Sztuczna inteligencja
Przebudowa twarzy w filmach wideo za pomocą uczenia maszynowego

Współpraca badawcza między Chinami a Wielką Brytanią doprowadziła do opracowania nowej metody przebudowy twarzy w filmach wideo. Technika ta pozwala na przekonywujące rozszerzanie i zwężanie struktury twarzy, z wysoką spójnością i brakiem artefaktów.
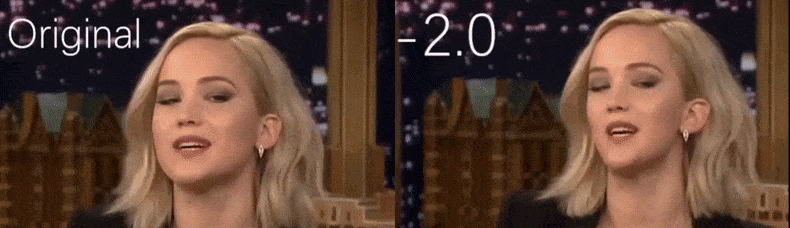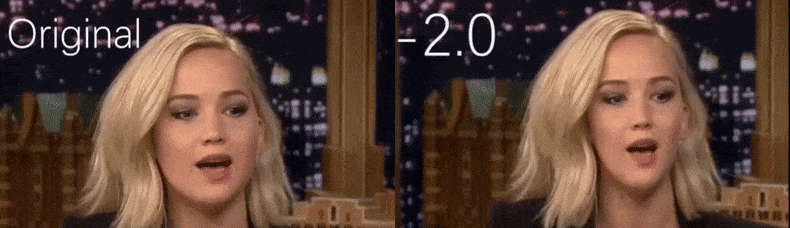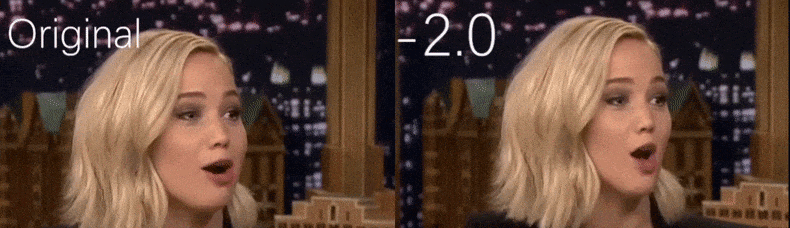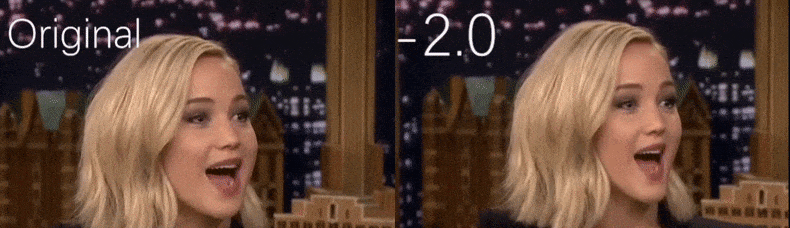
Z filmu wideo wykorzystywanego jako materiał źródłowy przez badaczy, aktorka Jennifer Lawrence pojawia się jako osoba o bardziej ascetycznej osobowości (po prawej). Zobacz załączony film wideo na dole artykułu, aby zobaczyć więcej przykładów w lepszej rozdzielczości. Źródło: https://www.youtube.com/watch?v=tA2BxvrKvjE
Ten rodzaj transformacji jest zwykle możliwy tylko za pomocą tradycyjnych metod CGI, które wymagałyby całkowitej odtworzenia twarzy za pomocą szczegółowych i kosztownych procedur motion-capping, rigging i texturing.
Zamiast tego, CGI w tej technice jest zintegrowane z neuralnym potokiem jako parametryczna informacja o twarzy 3D, która jest następnie wykorzystywana jako podstawa dla przepływu pracy z uczeniem maszynowym.

Tradycyjne parametryczne twarze są coraz częściej wykorzystywane jako wytyczne dla procesów transformacyjnych, które wykorzystują AI zamiast CGI. Źródło: https://arxiv.org/pdf/2205.02538.pdf
Autorzy stwierdzają:
‘Naszym celem jest wygenerowanie wysokiej jakości portretów wideo poprzez edycję ogólnej formy twarzy zgodnie z naturalnymi deformacjami twarzy w świecie rzeczywistym. Może to być wykorzystane w aplikacjach takich jak generowanie twarzy o określonym kształcie dla urodzenia i eksageracji twarzy dla efektów wizualnych.’
Chociaż 2D deformacja i zniekształcenie twarzy są dostępne dla konsumentów od czasu pojawienia się programu Photoshop (co doprowadziło do powstania dziwnych i często nieakceptowalnych subkultur związanych z deformacją twarzy i zaburzeniami dysmorfii ciała), jest to trudna sztuka do wykonania w filmie wideo bez użycia CGI.

Wymiary twarzy Marka Zuckerberga rozszerzone i zwężone za pomocą nowej chińsko-brytyjskiej techniki.
Przebudowa ciała jest obecnie obszarem intensywnego zainteresowania w sektorze wizji komputerowej, głównie ze względu na jej potencjał w handlu elektronicznym, chociaż sprawienie, by ktoś wyglądał na wyższego lub bardziej szkieletowego, jest obecnie znacznym wyzwaniem.
Podobnie, zmiana kształtu głowy w filmie wideo w sposób spójny i przekonywujący była przedmiotem poprzednich badań z nowego artykułu, chociaż ta implementacja cierpiała z powodu artefaktów i innych ograniczeń. Nowy system rozszerza możliwości tego poprzedniego badania z danych statycznych na dane wideo.
Nowy system został przeszkolony na komputerze stacjonarnym z procesorem AMD Ryzen 9 3950X i 32 GB pamięci, oraz wykorzystuje algorytm optycznego przepływu z OpenCV do mapowania ruchu, wygładzane przez StructureFlow framework; Sieć alignującą twarz (FAN) składnik do estymacji punktów charakterystycznych, który jest również wykorzystywany w popularnych pakietach deepfakes; oraz Ceres Solver do rozwiązywania problemów optymalizacji.

Ekstremalny przykład rozszerzania twarzy za pomocą nowego systemu.
Artykuł artykuł nosi tytuł Parametryczna przebudowa portretów w filmach wideo, i pochodzi od trzech badaczy z Zhejiang University, oraz jednego z University of Bath.
O twarzach
W nowym systemie film wideo jest wyodrębniony w sekwencję obrazów, a sztywna pozycja jest najpierw oszacowana dla każdej twarzy. Następnie reprezentatywna liczba kolejnych klatek jest wspólnie oszacowana w celu zbudowania spójnych parametrów tożsamości w całej sekwencji obrazów (tj. klatkach filmu wideo).

Architektura systemu deformacji twarzy.
Następnie wyrażenie jest oceniane, co daje parametr przebudowy, który jest wdrożony za pomocą regresji liniowej. Następnie nowy podpisany dystans funkcji (SDF) podejście konstruuje gęste mapowanie 2D cech twarzy przed i po przebudowie.
W końcu optymalizacja deformacji zawartości jest wykonywana na wyjściowym filmie wideo.
Parametryczne twarze
Proces wykorzystuje model 3D twarzy (3DMM), który jest coraz bardziej popularnym dodatkiem do systemów syntezy twarzy opartych na neuronach i GAN, a także stosowanym w systemach wykrywania deepfakes.

Nie pochodzi z nowego artykułu, ale jest to przykład modelu 3D twarzy (3DMM) – parametrycznego prototypu twarzy wykorzystywanego w nowym projekcie. Góra lewa, aplikacja punktów charakterystycznych na twarzy 3DMM. Góra prawa, wierzchołki siatki 3D izomapy. Dół lewa pokazuje dopasowanie punktów charakterystycznych; dół-środek, izomapę wyodrębnionego tekstu twarzy; i dół-prawa, wynikowe dopasowanie i kształt. Źródło: http://www.ee.surrey.ac.uk/CVSSP/Publications/papers/Huber-VISAPP-2016.pdf
Przepływ pracy nowego systemu musi uwzględniać przypadki zakrycia, takie jak sytuacja, w której osoba spogląda na bok. Jest to jeden z największych wyzwań w oprogramowaniu deepfake, ponieważ punkty charakterystyczne FAN mają niewielką pojemność do uwzględnienia tych przypadków i tendencję do pogorszenia jakości, gdy twarz odwraca się lub jest zakryta.
Nowy system jest w stanie uniknąć tej pułapki, definiując energię konturu, która jest w stanie dopasować granicę między twarzą 3D (3DMM) a twarzą 2D (zdefiniowaną przez punkty charakterystyczne FAN).
Optymalizacja
Przydatne wdrożenie takiego systemu byłoby wdrożenie deformacji w czasie rzeczywistym, na przykład w filtrach wideokonferencyjnych. Bieżąca ramka nie umożliwia tego, a niezbędne zasoby obliczeniowe uczyniłyby “na żywo” deformację znacznym wyzwaniem.
Zgodnie z artykułem, przy założeniu celu filmu wideo 24 klatek na sekundę, operacje na klatce w potoku reprezentują opóźnienie 16,344 sekund na sekundę filmu, z dodatkowymi jednorazowymi uderzeniami dla estymacji tożsamości i deformacji twarzy 3D (321 ms i 160 ms, odpowiednio).
Dlatego optymalizacja jest kluczem do postępu w kierunku obniżania opóźnienia. Ponieważ wspólna optymalizacja we wszystkich klatkach dodałaby znaczne obciążenie procesowi, a optymalizacja init-style (przyjmując spójną tożsamość mówcy od pierwszej klatki) mogłaby prowadzić do anomalii, autorzy przyjęli schemat rzadki do obliczania współczynników klatek próbkowanych w praktycznych odstępach.
Następnie optymalizacja wspólna jest wykonywana na tym podzbiorze klatek, prowadząc do lżejszego procesu rekonstrukcji.
Deformacja twarzy
Technika deformacji wykorzystywana w projekcie jest adaptacją pracy autorów z 2020 roku Deep Shapely Portraits (DSP).

Deep Shapely Portraits, przesłanie z 2020 roku do ACM Multimedia. Artykuł jest prowadzony przez badaczy z ZJU-Tencent Game i Intelligent Graphics Innovation Technology Joint Lab. Źródło: http://www.cad.zju.edu.cn/home/jin/mm2020/demo.mp4
Autorzy zauważają ‘Rozszerzamy tę metodę z przebudowy jednego obrazu monocularnego do przebudowy całej sekwencji obrazów.’
Testy
Artykuł stwierdza, że nie było porównywalnego materiału, przeciwko któremu można by ocenić nową metodę. Dlatego autorzy porównali klatki wyjściowego filmu wideo z statycznym wyjściem DSP.

Testowanie nowego systemu w porównaniu z obrazami statycznymi z Deep Shapely Portraits.
Autorzy stwierdzają:
‘Wyniki pokazują, że nasze podejście może niezawodnie generować spójne przebudowane portrety wideo, podczas gdy metoda oparta na obrazach może łatwo prowadzić do zauważalnych artefaktów migotania.’
Zobacz załączony film wideo poniżej, aby zobaczyć więcej przykładów:
Pierwotnie opublikowane 9 maja 2022. Zmienione o 18:00 EET, zastąpione ‘field’ z ‘function’ dla SDF.












