
Artificial Intelligence
RigNeRF: nowa metoda Deepfakes wykorzystująca neuronowe pola promieniowania

Nowe badania opracowane w firmie Adobe oferują pierwszą realną i skuteczną metodę deepfakes opartą na Neuronowe pola promieniowania (NeRF) – być może pierwsza prawdziwa innowacja w architekturze lub podejściu w ciągu pięciu lat od pojawienia się deepfakes w 2017 roku.
Metoda pt RigNeRF, używa Morfowalne modele twarzy 3D (3DMM) jako śródmiąższowa warstwa instrumentalna pomiędzy pożądanym wejściem (tj. tożsamością, która ma zostać narzucona w renderowaniu NeRF) a przestrzenią neuronową; metoda ta została opracowana powszechnie przyjęte w ostatnich latach opracowane przez Generative Adversarial Network (GAN) metody syntezy twarzy, z których żadna nie stworzyła jeszcze funkcjonalnych i użytecznych ram wymiany twarzy dla wideo.

W przeciwieństwie do tradycyjnych filmów typu deepfake, żadna z pokazanych tu ruchomych treści nie jest „prawdziwa”, a raczej możliwa do eksploracji przestrzeń neuronowa wyszkolona na podstawie krótkiego materiału filmowego. Po prawej stronie widzimy trójwymiarowy model twarzy z możliwością morfowania (3DMM), działający jako interfejs pomiędzy pożądanymi manipulacjami („uśmiech”, „patrzenie w lewo”, „patrzenie w górę” itp.) a zwykle trudnymi do ustalenia parametrami pola blasku neuronowego wyobrażanie sobie. Wersja tego klipu w wysokiej rozdzielczości oraz inne przykłady można znaleźć w witrynie strona projektulub osadzone filmy wideo na końcu tego artykułu. Źródło: https://shahrukhathar.github.io/2022/06/06/RigNeRF.html
3DMM to w rzeczywistości modele CGI twarzy, których parametry można dostosować do bardziej abstrakcyjnych systemów syntezy obrazu, takich jak NeRF i GAN, które w innym przypadku byłyby trudne do kontrolowania.
To, co widzicie na powyższym obrazku (środkowy obraz, mężczyzna w niebieskiej koszuli), a także na obrazku bezpośrednio poniżej (po lewej stronie, mężczyzna w niebieskiej koszuli), nie jest „prawdziwym” filmem, na którym widać małą plamkę „ nałożono fałszywą twarz, ale jest to całkowicie syntetyzowana scena, która istnieje wyłącznie jako wolumetryczny rendering neuronowy – obejmujący ciało i tło:

W powyższym przykładzie rzeczywisty film po prawej stronie (kobieta w czerwonej sukience) służy do „marionetkowania” przechwyconej tożsamości (mężczyzna w niebieskiej koszuli) po lewej stronie za pośrednictwem RigNeRF, co (według autorów) jest pierwszym System oparty na NeRF umożliwiający oddzielenie pozycji i ekspresji przy jednoczesnej możliwości przeprowadzania nowatorskiej syntezy widoków.
Męska postać po lewej stronie na powyższym obrazku została „uchwycona” z 70-sekundowego filmu wykonanego smartfonem, a dane wejściowe (w tym informacje o całej scenie) zostały następnie przetrenowane na 4 procesorach graficznych V100 w celu uzyskania tej sceny.
Ponieważ dostępne są również zestawy parametryczne w stylu 3DMM Parametryczne proxy CGI całego ciała (a nie tylko platformy do twarzy), RigNeRF potencjalnie otwiera możliwość tworzenia deepfakesów obejmujących całe ciało, w których prawdziwy ludzki ruch, tekstura i ekspresja są przekazywane do warstwy parametrycznej opartej na CGI, która następnie przekładałaby akcję i ekspresję na renderowane środowiska i filmy NeRF .
A jeśli chodzi o RigNeRF – czy kwalifikuje się ona jako metoda deepfake w obecnym sensie, w jakim nagłówki rozumieją ten termin? A może jest to po prostu kolejny na wpół utykający problem, który również trafił do DeepFaceLab i innych pracochłonnych systemów deepfake z autoenkoderem z 2017 roku?
Badacze pracujący nad nowym artykułem są w tej kwestii jednoznaczni:
„Będąc metodą zdolną do ożywienia twarzy, RigNeRF jest podatny na niewłaściwe wykorzystanie przez złych aktorów w celu generowania głębokich podróbek”.
Nowa papier jest zatytułowany RigNeRF: w pełni kontrolowane portrety neuronowe 3Di pochodzi od ShahRukha Athy z Uniwersytetu Stonybrook, stażysty w Adobe podczas opracowywania RigNeRF, oraz czterech innych autorów z Adobe Research.
Więcej niż Deepfakes oparte na autoenkoderze
Większość wirusowych deepfakes, które w ciągu ostatnich kilku lat trafiły na pierwsze strony gazet, jest tworzona przez autokoderoparte na systemach, wywodzące się z kodu opublikowanego na szybko zakazanym subreddicie r/deepfakes w 2017 r. – choć nie wcześniej skopiowane do GitHuba, gdzie obecnie został rozwidlony ponad tysiąc razy, zwłaszcza popularne (jeśli kontrowersyjny) GłębokaTwarzLab dystrybucja, a także Zamiana twarzy projekt.
Oprócz GAN i NeRF w ramach struktur autoenkodera eksperymentowano również z modułami 3DMM jako „wytycznymi” dotyczącymi ulepszonych struktur syntezy twarzy. Przykładem tego jest Projekt HifiFace od lipca 2021 r. Nie wydaje się jednak, aby w oparciu o to podejście powstały dotychczas żadne użyteczne lub popularne inicjatywy.
Dane dla scen RigNeRF są uzyskiwane poprzez przechwytywanie krótkich filmów smartfonem. W ramach projektu badacze z RigNeRF we wszystkich eksperymentach używali iPhone'a XR lub iPhone'a 12. Przez pierwszą połowę ujęcia obiekt jest proszony o wykonanie szerokiego zakresu mimiki i mowy, trzymając głowę nieruchomo, gdy kamera porusza się wokół niej.
W drugiej połowie ujęcia aparat pozostaje w stałej pozycji, podczas gdy fotografowana osoba musi poruszać głową, wykazując przy tym szeroką gamę wyrazu twarzy. Powstały materiał filmowy trwający 40–70 sekund (około 1200–2100 klatek) reprezentuje cały zbiór danych, który zostanie wykorzystany do uczenia modelu.
Ogranicz gromadzenie danych
Z kolei systemy autokodera, takie jak DeepFaceLab, wymagają stosunkowo pracochłonnego gromadzenia i selekcji tysięcy różnorodnych zdjęć, często pobranych z filmów na YouTube i innych kanałach mediów społecznościowych, a także z filmów (w przypadku deepfakes gwiazd).
Powstałe w ten sposób wyszkolone modele autoenkodera są często przeznaczone do użycia w różnych sytuacjach. Jednak najbardziej wybredni deepfakerzy „celebryci” mogą trenować całe modele od zera na potrzeby jednego filmu, mimo że szkolenie może trwać tydzień lub dłużej.
Pomimo ostrzeżeń badaczy zajmujących się nowym artykułem, wydaje się mało prawdopodobne, aby „patchwork” i szeroko zebrane zbiory danych, które napędzają pornografię AI, a także popularne „deepfake recastingi” w YouTube/TikTok, przyniosły akceptowalne i spójne wyniki w systemie deepfake, takim jak RigNeRF. który ma metodologię specyficzną dla sceny. Biorąc pod uwagę ograniczenia dotyczące przechwytywania danych przedstawione w nowej pracy, może to w pewnym stopniu okazać się dodatkowym zabezpieczeniem przed przypadkowym sprzeniewierzeniem tożsamości przez złośliwych deepfakerów.
Dostosowanie NeRF do Deepfake Video
NeRF to metoda oparta na fotogrametrii, w której niewielka liczba zdjęć źródłowych wykonanych z różnych punktów widzenia jest składana w możliwą do eksploracji trójwymiarową przestrzeń neuronową. Podejście to zyskało na znaczeniu na początku tego roku, kiedy firma NVIDIA zaprezentowała swoje rozwiązanie Natychmiastowy NeRF system, który jest w stanie skrócić wygórowany czas szkolenia NeRF do minut, a nawet sekund:

Natychmiastowy NeRF. Źródło: https://www.youtube.com/watch?v=DJ2hcC1orc4
Powstała scena Neural Radiance Field jest zasadniczo statycznym środowiskiem, które można zbadać, ale tak jest trudne do edycji. Naukowcy zauważają, że dwie wcześniejsze inicjatywy oparte na NeRF – HyperNeRF + E/P i NerFACE – podjęli próbę syntezy wideo twarzy i (najwyraźniej ze względu na kompletność i staranność) porównali RigNeRF z tymi dwoma frameworkami w rundzie testowej:


Jakościowe porównanie RigNeRF, HyperNeRF i NerFACE. Zobacz powiązane filmy źródłowe i pliki PDF, aby uzyskać wersje o wyższej jakości. Źródło obrazu statycznego: https://arxiv.org/pdf/2012.03065.pdf
Jednakże w tym przypadku wyniki faworyzujące RigNeRF są dość nietypowe z dwóch powodów: po pierwsze, autorzy zauważają, że „nie ma istniejących prac porównujących jabłka z jabłkami”; po drugie, spowodowało to konieczność ograniczenia możliwości RigNeRF, aby przynajmniej częściowo odpowiadały bardziej ograniczonej funkcjonalności poprzednich systemów.
Ponieważ wyniki nie stanowią stopniowej poprawy w stosunku do wcześniejszych prac, ale raczej stanowią „przełom” w edytowalności i użyteczności NeRF, odłożymy rundę testową na bok i zamiast tego zobaczymy, co RigNeRF robi inaczej od swoich poprzedników.
Połączone mocne strony
Podstawowym ograniczeniem NerFACE, który może kontrolować pozę/ekspresję w środowisku NeRF, jest założenie, że materiał źródłowy będzie rejestrowany statyczną kamerą. Oznacza to w praktyce, że nie może generować nowatorskich poglądów wykraczających poza ograniczenia jego przechwytywania. W ten sposób powstaje system, który może tworzyć „ruchome portrety”, ale który nie nadaje się do filmów w stylu deepfake.
Z drugiej strony HyperNeRF, choć jest w stanie generować nowatorskie i hiperrealistyczne widoki, nie dysponuje instrumentami pozwalającymi na zmianę pozycji głowy lub wyrazu twarzy, co z kolei nie powoduje, że stanowi jakąkolwiek konkurencję dla deepfake'ów opartych na autoenkoderach.
RigNeRF jest w stanie połączyć te dwie izolowane funkcjonalności, tworząc „przestrzeń kanoniczną”, domyślną linię bazową, od której można wprowadzić odchylenia i deformacje poprzez dane wejściowe z modułu 3DMM.
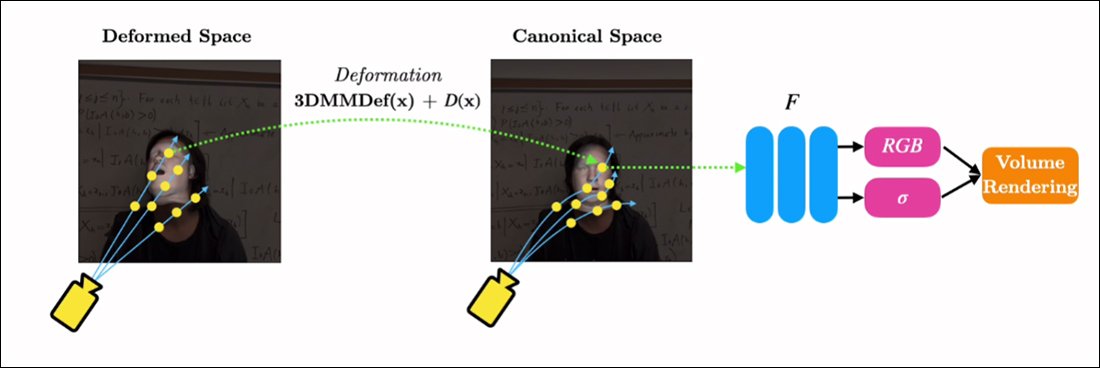
Tworzenie „przestrzeni kanonicznej” (bez pozy, bez ekspresji), na którą mogą oddziaływać deformacje (tj. pozy i wyrażenia) powstałe za pomocą 3DMM.
Ponieważ system 3DMM nie będzie dokładnie dopasowany do uchwyconego obiektu, ważne jest, aby to zrekompensować. RigNeRF osiąga to za pomocą pola deformacji, które jest obliczane na podstawie a Perceptron wielowarstwowy (MLP) na podstawie materiału źródłowego.

Parametry kamery niezbędne do obliczenia odkształceń uzyskuje się poprzez COLMAPA, natomiast parametry ekspresji i kształtu dla każdej ramki są uzyskiwane z DECA.
Pozycjonowanie jest dodatkowo optymalizowane poprzez przełomowe dopasowanie i parametry kamery COLMAP, a ze względu na ograniczenia zasobów obliczeniowych, wyjście wideo jest próbkowane w dół do rozdzielczości 256 × 256 na potrzeby szkolenia (proces zmniejszania ograniczony sprzętowo, który jest również plagą sceny głębokiego fałszowania autokodera).
Następnie sieć deformacji jest szkolona na czterech V100 – potężnym sprzęcie, który prawdopodobnie nie będzie w zasięgu zwykłych entuzjastów (jednak jeśli chodzi o szkolenie w zakresie uczenia maszynowego, często można zamienić wagę na czas i po prostu zaakceptować ten model szkolenie będzie kwestią dni lub nawet tygodni).
Podsumowując, badacze stwierdzają:
„W przeciwieństwie do innych metod, RigNeRF, dzięki zastosowaniu modułu deformacji sterowanego 3DMM, jest w stanie z dużą wiernością modelować pozę głowy, mimikę twarzy i pełną scenę portretową 3D, zapewniając w ten sposób lepsze rekonstrukcje z ostrymi szczegółami”.
Dalsze szczegóły i nagrania z wynikami można znaleźć w zamieszczonych poniżej filmach.


Opublikowano po raz pierwszy 15 czerwca 2022 r.















