade envolvem implementações diferentes do GOBIG.

Uma imagem convenientemente abstrata na renderização original de 512x512px (esquerda e segunda da esquerda); escalonada pelo ESGRAN, que agora é mais ou menos nativo em todas as distribuições da Difusão Estável; e recebendo ‘atenção especial’ via uma implementação do GOBIG, produzindo detalhes que, pelo menos dentro dos limites da seção da imagem, parecem melhor escalonados. Fonte: https://old.reddit.com/r/StableDiffusion/comments/x72460/stable_diffusion_gobig_txt2imghd_easy_mode_colab/
O tipo de exemplo abstrato apresentado acima tem muitos ‘pequenos reinos’ de detalhes que se adequam a essa abordagem solipsística de escalonamento, mas que podem exigir soluções de código mais desafiadoras para produzir escalonamento não repetitivo e coeso que não pareça como se tivesse sido montado a partir de muitas partes. Não menos, no caso de faces humanas, onde estamos excepcionalmente atentos a aberrations ou artefatos ‘desconcertantes’. Portanto, as faces podem eventualmente precisar de uma solução dedicada.
A Difusão Estável atualmente não tem mecanismo para focar a atenção na face durante uma renderização da mesma maneira que os humanos priorizam informações faciais. Embora alguns desenvolvedores nas comunidades do Discord estejam considerando métodos para implementar esse tipo de ‘atenção aprimorada’, atualmente é muito mais fácil melhorar a face manualmente (e, eventualmente, automaticamente) após a renderização inicial ter ocorrido.
Uma face humana tem uma lógica semântica interna e completa que não será encontrada em um ‘bloco’ do canto inferior de (por exemplo) um prédio, e, portanto, é atualmente possível ‘zoomar’ e renderizar novamente uma face ‘esboçada’ na saída da Difusão Estável.

Esquerda, a primeira tentativa da Difusão Estável com o prompt ‘Foto em cores de Christina Hendricks entrando em um local movimentado, usando um casaco de chuva; Canon50, contato visual, alto detalhe, alto detalhe facial’. Direita, uma face aprimorada obtida alimentando a face embaçada e esboçada da primeira renderização de volta para a atenção total da Difusão Estável usando Img2Img (veja imagens animadas abaixo).
Na ausência de uma solução de Inversão Textual dedicada (veja abaixo), isso só funcionará para imagens de celebridades onde a pessoa em questão já é bem representada nos subconjuntos de dados LAION que treinaram a Difusão Estável. Portanto, funcionará com as likes de Tom Cruise, Brad Pitt, Jennifer Lawrence e um número limitado de luminares de mídia genuínos que estão presentes em grande número de imagens nos dados de origem.
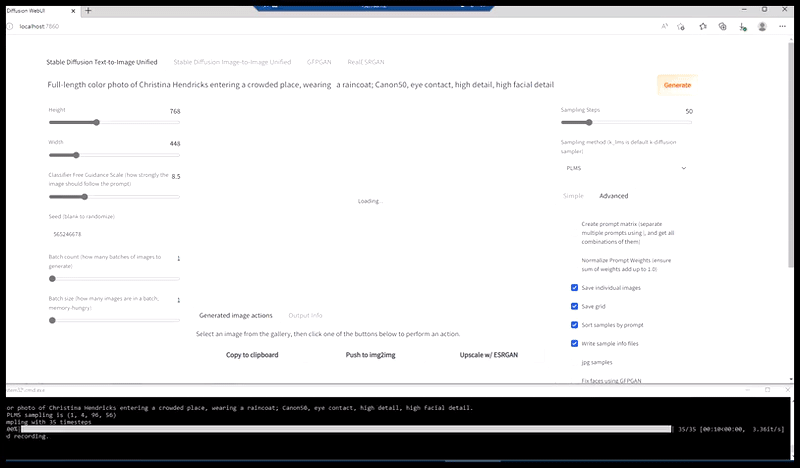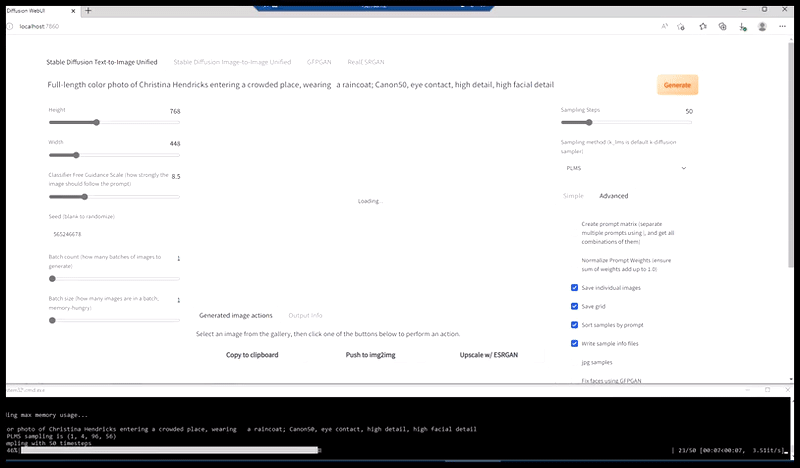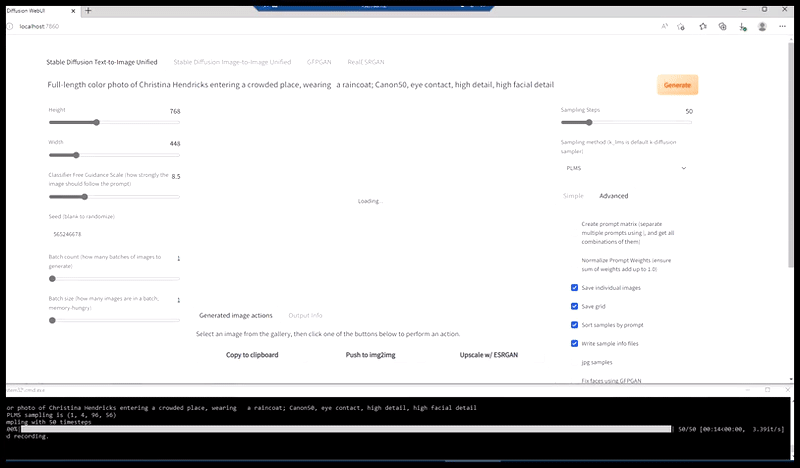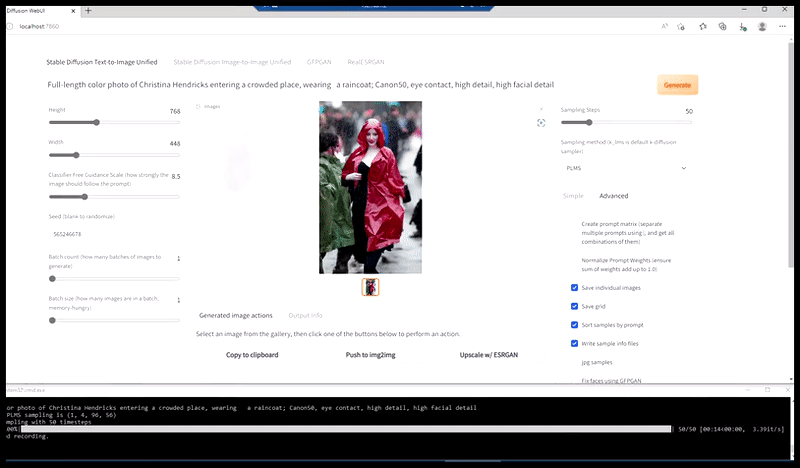
Gerando uma foto de imprensa plausível com o prompt ‘Foto em cores de Christina Hendricks entrando em um local movimentado, usando um casaco de chuva; Canon50, contato visual, alto detalhe, alto detalhe facial’.
Para celebridades com carreiras longas e duradouras, a Difusão Estável geralmente gerará uma imagem da pessoa em uma idade recente (ou seja, mais velha), e será necessário adicionar adjuntos de prompt como ‘jovem’ ou ‘no ano [ANO]’ para produzir imagens com aparência mais jovem.

Com uma carreira proeminente e consistentemente fotografada que abrange quase 40 anos, a atriz Jennifer Connelly é uma das poucas celebridades no LAION que permitem que a Difusão Estável represente uma faixa etária. Fonte: prepack Difusão Estável, local, v1.4 checkpoint; prompts relacionados à idade.
Isso ocorre principalmente devido à proliferação de fotografia de imprensa digital (em vez de baseada em emulsão) a partir da metade dos anos 2000, e ao posterior crescimento no volume de saída de imagem devido ao aumento das velocidades de banda larga.
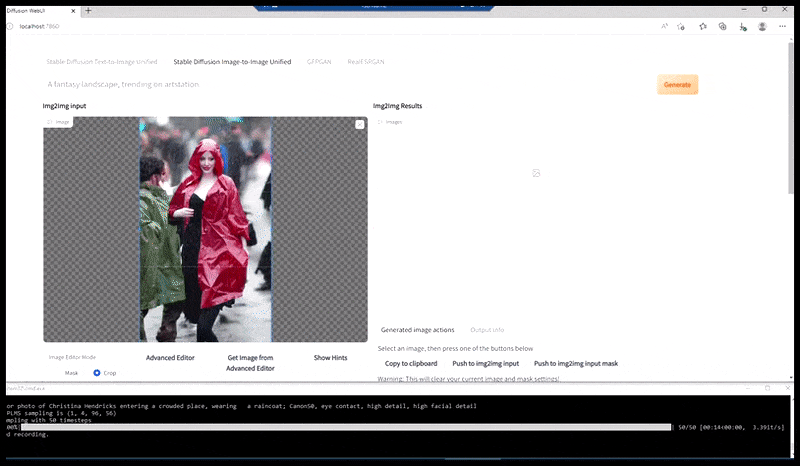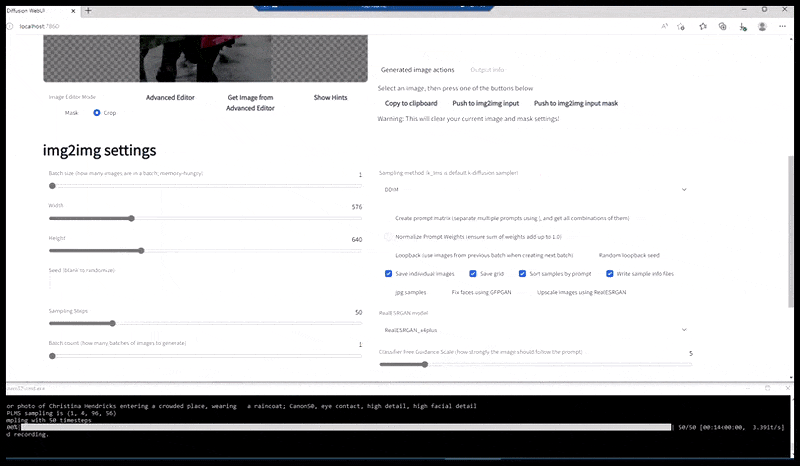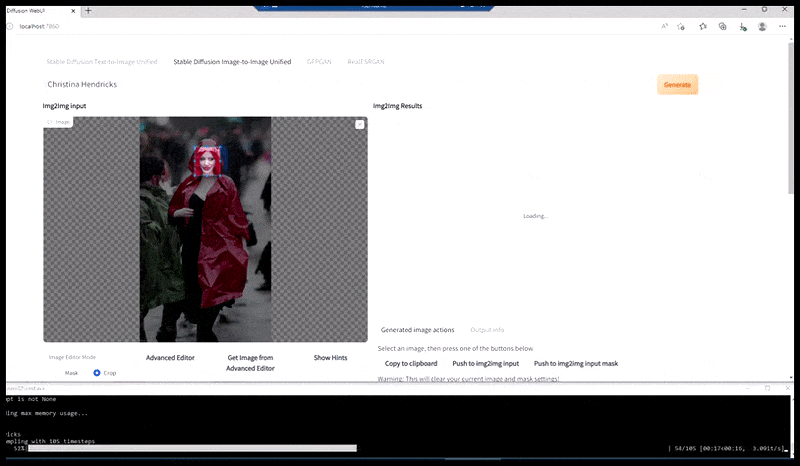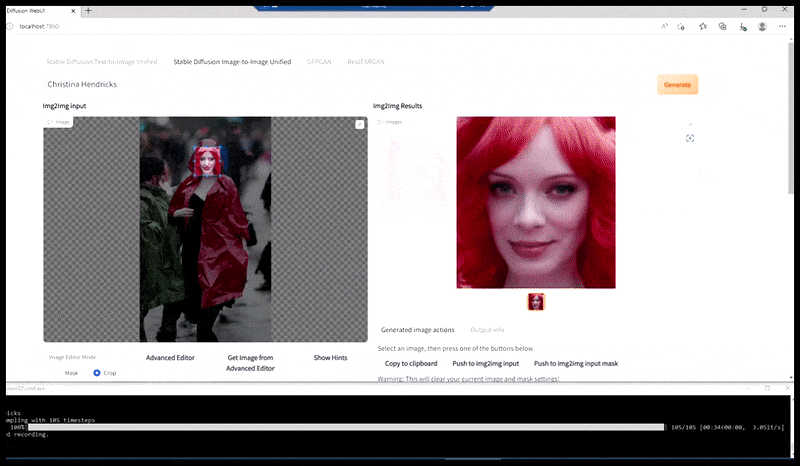
A imagem renderizada é passada para o Img2Img na Difusão Estável, onde uma ‘área de foco’ é selecionada, e uma nova renderização de tamanho máximo é feita apenas dessa área, permitindo que a Difusão Estável concentre todos os recursos disponíveis para recriar a face.
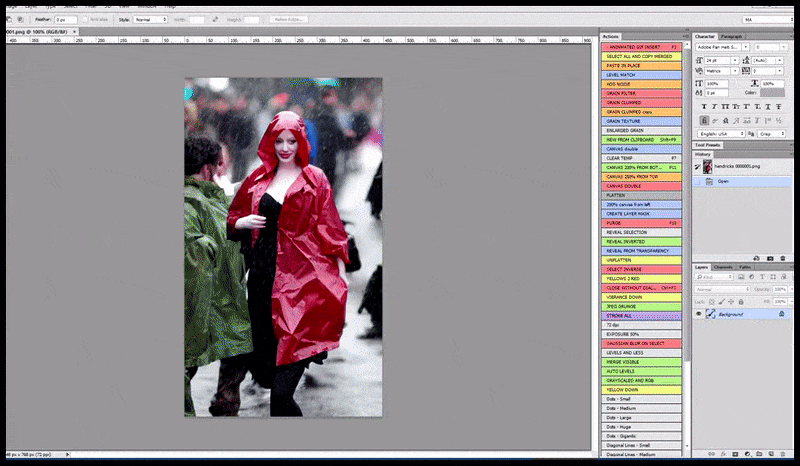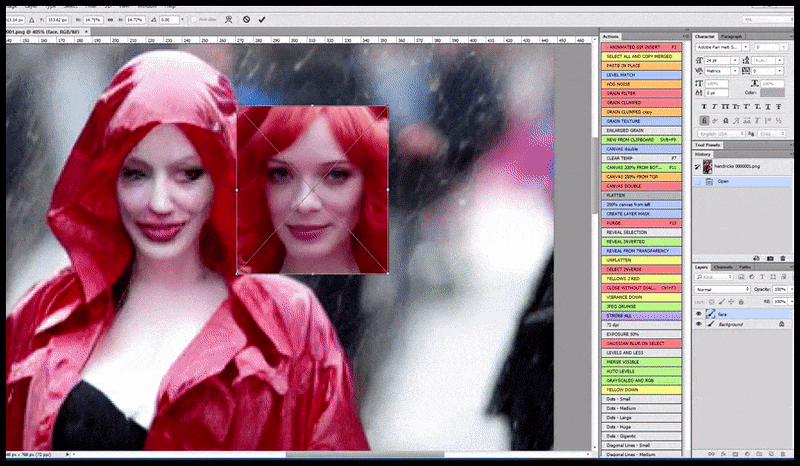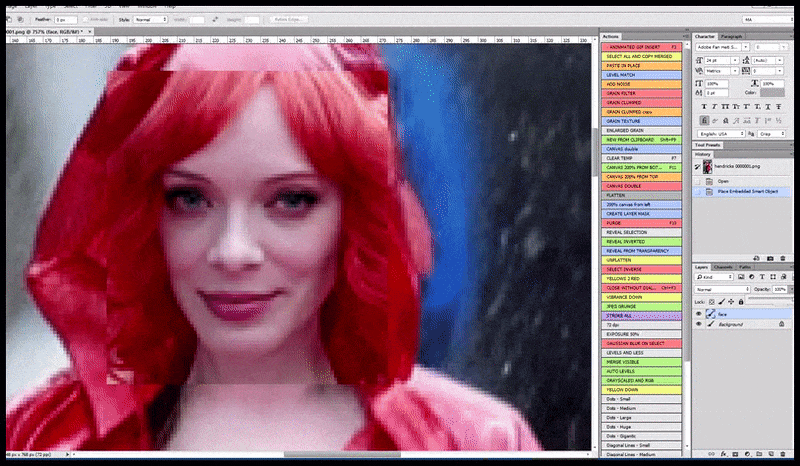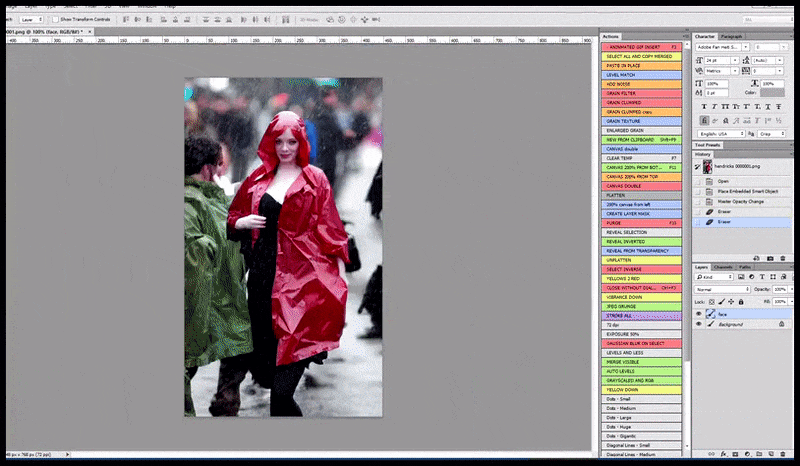
Compondo a face de ‘alta atenção’ de volta à renderização original. Além de faces, esse processo só funcionará com entidades que têm uma aparência coesa e integral conhecida, como uma porção da foto original que tem um objeto distinto, como um relógio ou um carro. Escalonar uma seção de – por exemplo – uma parede vai levar a uma parede re montada com uma aparência muito estranha, porque as renderizações de blocos não tinham contexto mais amplo para essa ‘peça de quebra-cabeça’ enquanto estavam renderizando.
Algumas celebridades no banco de dados vêm ‘congeladas’ no tempo, seja porque morreram cedo (como Marilyn Monroe), ou alcançaram apenas uma proeminência mainstream fugaz, produzindo um grande volume de imagens em um período de tempo limitado. A votação da Difusão Estável pode ser considerada como um tipo de ‘índice de popularidade atual’ para estrelas modernas e mais antigas. Para algumas celebridades mais velhas e atuais, não há imagens suficientes nos dados de origem para obter uma semelhança muito boa, enquanto a popularidade duradoura de certas estrelas falecidas ou desaparecidas assegura que sua semelhança razoável possa ser obtida do sistema.

As renderizações da Difusão Estável revelam rapidamente quais faces famosas estão bem representadas nos dados de treinamento. Apesar de sua enorme popularidade como adolescente mais velho no momento da escrita, Millie Bobby Brown era mais jovem e menos conhecida quando os conjuntos de dados de origem LAION foram coletados da web, tornando uma semelhança de alta qualidade com a Difusão Estável problemática no momento.
Onde os dados estão disponíveis, soluções de escalonamento baseadas em blocos na Difusão Estável poderiam ir além de se concentrar na face: poderiam potencialmente permitir faces ainda mais precisas e detalhadas, dividindo as características faciais e aplicando toda a força dos recursos de GPU locais em recursos individuais, antes da re montagem – um processo que atualmente é manual.

Isso não se limita a faces, mas é limitado a partes de objetos que são pelo menos tão previsivelmente colocados no contexto mais amplo do objeto hospedeiro e que se conformam a embeddings de alto nível que se poderia razoavelmente esperar encontrar em um conjunto de dados de hipercala.
O limite real é a quantidade de dados de referência disponíveis no conjunto de dados, porque, eventualmente, detalhes profundamente iterados se tornarão completamente ‘alucinados’ (ou seja, fictícios) e menos autênticos.
Tais ampliações granulares de alto nível funcionam no caso de Jennifer Connelly, porque ela está bem representada em uma faixa etária na LAION-aesthetics (o subconjunto principal da LAION 5B que a Difusão Estável usa), e geralmente em toda a LAION; em muitos outros casos, a precisão sofreria com a falta de dados, necessitando de ajustes finos (treinamento adicional, veja ‘Personalização’ abaixo) ou Inversão Textual (veja abaixo).
Blocos são uma maneira poderosa e relativamente barata para que a Difusão Estável seja habilitada a produzir saída de alta resolução, mas o escalonamento algorítmico de blocos dessa forma, se carece de algum tipo de mecanismo de atenção de mais alto nível, pode ficar aquém dos padrões desejados em uma variedade de tipos de conteúdo.
2: Endereçando Problemas com Membros Humanos
A Difusão Estável não vive à altura de seu nome ao retratar a complexidade dos membros humanos. As mãos podem se multiplicar aleatoriamente, os dedos se fundem, pernas adicionais aparecem sem ser solicitadas e membros existentes desaparecem sem deixar rastros. Em sua defesa, a Difusão Estável compartilha o problema com seus companheiros de estabilidade, e certamente com o DALL-E 2.

Resultados não editados do DALL-E 2 e Difusão Estável (1.4) no final de agosto de 2022, ambos mostrando problemas com membros. Prompt é ‘Uma mulher abraçando um homem’
Os fãs da Difusão Estável que esperam que o próximo checkpoint 1.5 (uma versão mais treinada do modelo, com parâmetros aprimorados) resolveria a confusão dos membros provavelmente serão desapontados. O novo modelo, que será lançado em cerca de duas semanas, está sendo lançado no portal comercial da stability.ai DreamStudio, que usa 1.5 por padrão, e onde os usuários podem comparar a nova saída com renderizações de seus sistemas locais ou outros sistemas 1.4:

Fonte: Prepack 1.4 local e https://beta.dreamstudio.ai/

Fonte: Prepack 1.4 local e https://beta.dreamstudio.ai/

Fonte: Prepack 1.4 local e https://beta.dreamstudio.ai/
Como é frequentemente o caso, a qualidade dos dados pode ser a causa principal contribuinte.
Os bancos de dados de código aberto que alimentam sistemas de síntese de imagem, como a Difusão Estável e o DALL-E 2, são capazes de fornecer muitas etiquetas para humanos individuais e ações inter-humanas. Essas etiquetas são treinadas em conjunto com as imagens associadas, ou segmentos de imagens.

Os usuários da Difusão Estável podem explorar os conceitos treinados no modelo, consultando o conjunto de dados LAION-aesthetics, um subconjunto do conjunto de dados LAION 5B maior, que alimenta o sistema. As imagens são ordenadas não por suas etiquetas alfabéticas, mas por sua ‘pontuação estética’. Fonte: https://rom1504.github.io/clip-retrieval/
Uma hierarquia boa de etiquetas individuais e classes contribuindo para a representação de um braço humano seria algo como corpo>braço>mão>dedos>[subdedos + polegar]> [segmentos de dedos]>Unhas.

Segmentação semântica granular das partes de uma mão. Mesmo essa deconstrução detalhada deixa cada ‘dedo’ como uma entidade única, não contando com os três segmentos de um dedo e os dois segmentos de um polegar Fonte: https://athitsos.utasites.cloud/publications/rezaei_petra2021.pdf
Na realidade, as imagens de origem são improváveis de ser consistentemente anotadas em todo o conjunto de dados, e algoritmos de etiquetagem não supervisionados provavelmente pararão no nível mais alto de – por exemplo – ‘mão’, e deixarão os pixels internos (que tecnicamente contêm informações de ‘dedos’) como uma massa não etiquetada de pixels, a partir da qual recursos serão derivados arbitrariamente e que podem se manifestar em renderizações posteriores como um elemento desconcertante.

Como deveria ser (canto superior direito, se não canto superior), e como tende a ser (canto inferior direito), devido a recursos limitados para etiquetagem, ou exploração arquitetônica de tais etiquetas se elas existem no conjunto de dados.
Assim, se um modelo de difusão latente chegar ao ponto de renderizar um braço, é quase certo que pelo menos tentará renderizar uma mão no final daquele braço, porque braço>mão é a hierarquia mínima necessária, bastante alta em o que a arquitetura sabe sobre ‘anatomia humana’.
Depois disso, ‘dedos’ podem ser o menor grupo, mesmo que haja 14 partes de dedos/polegar adicionais a considerar ao representar mãos humanas.
Se essa teoria se mantém, não há remédio real, devido à falta de orçamento setorial para anotação manual e à falta de algoritmos adequadamente eficazes que pudessem automatizar a etiquetagem enquanto produziam taxas de erro baixas. Em essência, o modelo pode atualmente estar confiando na consistência anatômica humana para encobrir as deficiências do conjunto de dados em que foi treinado.
Uma possível razão pela qual não pode confiar nisso, recentemente proposta no Discord da Difusão Estável, é que o modelo pode se confundir sobre o número correto de dedos que uma mão humana realística deve ter porque o banco de dados LAION derivado que o alimenta apresenta personagens de desenho animado que podem ter menos dedos (o que é em si um atalho de economia de trabalho).

Dois dos possíveis culpados no ‘sindrome de dedos faltantes’ na Difusão Estável e modelos semelhantes. Abaixo, exemplos de mãos de desenho animado do conjunto de dados LAION-aesthetics que alimenta a Difusão Estável. Fonte: https://www.youtube.com/watch?v=0QZFQ3gbd6I
Se isso for verdade, então a única solução óbvia é retreinar o modelo, excluindo conteúdo humano não realista, garantindo que casos genuínos de omissão (ou seja, amputados) sejam etiquetados como exceções. Do ponto de vista da curadoria de dados, isso seria um desafio considerável, particularmente para esforços comunitários com recursos limitados.
A segunda abordagem seria aplicar filtros que excluam esse conteúdo (ou seja, ‘mão com três/cinco dedos’) de se manifestar no momento da renderização, da mesma maneira que a OpenAI filtrou o GPT-3 e o DALL-E 2, para que sua saída pudesse ser regulamentada sem precisar retreinar os modelos de origem.

Para a Difusão Estável, a distinção semântica entre dígitos e até membros pode se tornar terrivelmente confusa, lembrando o filão de ‘horror corporal’ dos filmes de terror dos anos 80, como os de David Cronenberg. Fonte: https://old.reddit.com/r/StableDiffusion/comments/x6htf6/a_study_of_stable_diffusions_strange_relationship/
No entanto, novamente, isso exigiria etiquetas que podem não existir em todas as imagens afetadas, deixando-nos com o mesmo desafio logístico e orçamentário.
Pode ser argumentado que há duas estradas à frente: jogar mais dados no problema e aplicar sistemas interpretativos de terceiros que possam intervir quando erros físicos do tipo descrito aqui estão sendo apresentados ao usuário final (pelo menos, o último daria à OpenAI um método para fornecer reembolsos por renderizações de ‘horror corporal’, se a empresa estivesse motivada a fazê-lo).
3: Personalização
Uma das possibilidades mais emocionais para o futuro da Difusão Estável é a perspectiva de usuários ou organizações desenvolverem sistemas revisados; modificações que permitem que o conteúdo fora da esfera pré-treinada da LAION seja integrado ao sistema – idealmente sem o custo incontrolável de treinar o modelo inteiro novamente, ou o risco envolvido ao treinar um grande volume de imagens novas em um modelo maduro e capaz.
Por analogia: se dois alunos menos talentosos se juntam a uma turma avançada de trinta alunos, eles ou se assimilarão e pegarão o ritmo, ou falharão como outsiders; em qualquer caso, o desempenho médio da turma provavelmente não será afetado. Se 15 alunos menos talentosos se juntarem, no entanto, a curva de notas da turma inteira provavelmente sofrerá.
Da mesma forma, a rede sinérgica e fairly delicada de relações que são construídas ao longo do treinamento sustentado e caro do modelo pode ser comprometida, em alguns casos efetivamente destruída, por novos dados excessivos, reduzindo a qualidade de saída do modelo em geral.
O caso para fazer isso é principalmente onde seu interesse reside em completamente sequestrar a compreensão conceitual do modelo de relações e coisas, e apropriá-lo para a produção exclusiva de conteúdo que é semelhante ao material adicional que você adicionou.
Assim, treinar 500.000 quadros de Os Simpsons em um checkpoint existente da Difusão Estável provavelmente resultará, eventualmente, em um melhor simulador de Os Simpsons do que a construção original poderia ter oferecido, presumindo que relações semânticas amplas o suficiente sobrevivam ao processo (ou seja, Homer Simpson comendo um cachorro-quente, o que pode exigir material sobre cachorros-quentes que não estava no material adicional, mas já existia no checkpoint), e presumindo que você não queira mudar repentinamente de conteúdo de Os Simpsons para criar paisagem fabulosa de Greg Rutkowski – porque seu modelo pós-treinado teve sua atenção massivamente desviada, e não será tão bom em fazer esse tipo de coisa como costumava ser.
Um exemplo notável disso é o waifu-diffusion, que treinou com sucesso 56.000 imagens de anime em um checkpoint de Difusão Estável treinado e concluído. É uma perspectiva difícil para um hobbyista, no entanto, desde que o modelo exige um mínimo de 30GB de VRAM, muito além do que provavelmente estará disponível na próxima geração de 40XX da NVIDIA.

O treinamento de conteúdo personalizado na Difusão Estável via waifu-diffusion: o modelo levou duas semanas de pós-treinamento para produzir esse nível de ilustração. As seis imagens à esquerda mostram o progresso do modelo, à medida que o treinamento prosseguia, em produzir saída coerente com base nos novos dados de treinamento. Fonte: https://gigazine.net/gsc_news/en/20220121-how-waifu-labs-create/
Um grande esforço pode ser gasto em tais ‘bifurcações’ de checkpoints da Difusão Estável, apenas para ser frustrado pela dívida técnica. Desenvolvedores no Discord oficial já indicaram que lançamentos de checkpoints posteriores não são necessariamente compatíveis com versões anteriores, mesmo com lógica de prompt que pode ter funcionado com uma versão anterior, desde que seu interesse principal é obter o melhor modelo possível, em vez de suportar aplicativos e processos legados.
Portanto, uma empresa ou indivíduo que decide bifurcar um checkpoint em um produto comercial efetivamente não tem como voltar; sua versão do modelo é, a partir desse ponto, uma ‘bifurcação rígida’, e não poderá aproveitar os benefícios upstream de lançamentos posteriores da stability.ai – o que é um compromisso considerável.
A esperança atual e maior para a personalização da Difusão Estável é a Inversão Textual, onde o usuário treina um punhado de CLIP-imagens alinhadas.

Uma colaboração entre a Universidade de Tel Aviv e a NVIDIA, a inversão textual permite o treinamento de entidades discretas e novas, sem destruir as capacidades do modelo de origem. Fonte: https://textual-inversion.github.io/
A limitação aparente da inversão textual é que um número muito baixo de imagens é recomendado – tão baixo quanto cinco. Isso efetivamente produz uma entidade limitada que pode ser mais útil para tarefas de transferência de estilo do que para a inserção de objetos fotorealistas.
No entanto, experimentos estão atualmente ocorrendo dentro dos vários Discords da Difusão Estável que usam números muito maiores de imagens de treinamento, e ainda não se sabe quão produtivo o método pode se provar. Mais uma vez, a técnica exige uma grande quantidade de VRAM, tempo e paciência.
Devido a esses fatores limitantes, podemos ter que esperar um pouco para ver alguns dos experimentos de inversão textual mais sofisticados dos entusiastas da Difusão Estável – e se essa abordagem pode ‘colocá-lo na imagem’ de uma maneira que pareça melhor do que uma colagem do Photoshop, enquanto retém a funcionalidade incrível dos checkpoints oficiais.
Publicado pela primeira vez em 6 de setembro de 2022.












