
AI 101
Co to są CNN (konwolucyjne sieci neuronowe)?
Być może zastanawiałeś się, w jaki sposób Facebook lub Instagram są w stanie automatycznie rozpoznawać twarze na obrazie lub w jaki sposób Google umożliwia wyszukiwanie w Internecie podobnych zdjęć po prostu poprzez przesłanie własnego zdjęcia. Funkcje te są przykładami wizji komputerowej i są zasilane przez konwolucyjne sieci neuronowe (CNN). Czym właściwie są splotowe sieci neuronowe? Przyjrzyjmy się dokładnie architekturze CNN i zrozumiejmy, jak działają.
Co to są sieci neuronowe?
Zanim zaczniemy mówić o splotowych sieciach neuronowych, poświęćmy chwilę na zdefiniowanie regularnej sieci neuronowej. Jest kolejny artykuł na temat dostępnych sieci neuronowych, więc nie będziemy się tutaj zbytnio zagłębiać. Jednak, najkrócej je zdefiniując, są to modele obliczeniowe inspirowane ludzkim mózgiem. Sieć neuronowa działa w oparciu o pobieranie danych i manipulowanie nimi poprzez dostosowywanie „wag”, czyli założeń dotyczących powiązania cech wejściowych ze sobą i klasą obiektu. W miarę uczenia sieci wartości wag są dostosowywane i, miejmy nadzieję, zbiegną się do wag, które dokładnie oddają relacje między cechami.
W ten sposób działa sieć neuronowa ze sprzężeniem zwrotnym, a CNN składają się z dwóch połówek: sieci neuronowej ze sprzężeniem zwrotnym i grupy warstw splotowych.
Co to są splotowe sieci neuronowe (CNN)?
Jakie „zwoje” zachodzą w splotowej sieci neuronowej? Splot to operacja matematyczna, która tworzy zestaw wag, zasadniczo tworząc reprezentację części obrazu. Ten zestaw wag to tzw jądro lub filtr. Utworzony filtr jest mniejszy niż cały obraz wejściowy i obejmuje tylko podsekcję obrazu. Wartości w filtrze są mnożone przez wartości na obrazie. Następnie filtr jest przesuwany, tworząc reprezentację nowej części obrazu, a proces jest powtarzany, aż do pokrycia całego obrazu.
Innym sposobem, aby o tym pomyśleć, jest wyobrażenie sobie ceglanej ściany, w której cegły reprezentują piksele obrazu wejściowego. Wzdłuż ściany przesuwane jest „okno”, które jest filtrem. Cegły widoczne przez okno to piksele, których wartość jest pomnożona przez wartości w filtrze. Z tego powodu tę metodę tworzenia ciężarów z filtrem często nazywa się techniką „przesuwanych okien”.
Dane wyjściowe filtrów przesuwanych po całym obrazie wejściowym to dwuwymiarowa tablica reprezentująca cały obraz. Ta tablica nazywa się a „mapa funkcji”.
Dlaczego zwoje są niezbędne
Jaki w ogóle jest cel tworzenia splotów? Sploty są konieczne, ponieważ sieć neuronowa musi być w stanie zinterpretować piksele na obrazie jako wartości liczbowe. Funkcją warstw splotowych jest konwersja obrazu na wartości liczbowe, które sieć neuronowa może zinterpretować, a następnie wyodrębnić odpowiednie wzorce. Zadaniem filtrów w sieci splotowej jest utworzenie dwuwymiarowej tablicy wartości, które można przekazać do kolejnych warstw sieci neuronowej, czyli tych, które nauczą się wzorców obrazu.
Filtry i kanały
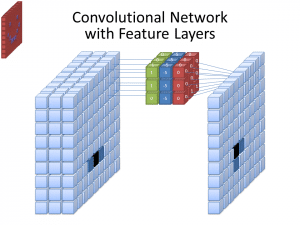
Zdjęcie: cecebur za pośrednictwem Wikimedia Commons, CC BY SA 4.0 (https://commons.wikimedia.org/wiki/File:Convolutional_Neural_Network_NeuralNetworkFeatureLayers.gif)
CNN nie używają tylko jednego filtra do uczenia się wzorców z obrazów wejściowych. Stosowanych jest wiele filtrów, ponieważ różne tablice utworzone przez różne filtry prowadzą do bardziej złożonej, bogatej reprezentacji obrazu wejściowego. Typowe liczby filtrów dla CNN to 32, 64, 128 i 512. Im więcej filtrów, tym więcej możliwości CNN ma do sprawdzenia danych wejściowych i uczenia się na ich podstawie.
CNN analizuje różnice w wartościach pikseli w celu określenia granic obiektów. Na obrazie w skali szarości CNN przyjrzałaby się jedynie różnicom w czerni i bieli, od jasnego do ciemnego. Kiedy obrazy są kolorowe, CNN bierze pod uwagę nie tylko ciemność i światło, ale musi także wziąć pod uwagę trzy różne kanały kolorów – czerwony, zielony i niebieski. W tym przypadku filtry, podobnie jak sam obraz, posiadają 3 kanały. Liczba kanałów w filtrze nazywana jest jego głębokością, a liczba kanałów w filtrze musi odpowiadać liczbie kanałów na obrazie.
Konwolucyjna sieć neuronowa (CNN) Architektura
Przyjrzyjmy się pełnej architekturze splotową sieć neuronową. Na początku każdej sieci splotowej znajduje się warstwa splotowa, ponieważ konieczne jest przekształcenie danych obrazu na tablice numeryczne. Jednakże warstwy splotowe mogą również następować po innych warstwach splotowych, co oznacza, że warstwy te można układać jedna na drugiej. Posiadanie wielu warstw splotowych oznacza, że dane wyjściowe z jednej warstwy mogą podlegać dalszym splotom i być grupowane w odpowiednie wzorce. W praktyce oznacza to, że w miarę przechodzenia danych obrazu przez warstwy splotowe sieć zaczyna „rozpoznawać” bardziej złożone cechy obrazu.
Wczesne warstwy ConvNet są odpowiedzialne za wyodrębnianie cech niskiego poziomu, takich jak piksele tworzące proste linie. Późniejsze warstwy ConvNet połączą te linie w kształty. Proces przechodzenia od analizy na poziomie powierzchni do analizy na poziomie głębokim trwa do momentu, gdy ConvNet rozpozna złożone kształty, takie jak zwierzęta, ludzkie twarze i samochody.
Po przejściu przez wszystkie warstwy splotowe dane trafiają do gęsto połączonej części CNN. Gęsto połączone warstwy wyglądają tak, jak wygląda tradycyjna sieć neuronowa ze sprzężeniem zwrotnym – seria węzłów ułożonych w warstwy, które są ze sobą połączone. Dane przepływają przez te gęsto połączone warstwy, które uczą się wzorców wyodrębnionych przez warstwy splotowe, dzięki czemu sieć staje się zdolna do rozpoznawania obiektów.










