Sztuczna inteligencja
‘Kreatywna’ Weryfikacja Twarzy z Sieciami Adversarialnymi Generatywnymi

Nowy artykuł z Uniwersytetu Stanforda zaproponował powstająca metodę oszukiwania systemów uwierzytelniania twarzy na platformach takich jak aplikacje randkowe, wykorzystując Sieć Adversarialną Generatywną (GAN), aby utworzyć alternatywne obrazy twarzy, które zawierają te same istotne informacje identyfikacyjne, co prawdziwa twarz.
Metoda ta pomyślnie ominęła procesy weryfikacji twarzy w aplikacjach randkowych Tinder i Bumble, w jednym przypadku nawet podając twarz zmienioną pod względem płci (męską) jako autentyczną w stosunku do źródłowej tożsamości (żeńskiej).

Różne wygenerowane tożsamości, które zawierają specyficzną kodowanie autora artykułu (wyświetlone w pierwszym obrazie powyżej). Źródło: https://arxiv.org/pdf/2203.15068.pdf
Według autora, praca ta reprezentuje pierwszą próbę ominącia weryfikacji twarzy przy użyciu wygenerowanych obrazów, które zostały wzbogacone o określone cechy identyfikacyjne, ale które próbują reprezentować alternatywną lub znacznie zmienioną tożsamość.
Technika ta została przetestowana na niestandardowym lokalnym systemie weryfikacji twarzy, a następnie sprawdziła się w testach black box przeciwko dwóm aplikacjom randkowym, które wykonują weryfikację twarzy na obrazach przesłanych przez użytkowników.
Nowy artykuł nosi tytuł Ominięcie Weryfikacji Twarzy i pochodzi od Sanjany Sardy, badacza w Departamencie Inżynierii Elektrycznej na Uniwersytecie Stanforda.
Kontrola Przestrzeni Twarzy
Chociaż “wstrzykiwanie” cech specyficznych dla identyfikacji (tj. z twarzy, znaków drogowych itp.) do spreparowanych obrazów jest podstawą ataków adversarialnych, nowe badanie sugeruje coś innego: że rosnąca zdolność sektora badawczego do kontrolowania przestrzeni latentnej GAN w końcu umożliwi opracowanie architektur, które mogą tworzyć spójne alternatywne tożsamości użytkownika – i efektywnie umożliwić wydobycie cech identyfikacyjnych z dostępnych w sieci obrazów nieświadomego użytkownika, aby je zaadaptować do “cieniowej” spreparowanej tożsamości.
Spójność i nawigowalność były głównymi wyzwaniami dotyczącymi przestrzeni latentnej GAN od momentu powstania Sieci Adversarialnych Generatywnych. GAN, który pomyślnie zaadaptował kolekcję obrazów szkoleniowych do swojej przestrzeni latentnej, nie zapewnia łatwej mapy do “przesunięcia” cech z jednej klasy do innej.
Chociaż techniki i narzędzia takie jak Gradient-weighted Class Activation Mapping (Grad-CAM) mogą pomóc w ustaleniu kierunków latentnych między ustalonymi klasami i umożliwić transformacje (patrz poniższy obraz), dalszym wyzwaniem jest splątanie, co zwykle sprawia, że jest to “przybliżona” podróż, z ograniczoną kontrolą przejścia.
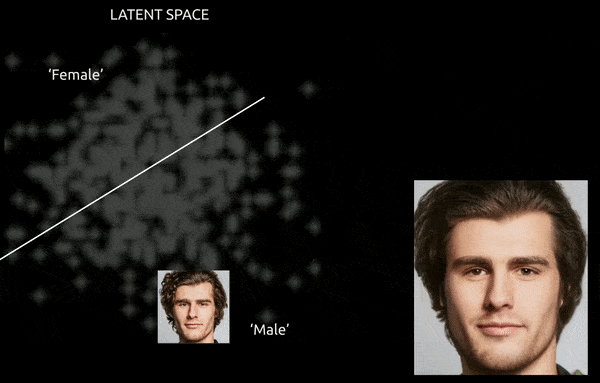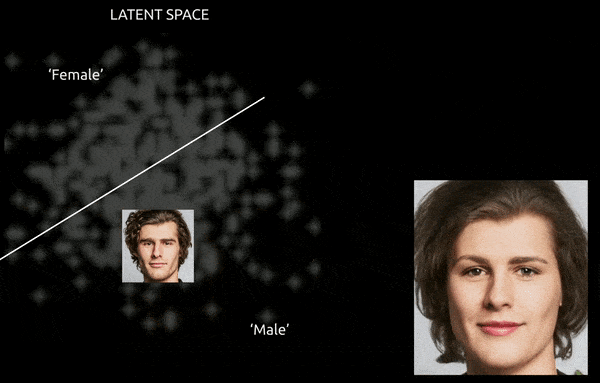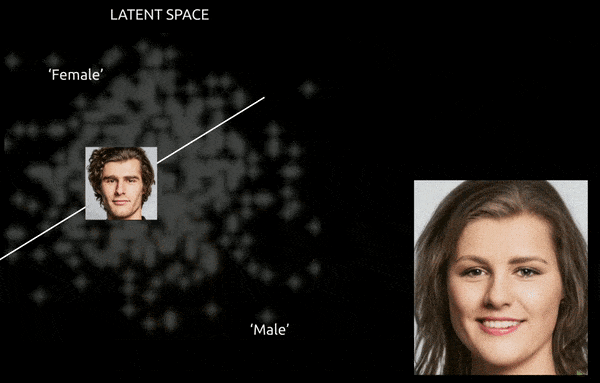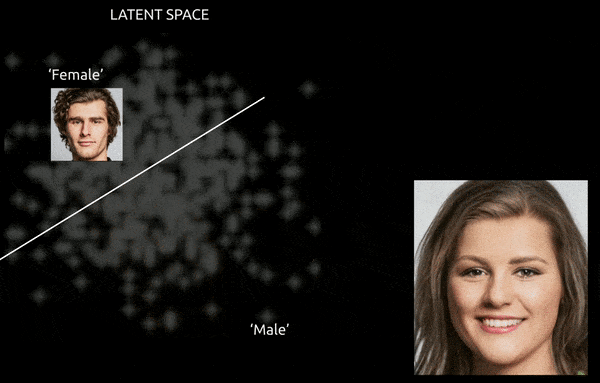
Pogrubiona podróż między zakodowanymi wektorami w przestrzeni latentnej GAN, przesuwając pochodzącą z danych tożsamość męską do kodowań ‘żeńskich’ po drugiej stronie jednej z wielu liniowych hiperpłaszczyzn w złożonej i tajemniczej przestrzeni latentnej. Obraz pochodzi z materiału na https://www.youtube.com/watch?v=dCKbRCUyop8
Możliwość “zamrożenia” i ochrony cech specyficznych dla identyfikacji podczas ich przenoszenia do transformatywnych kodowań w innej części przestrzeni latentnej potencjalnie umożliwia stworzenie spójnej (i nawet animowalnej) jednostki, której tożsamość jest odczytywana przez systemy maszynowe jako ktoś inny.
Metoda
Autor wykorzystał dwa zestawy danych jako podstawę do eksperymentów: Zestaw Danych Użytkowników Ludzkich, składający się z 310 obrazów jego twarzy, obejmujących okres czterech lat, z różnym oświetleniem, wiekiem i kątami widzenia), z wyciętymi twarzami za pomocą Caffe; oraz rasowo zrównoważone 108 501 obrazów w zestawie FairFace, podobnie wycięte i przycięte.
Lokalny model weryfikacji twarzy został pochodny z podstawowej implementacji FaceNet i DeepFace, wstępnie trenowany na ConvNet Inception, z każdym obrazem reprezentowanym przez 128-wymiarowy wektor.
Podejście wykorzystuje obrazy twarzy z wytrenowanego podzestawu z FairFace. Aby ominąć weryfikację twarzy, obliczona odległość spowodowana przez normę Frobeniusa obrazu jest przesunięta w stosunku do użytkownika docelowego w bazie danych. Każdy obraz poniżej progu 0,7 jest równoważny z tą samą tożsamością, w przeciwnym razie weryfikacja jest uważana za nieudaną.
Model StyleGAN został dostosowany do zestawu danych osobistych autora, wytwarzając model, który generował rozpoznawalne wariacje jego tożsamości, chociaż żaden z tych wygenerowanych obrazów nie był identyczny z danymi szkoleniowymi. To zostało osiągnięte przez zamrożenie pierwszych czterech warstw w dyskryminatorze, aby uniknąć przeuczenia danych i wytworzyć zróżnicowany wynik.
Chociaż różnorodne obrazy zostały uzyskane z podstawowego modelu StyleGAN, niska rozdzielczość i wierność skłoniły do drugiej próby z StarGAN V2, który pozwala na trenowanie obrazów źródłowych w kierunku docelowego obrazu twarzy.
Model StarGAN V2 został wstępnie trenowany przez około 10 godzin przy użyciu zestawu walidacyjnego FairFace, na rozmiarze partii 4 i rozmiarze walidacji 8. W najbardziej udanym podejściu, zestaw danych osobistych autora został użyty jako źródło z danymi szkoleniowymi jako odniesienie.
Eksperymenty Weryfikacyjne
Model weryfikacji twarzy został zbudowany na podstawie podzestawu 1000 obrazów, z zamiarem zweryfikowania dowolnego obrazu z zestawu. Obrazy, które pomyślnie przeszły weryfikację, zostały następnie przetestowane przeciwko własnej tożsamości autora.

Po lewej, autor artykułu, prawdziwa fotografia; środek, dowolny obraz, który nie przeszedł weryfikacji; po prawej, niezwiązany obraz z zestawu, który przeszedł weryfikację jako autor.
Celem eksperymentów było stworzenie jak największej luki między postrzeganą tożsamością wizualną, a jednocześnie zachowaniem definiujących cech tożsamości docelowej. To zostało ocenione za pomocą odległości Mahalanobisa, miary używanej w przetwarzaniu obrazu do wyszukiwania wzorców i szablonów.
Dla modelu generatywnego bazowego, niska rozdzielczość wyników wyświetla ograniczoną różnorodność, pomimo pomyślnego przejścia lokalnej weryfikacji twarzy. StarGAN V2 okazał się bardziej zdolny do tworzenia zróżnicowanych obrazów, które mogły uwierzytelnić.

Wszystkie obrazy przedstawione przeszły lokalną weryfikację twarzy. Powyżej są niska rozdzielczość generacji bazowego StyleGAN, poniżej, wyższa rozdzielczość i lepsza jakość generacji StarGAN V2.
Ostateczne trzy obrazy przedstawione powyżej wykorzystały zestaw danych twarzy autora jako źródło i odniesienie, podczas gdy poprzednie obrazy wykorzystały dane szkoleniowe jako odniesienie i zestaw danych autora jako źródło.
Wynikowe obrazy wygenerowane zostały przetestowane przeciwko systemom weryfikacji twarzy aplikacji randkowych Bumble i Tinder, z tożsamością autora jako podstawą, i przeszły weryfikację. “Męska” generacja twarzy autora również przeszła weryfikację Bumble, chociaż oświetlenie musiało być dostosowane w wygenerowanym obrazie, zanim zostało zaakceptowane. Tinder nie zaakceptował wersji męskiej.

‘Męskie’ wersje tożsamości autora (żeńskiej).
Wnioski
To są przełomowe eksperymenty w projekcji tożsamości, w kontekście manipulacji przestrzenią latentną GAN, która pozostaje nadzwyczajnym wyzwaniem w syntezie obrazu i badaniach deepfake. Niemniej, praca ta otwiera koncepcję osadzania wysoko specyficznych cech w sposób spójny w różnych tożsamościach i tworzenia “alternatywnych” tożsamości, które “czytają” jako ktoś inny.
Pierwotnie opublikowane 30 marca 2022.












