
Best Of
10 najlepszych algorytmów uczenia maszynowego
Chociaż żyjemy w czasach niezwykłych innowacji w uczeniu maszynowym akcelerowanym przez GPU, najnowsze artykuły badawcze często (i w widoczny sposób) przedstawiają algorytmy mające dziesięciolecia, w niektórych przypadkach 70 lat.
Niektórzy mogą twierdzić, że wiele z tych starszych metod należy raczej do obozu „analizy statystycznej” niż uczenia maszynowego i wolą datować pojawienie się tego sektora dopiero na rok 1957, kiedy to wynalezienie Perceptronu.
Biorąc pod uwagę stopień, w jakim te starsze algorytmy wspierają najnowsze trendy i przyciągające uwagę zmiany w uczeniu maszynowym oraz są w nie wplecione, jest to stanowisko dyskusyjne. Przyjrzyjmy się zatem niektórym „klasycznym” elementom stanowiącym podstawę najnowszych innowacji, a także nowszym wpisom, które już ubiegają się o miejsce w galerii sław sztucznej inteligencji.
1: Transformatory
W 2017 r. zespół badawczy Google przeprowadził współpracę badawczą, której kulminacją było: papier Uwaga jest wszystkim, czego potrzebujesz. W pracy nakreślono nowatorską architekturę, która promowała mechanizmy uwagi od „rurociągu” w koderze/dekoderze i modelach sieci rekurencyjnej do samodzielnej centralnej technologii transformacyjnej.
Podejście zostało nazwane Transformatori od tego czasu stała się rewolucyjną metodologią przetwarzania języka naturalnego (NLP), wspierając między innymi autoregresyjny model języka i plakat-dziecko AI GPT-3.
![]()
Transformatory elegancko rozwiązały problem transdukcja sekwencji, zwana także „transformacją”, która polega na przetwarzaniu sekwencji wejściowych na sekwencje wyjściowe. Transformator odbiera również dane i zarządza nimi w sposób ciągły, a nie sekwencyjnymi partiami, co pozwala na „trwałość pamięci”, do uzyskania której architektury RNN nie są zaprojektowane. Aby uzyskać bardziej szczegółowy przegląd transformatorów, spójrz na nasz artykuł referencyjny.
W przeciwieństwie do rekurencyjnych sieci neuronowych (RNN), które zaczęły dominować w badaniach nad ML w erze CUDA, architekturę transformatorów można również łatwo zrównoleglony, otwierając drogę do produktywnego przetwarzania znacznie większego zbioru danych niż RNN.
Popularne użycie
Transformers pobudziły wyobraźnię opinii publicznej w 2020 roku wraz z wydaniem GPT-3 OpenAI, który mógł poszczycić się rekordowym wówczas 175 miliarda parametrów. To pozornie zdumiewające osiągnięcie zostało ostatecznie przyćmione przez późniejsze projekty, takie jak projekt 2021 zwolnić układu Megatron-Turing NLG 530B firmy Microsoft, który (jak sama nazwa wskazuje) zawiera ponad 530 miliardów parametrów.

Kalendarium hiperskalowych projektów Transformer NLP. Źródło: Microsoft
Architektura transformatorowa również przeszła od NLP do wizji komputerowej, zasilając m.in nowe pokolenie platform syntezy obrazu, takich jak OpenAI CLIP i DALL-E, które korzystają z mapowania domeny tekst>obraz w celu wykańczania niekompletnych obrazów i syntezy nowych obrazów z wyszkolonych domen wśród rosnącej liczby powiązanych aplikacji.

DALL-E podejmuje próbę uzupełnienia częściowego obrazu popiersia Platona. Źródło: https://openai.com/blog/dall-e/
2: Generacyjne sieci przeciwstawne (GAN)
Chociaż transformatory zyskały niezwykłe zainteresowanie mediów dzięki wydaniu i przyjęciu GPT-3, Generatywna sieć przeciwników (GAN) stała się rozpoznawalną marką samą w sobie i może ostatecznie do niej dołączyć Deepfake jako czasownik.
Pierwsza propozycja w 2014 i używany głównie do syntezy obrazu, generatywnej sieci kontradyktoryjnej architektura składa się z generator oraz Dyskryminator. Generator przegląda tysiące obrazów w zestawie danych, iteracyjnie próbując je zrekonstruować. Przy każdej próbie Dyskryminator ocenia pracę Generatora i odsyła go z powrotem, aby działał lepiej, ale bez żadnego wglądu w to, w jaki sposób poprzednia rekonstrukcja zawiodła.

Źródło: https://developers.google.com/machine-learning/gan/gan_structure
Zmusza to Generator do zbadania wielu dróg, zamiast podążać potencjalnymi ślepymi uliczkami, które powstałyby, gdyby Dyskryminator powiedział mu, gdzie idzie źle (patrz punkt 8 poniżej). Do czasu zakończenia uczenia Generator dysponuje szczegółową i kompleksową mapą relacji pomiędzy punktami w zbiorze danych.

Z papieru Poprawa równowagi GAN poprzez podniesienie świadomości przestrzennej: nowatorska struktura porusza się po czasami tajemniczej, ukrytej przestrzeni sieci GAN, zapewniając responsywne narzędzie dla architektury syntezy obrazu. Źródło: https://genforce.github.io/eqgan/
Analogicznie, na tym polega różnica pomiędzy nauką podczas jednej, nudnej podróży do centrum Londynu, a żmudnym zdobywaniem wiedzy Wiedza.
Rezultatem jest zbiór funkcji wysokiego poziomu w ukrytej przestrzeni wyszkolonego modelu. Wskaźnikiem semantycznym cechy wysokiego poziomu może być „osoba”, podczas gdy przejście przez specyfikę związaną z tą cechą może ujawnić inne wyuczone cechy, takie jak „męski” i „żeński”. Na niższych poziomach cechy podrzędne można podzielić na „blond”, „kaukaski” i in.
Splątanie jest istotna kwestia w ukrytej przestrzeni GAN i struktur koderów/dekoderów: czy uśmiech na kobiecej twarzy wygenerowanej przez GAN jest uwikłaną cechą jej „tożsamości” w ukrytej przestrzeni, czy też jest to gałąź równoległa?

Twarze tej osoby wygenerowane przez GAN nie istnieją. Źródło: https://this-person-does-not-exist.com/en
Ostatnie kilka lat przyniosło rosnącą liczbę nowych inicjatyw badawczych w tym zakresie, być może torując drogę do edycji na poziomie funkcji w stylu Photoshopa ukrytej przestrzeni GAN, ale obecnie wiele transformacji jest skutecznie „ pakiety „wszystko albo nic”. Warto zauważyć, że wersja EditGAN firmy NVIDIA z końca 2021 r wysoki poziom interpretowalności w przestrzeni ukrytej za pomocą semantycznych masek segmentacji.
Popularne użycie
Oprócz (właściwie dość ograniczonego) zaangażowania w popularne filmy typu deepfake, w ciągu ostatnich czterech lat sieci GAN skupiające się na obrazach/wideo rozprzestrzeniły się, fascynując zarówno badaczy, jak i opinię publiczną. Nadążanie za zawrotną szybkością i częstotliwością nowych wydań jest wyzwaniem, chociaż repozytorium GitHub Niesamowite aplikacje GAN ma na celu przedstawienie wyczerpującej listy.
Generacyjne sieci przeciwstawne mogą teoretycznie czerpać cechy z dowolnej dobrze zorganizowanej domeny, łącznie z tekstem.
3: SVM
Pochodzi w 1963, Maszyna wektorów nośnych (SVM) to podstawowy algorytm, który często pojawia się w nowych badaniach. W SVM wektory odwzorowują względne rozmieszczenie punktów danych w zbiorze danych, natomiast wsparcie wektory wyznaczają granice pomiędzy różnymi grupami, cechami lub cechami.
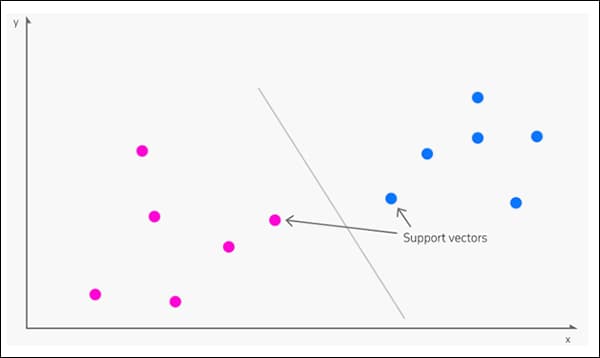
Wektory wsparcia definiują granice pomiędzy grupami. Źródło: https://www.kdnuggets.com/2016/07/support-vector-machines-simple-explanation.html
Wyprowadzona granica nazywa się a hiperpłaszczyzna.
Na niskich poziomach funkcji SVM jest dwuwymiarowy (obrazek powyżej), ale tam, gdzie istnieje większa liczba rozpoznanych grup lub typów, tak się dzieje trójwymiarowy.

Głębszy układ punktów i grup wymaga trójwymiarowego SVM. Źródło: https://cml.rhul.ac.uk/svm.html
Popularne użycie
Ponieważ maszyny wektorów pomocniczych mogą skutecznie i agnostycznie adresować wielowymiarowe dane wielowymiarowe, pojawiają się one powszechnie w różnych sektorach uczenia maszynowego, w tym wykrywanie deepfake'ów, klasyfikacja obrazu, Klasyfikacja mowy nienawiści, Analiza DNA i przewidywanie struktury populacji, wśród wielu innych.
4: Grupowanie K-średnich
Klastrowanie jest ogólnie rzecz biorąc uczenie się bez nadzoru podejście, które ma na celu kategoryzację punktów danych poprzez oszacowanie gęstości, tworząc mapę rozkładu badanych danych.

Grupowanie K-średnich pozwala wyodrębnić segmenty, grupy i społeczności w danych. Źródło: https://aws.amazon.com/blogs/machine-learning/k-means-clustering-with-amazon-sagemaker/
Klastrowanie K-średnich stało się najpopularniejszą implementacją tego podejścia, grupując punkty danych w charakterystyczne „grupy K”, które mogą wskazywać sektory demograficzne, społeczności internetowe lub jakąkolwiek inną możliwą tajną agregację czekającą na odkrycie w surowych danych statystycznych.

W analizie K-średnich tworzą się klastry. Źródło: https://www.geeksforgeeks.org/ml-determine-the-optimal-value-of-k-in-k-means-clustering/
Sama wartość K jest czynnikiem determinującym użyteczność procesu i ustalenie optymalnej wartości klastra. Początkowo wartość K jest przydzielana losowo, a jej cechy i cechy wektora porównywane są z sąsiadami. Sąsiedzi, którzy najbardziej przypominają punkt danych z losowo przypisaną wartością, są przypisywani do jego klastra iteracyjnie, dopóki dane nie uzyskają wszystkich grupowań, na jakie pozwala proces.
Wykres błędu kwadratowego, czyli „kosztu” różnych wartości pomiędzy klastrami, ujawni: punkt łokciowy dla danych:

„Punkt łokciowy” na wykresie skupień. Źródło: https://www.scikit-yb.org/en/latest/api/cluster/elbow.html
Punkt łokciowy ma podobną koncepcję do sposobu, w jaki strata wyrównuje się do malejących zysków pod koniec sesji szkoleniowej dla zbioru danych. Reprezentuje moment, w którym nie staną się widoczne żadne dalsze różnice między grupami, wskazując moment, w którym należy przejść do kolejnych faz potoku danych lub zgłosić ustalenia.
Popularne użycie
Klastrowanie K-Means z oczywistych powodów jest podstawową technologią w analizie klientów, ponieważ oferuje jasną i łatwą do wyjaśnienia metodologię przekładania dużych ilości danych handlowych na spostrzeżenia demograficzne i „potencjalnych klientów”.
Poza tym zastosowaniem stosuje się także grupowanie K-średnich przewidywanie osuwisk, segmentacja obrazu medycznego, synteza obrazu za pomocą GAN, klasyfikacja dokumentów, planowanie miasta, wśród wielu innych potencjalnych i rzeczywistych zastosowań.
5: Losowy las
Losowy Las to kompletne uczenie się metoda, która uśrednia wynik z tablicy drzewa decyzyjne w celu ustalenia ogólnej prognozy wyniku.

Źródło: https://www.tutorialandexample.com/wp-content/uploads/2019/10/Decision-Trees-Root-Node.png
Jeśli badałeś to nawet tak mało, jak oglądanie Powrót do przyszłości trylogii samo drzewo decyzyjne jest dość łatwe do konceptualizacji: przed tobą leży wiele ścieżek, a każda ścieżka rozgałęzia się, prowadząc do nowego wyniku, który z kolei zawiera dalsze możliwe ścieżki.
In uczenie się wzmacnianiamożesz wycofać się ze ścieżki i zacząć ponownie od wcześniejszej pozycji, podczas gdy drzewa decyzyjne kontynuują swoją podróż.
Zatem algorytm Random Forest zasadniczo opiera się na obstawianiu decyzji. Algorytm nazywa się „losowym”, ponieważ tworzy doraźnie selekcji i obserwacji, aby zrozumieć mediana suma wyników z tablicy drzewa decyzyjnego.
Ponieważ uwzględnia wiele czynników, podejście Random Forest może być trudniejsze do przekształcenia w znaczące wykresy niż drzewo decyzyjne, ale prawdopodobnie będzie znacznie bardziej produktywne.
Drzewa decyzyjne podlegają nadmiernemu dopasowaniu, gdy uzyskane wyniki są specyficzne dla danych i nie podlegają uogólnieniu. Dowolny wybór punktów danych przez Random Forest zwalcza tę tendencję, drążąc w kierunku znaczących i użytecznych reprezentatywnych trendów w danych.

Regresja drzewa decyzyjnego. Źródło: https://scikit-learn.org/stable/auto_examples/tree/plot_tree_regression.html
Popularne użycie
Podobnie jak wiele algorytmów z tej listy, Random Forest zazwyczaj działa jako „wczesny” sortownik i filtr danych i jako taki stale pojawia się w nowych artykułach naukowych. Oto niektóre przykłady użycia Losowego Lasu Synteza obrazu rezonansu magnetycznego, Prognozowanie ceny bitcoinów, segmentacja spisowa, klasyfikacja tekstu i wykrywanie oszustw związanych z kartami kredytowymi.
Ponieważ Random Forest jest algorytmem niskiego poziomu w architekturach uczenia maszynowego, może również przyczyniać się do wydajności innych metod niskiego poziomu, a także algorytmów wizualizacji, w tym Klastrowanie indukcyjne, Transformacje funkcji, klasyfikacja dokumentów tekstowych używając rzadkich funkcji, wyświetlanie rurociągów.
6: Naiwny Bayes
W połączeniu z oceną gęstości (patrz 4, powyżej naiwny Bayes klasyfikator to potężny, ale stosunkowo lekki algorytm zdolny do szacowania prawdopodobieństw na podstawie obliczonych cech danych.

Relacje cech w naiwnym klasyfikatorze Bayesa. Źródło: https://www.sciencedirect.com/topics/computer-science/naive-bayes-model
Termin „naiwny” odnosi się do założenia w Twierdzenie Bayesa funkcje te są ze sobą niepowiązane, tzw niezależność warunkowa. Jeśli przyjmiemy ten punkt widzenia, chodzenie i mówienie jak kaczka nie wystarczy, aby stwierdzić, że mamy do czynienia z kaczką, i nie przyjmuje się przedwcześnie żadnych „oczywistych” założeń.
Taki poziom rygoru akademickiego i dochodzeniowego byłby przesadą, gdy dostępny jest „zdrowy rozsądek”, ale stanowi cenny standard przy pokonywaniu wielu niejasności i potencjalnie niepowiązanych korelacji, które mogą istnieć w zbiorze danych uczenia maszynowego.
W oryginalnej sieci Bayesa funkcje podlegają funkcje punktacji, łącznie z minimalną długością opisu i Punktacja Bayesa, co może nakładać ograniczenia na dane pod względem szacowanych połączeń znalezionych między punktami danych oraz kierunku, w którym te połączenia przepływają.
Z kolei naiwny klasyfikator Bayesa działa w oparciu o założenie, że cechy danego obiektu są niezależne, a następnie wykorzystuje twierdzenie Bayesa do obliczenia prawdopodobieństwa wystąpienia danego obiektu na podstawie jego cech.
Popularne użycie
Naiwne filtry Bayesa są dobrze reprezentowane w przewidywanie chorób i kategoryzacja dokumentów, filtrowanie spamu, klasyfikacja nastrojów, systemy rekomendujące, wykrywanie oszustw, wśród innych aplikacji.
7: K – Najbliżsi sąsiedzi (KNN)
Po raz pierwszy zaproponowany przez Szkołę Medycyny Lotniczej Sił Powietrznych Stanów Zjednoczonych w 1951oraz konieczność dostosowania się do najnowocześniejszego sprzętu komputerowego z połowy XX wieku, K-Najbliżsi sąsiedzi (KNN) to uproszczony algorytm, który nadal zajmuje ważne miejsce w artykułach akademickich i inicjatywach badawczych w zakresie uczenia maszynowego w sektorze prywatnym.
KNN został nazwany „leniwym uczniem”, ponieważ wyczerpująco skanuje zbiór danych w celu oceny relacji między punktami danych, zamiast wymagać szkolenia w zakresie pełnoprawnego modelu uczenia maszynowego.

Grupa KNN. Źródło: https://scikit-learn.org/stable/modules/neighbors.html
Chociaż KNN jest smukły architektonicznie, jego systematyczne podejście rzeczywiście nakłada znaczne wymagania na operacje odczytu/zapisu, a jego użycie w bardzo dużych zbiorach danych może być problematyczne bez technologii pomocniczych, takich jak analiza głównych składowych (PCA), które mogą przekształcać złożone zbiory danych o dużej objętości do ugrupowania reprezentatywne którą KNN może pokonać przy mniejszym wysiłku.
A Ostatnie badania ocenił skuteczność i ekonomię szeregu algorytmów, których zadaniem było przewidzenie, czy pracownik odejdzie z firmy, i stwierdził, że siedmioletni KNN w dalszym ciągu przewyższa bardziej nowoczesnych konkurentów pod względem dokładności i skuteczności przewidywania.
Popularne użycie
Pomimo całej swojej popularnej prostoty koncepcji i wykonania, KNN nie utknął w latach pięćdziesiątych – został zaadaptowany podejście bardziej skoncentrowane na DNN w propozycji Pennsylvania State University z 2018 r. i pozostaje centralnym procesem na wczesnym etapie (lub narzędziem analitycznym przetwarzania końcowego) w wielu znacznie bardziej złożonych ramach uczenia maszynowego.
W różnych konfiguracjach zastosowano KNN lub do weryfikacja podpisu online, klasyfikacja obrazu, eksploracja tekstu, przewidywanie upraw, rozpoznawanie twarzy, oprócz innych zastosowań i inkorporacji.

System rozpoznawania twarzy oparty na KNN w szkoleniu. Source: https://pdfs.semanticscholar.org/6f3d/d4c5ffeb3ce74bf57342861686944490f513.pdf
8: Proces decyzyjny Markowa (MDP)
Ramy matematyczne wprowadzone przez amerykańskiego matematyka Richarda Bellmana w 1957Proces decyzyjny Markowa (MDP) jest jednym z najbardziej podstawowych bloków uczenie się wzmacniania architektury. Algorytm koncepcyjny sam w sobie, został zaadaptowany do wielu innych algorytmów i często pojawia się w bieżących badaniach nad sztuczną inteligencją/uczeniem się.
MDP bada środowisko danych, korzystając z oceny jego bieżącego stanu (tj. „gdzie” znajduje się w danych), aby zdecydować, który węzeł danych ma zostać zbadany w następnej kolejności.

Źródło: https://www.sciencedirect.com/science/article/abs/pii/S0888613X18304420
Podstawowy proces decyzyjny Markowa będzie priorytetyzował krótkoterminową przewagę nad bardziej pożądanymi celami długoterminowymi. Z tego powodu jest ono zwykle osadzone w kontekście bardziej kompleksowej architektury polityki w zakresie uczenia się przez wzmacnianie i często podlega czynnikom ograniczającym, takim jak nagroda ze zniżkąoraz inne modyfikujące zmienne środowiskowe, które uniemożliwiają pośpiech w kierunku natychmiastowego celu bez uwzględnienia szerszego pożądanego rezultatu.
Popularne użycie
Koncepcja niskiego poziomu MDP jest szeroko rozpowszechniona zarówno w badaniach, jak i w aktywnych wdrożeniach uczenia maszynowego. Zaproponowano dla Systemy obrony bezpieczeństwa IoT, zbieranie ryb, prognozowanie rynku.
Poza tym oczywiste zastosowanie do szachów i innych gier ściśle sekwencyjnych, MDP jest także naturalnym pretendentem do tytułu szkolenie proceduralne systemów robotykijak widać na poniższym filmie.

9: Częstotliwość terminu – odwrotna częstotliwość dokumentu
Termin Częstotliwość (TF) dzieli liczbę wystąpień słowa w dokumencie przez całkowitą liczbę słów w tym dokumencie. Stąd słowo uszczelnić występowanie raz w artykule zawierającym tysiąc słów ma częstotliwość występowania wynoszącą 0.001. Sam TF jest w dużej mierze bezużyteczny jako wskaźnik ważności terminu, ponieważ artykuły pozbawione znaczenia (takie jak a, i, dotychczasowy, it) przeważają.
Aby uzyskać znaczącą wartość terminu, funkcja Inverse Document Frequency (IDF) oblicza TF słowa w wielu dokumentach w zbiorze danych, przypisując niską ocenę bardzo wysokiej częstotliwości pomijane słowa, takie jak artykuły. Powstałe wektory cech są normalizowane do wartości całkowitych, przy czym każdemu słowu przypisuje się odpowiednią wagę.

TF-IDF waży trafność terminów na podstawie częstotliwości ich występowania w wielu dokumentach, przy czym rzadsze występowanie jest wskaźnikiem istotności. Źródło: https://moz.com/blog/inverse-document-frequency-and-the-importance-of-uniqueness
Chociaż takie podejście zapobiega utracie semantycznie ważnych słów jako wartości odstające, odwrócenie wagi częstotliwości nie oznacza automatycznie, że termin o niskiej częstotliwości jest nie wartość odstająca, ponieważ niektóre rzeczy są rzadkie i Bezwartościowy. Dlatego też termin występujący rzadko będzie musiał udowodnić swoją wartość w szerszym kontekście architektonicznym poprzez zamieszczenie (nawet przy małej częstotliwości na dokument) w wielu dokumentach w zbiorze danych.
Pomimo tego wiek, TF-IDF to potężna i popularna metoda wstępnego filtrowania przebiegów w frameworkach przetwarzania języka naturalnego.
Popularne użycie
Ponieważ TF-IDF odegrało przynajmniej pewną rolę w rozwoju w dużej mierze tajnego algorytmu Google PageRank w ciągu ostatnich dwudziestu lat, stało się ono bardzo powszechnie przyjęte jako manipulacyjna taktyka SEO, pomimo Johna Muellera z 2019 r wyparcie jego znaczenie dla wyników wyszukiwania.
Ze względu na tajemnicę PageRank, nie ma jednoznacznych dowodów na to, że TF-IDF jest nie obecnie skuteczna taktyka na podniesienie pozycji w rankingach Google. Zapalający dyskusja wśród specjalistów IT wskazuje ostatnio na powszechne przekonanie, prawidłowe lub nie, że nadużywanie terminów może nadal skutkować poprawą pozycjonowania SEO (choć dodatkowo oskarżenia o nadużycie monopolu i nadmierna reklama zacierają granice tej teorii).
10: Stochastyczne zejście gradientowe
Stochastyczne zejście gradientowe (SGD) to coraz popularniejsza metoda optymalizacji uczenia modeli uczenia maszynowego.
Gradient Descent sam w sobie jest metodą optymalizacji, a następnie ilościowego określenia poprawy wprowadzanej przez model podczas uczenia.
W tym sensie „gradient” wskazuje nachylenie w dół (a nie gradację opartą na kolorze, patrz ilustracja poniżej), gdzie najwyższy punkt „wzgórza” po lewej stronie oznacza początek procesu uczenia się. Na tym etapie model ani razu nie widział jeszcze całości danych i nie nauczył się wystarczająco dużo o relacjach między danymi, aby uzyskać efektywne przekształcenia.

Zejście gradientowe podczas sesji treningowej FaceSwap. Widzimy, że w drugiej połowie trening ustabilizował się na pewien czas, ale ostatecznie powrócił na ścieżkę spadkową w kierunku akceptowalnej konwergencji.
Najniższy punkt po prawej stronie reprezentuje zbieżność (punkt, w którym model jest tak efektywny, jak nigdy dotąd, przy narzuconych ograniczeniach i ustawieniach).
Gradient pełni rolę zapisu i predyktora rozbieżności między poziomem błędu (jak dokładnie model aktualnie odwzorowuje relacje między danymi) a wagami (ustawieniami wpływającymi na sposób uczenia się modelu).
Ten zapis postępu można wykorzystać do informowania: harmonogram kursu nauki, automatyczny proces, który nakazuje architekturze stać się bardziej szczegółową i precyzyjną, w miarę jak wczesne, niejasne szczegóły przekształcają się w wyraźne relacje i odwzorowania. W efekcie utrata gradientu zapewnia mapę dokładnie na czas, gdzie trening powinien przebiegać dalej i jak powinien przebiegać.
Innowacją stochastycznego opadania gradientu jest to, że aktualizuje parametry modelu w każdym przykładzie szkoleniowym w każdej iteracji, co ogólnie przyspiesza podróż do zbieżności. W związku z pojawieniem się w ostatnich latach hiperskalowych zbiorów danych, popularność SGD wzrosła ostatnio jako jedna z możliwych metod rozwiązania wynikających z tego problemów logistycznych.
Z drugiej strony SGD tak negatywne konsekwencje do skalowania cech i może wymagać większej liczby iteracji, aby osiągnąć ten sam wynik, co wymaga dodatkowego planowania i dodatkowych parametrów w porównaniu do zwykłego opadania gradientowego.
Popularne użycie
Ze względu na swoją konfigurowalność i pomimo swoich wad, SGD stał się najpopularniejszym algorytmem optymalizacji dopasowywania sieci neuronowych. Jedną z konfiguracji SGD, która staje się dominująca w nowych artykułach badawczych AI/ML, jest wybór adaptacyjnej oceny momentu (ADAM, wprowadzony w 2015) optymalizator.
ADAM dynamicznie dostosowuje szybkość uczenia się każdego parametru („adaptacyjna szybkość uczenia się”), a także włącza wyniki z poprzednich aktualizacji do kolejnej konfiguracji („pęd”). Dodatkowo można go skonfigurować tak, aby korzystał z późniejszych innowacji, takich jak Impet Niestierowa.
Niektórzy jednak utrzymują, że użycie pędu może również przyspieszyć program ADAM (i podobne algorytmy) do: wniosek suboptymalny. Podobnie jak w przypadku większości nowatorskich rozwiązań w sektorze badań nad uczeniem maszynowym, prace nad SGD są w toku.
Opublikowano po raz pierwszy 10 lutego 2022 r. Zmieniono 10 lutego 20.05 EET – formatowanie.















