
Best Of
10 labākie mašīnmācīšanās algoritmi
Lai gan mēs dzīvojam ārkārtēju inovāciju laikā GPU paātrinātā mašīnmācībā, jaunākajos pētījumos bieži (un pamanāmi) ir ietverti algoritmi, kas ir gadu desmitiem, dažos gadījumos 70 gadus veci.
Daži varētu apgalvot, ka daudzas no šīm vecākajām metodēm ietilpst “statistiskās analīzes”, nevis mašīnmācīšanās nometnē, un dod priekšroku nozares rašanos datēt tikai līdz 1957. gadam, kad Perceptrona izgudrojums.
Ņemot vērā to, cik lielā mērā šie vecāki algoritmi atbalsta jaunākās tendences un virsrakstus piesaistošos mašīnmācības sasniegumus, tā ir apstrīdama nostāja. Tāpēc apskatīsim dažus “klasiskos” blokus, kas ir pamatā jaunākajiem jauninājumiem, kā arī dažus jaunākus ierakstus, kas jau agrāk piedāvā AI slavas zāli.
1: Transformeri
2017. gadā Google pētniecība vadīja sadarbību pētniecības jomā, kuras kulminācija bija papīrs Uzmanība ir viss, kas jums nepieciešams. Darbā tika izklāstīta jauna arhitektūra, kas veicināja uzmanības mehānismi no kodētāja/dekodētāja un atkārtoto tīkla modeļu “cauruļvada” līdz pat pašai centrālajai transformācijas tehnoloģijai.
Pieeja tika dublēta Transformators, un kopš tā laika tā ir kļuvusi par revolucionāru dabiskās valodas apstrādes (NLP) metodoloģiju, kas, starp daudziem citiem piemēriem, nodrošina autoregresīvo valodas modeli un AI plakātu-bērnu GPT-3.
![]()
Transformatori eleganti atrisināja problēmu secības transdukcija, ko sauc arī par "transformāciju", kas ir aizņemta ar ievades secību apstrādi izvades sekvencēs. Transformators arī saņem un pārvalda datus nepārtrauktā veidā, nevis secīgās paketēs, nodrošinot “atmiņas noturību”, kuras iegūšanai RNN arhitektūras nav paredzētas. Lai iegūtu detalizētāku pārskatu par transformatoriem, skatiet mūsu atsauces raksts.
Atšķirībā no atkārtotajiem neironu tīkliem (RNN), kas CUDA laikmetā bija sākuši dominēt ML pētījumos, arī transformatoru arhitektūru varēja viegli izmantot. paralēli, paverot iespēju produktīvi risināt daudz lielāku datu korpusu nekā RNN.
Populārs lietojums
Transformatori aizrāva sabiedrības iztēli 2020. gadā, izlaižot OpenAI GPT-3, kas lepojās ar toreizējo rekordu. 175 miljardi parametru. Šo acīmredzami satriecošo sasniegumu galu galā aizēnoja vēlāki projekti, piemēram, 2021. atlaidiet Microsoft Megatron-Turing NLG 530B, kurā (kā norāda nosaukums) ir vairāk nekā 530 miljardi parametru.

Hipermēroga transformatora NLP projektu laika skala. Avots: microsoft
Transformatoru arhitektūra ir arī pārgājusi no NLP uz datorredzi, nodrošinot a jauna paaudze attēlu sintēzes ietvariem, piemēram, OpenAI CLIP un DALL-E, kas izmanto teksta >attēla domēna kartēšanu, lai pabeigtu nepilnīgus attēlus un sintezētu jaunus attēlus no apmācītiem domēniem, kā arī arvien vairāk saistīto lietojumprogrammu.

DALL-E mēģina pabeigt daļēju Platona krūšutēlu. Avots: https://openai.com/blog/dall-e/
2: ģeneratīvie pretrunīgie tīkli (GAN)
Lai gan transformatori ir guvuši īpašu plašsaziņas līdzekļu atspoguļojumu, izlaižot un pieņemot GPT-3, Ģeneratīvs pretrunīgs tīkls (GAN) ir kļuvis par atpazīstamu zīmolu pats par sevi, un ar laiku tam var pievienoties deepfake kā darbības vārds.
Pirmais ierosināts jo 2014 un galvenokārt izmanto attēlu sintēzei, ģeneratīvajam pretrunīgajam tīklam arhitektūra sastāv no a Ģenerators un Diskriminētājs. Ģenerators cikliski pārlasa tūkstošiem attēlu datu kopā, iteratīvi cenšoties tos rekonstruēt. Katram mēģinājumam Diskriminators novērtē ģeneratora darbu un nosūta ģeneratoru atpakaļ, lai tas būtu labāks, taču bez jebkāda ieskata iepriekšējās rekonstrukcijas kļūdas veidā.

Avots: https://developers.google.com/machine-learning/gan/gan_structure
Tas liek ģeneratoram izpētīt daudzus ceļus, tā vietā, lai sekotu potenciālajām aklajām ejām, kas būtu radušās, ja diskriminētājs būtu pavēstījis, kur tas notiek nepareizi (skat. #8 zemāk). Apmācībai beidzoties, ģeneratoram ir detalizēta un visaptveroša datu kopas punktu attiecību karte.

No papīra GAN līdzsvara uzlabošana, paaugstinot telpisko izpratni: jauns ietvars cirkulē cauri dažkārt noslēpumainajai GAN latentajai telpai, nodrošinot reaģējošu instrumentu attēlu sintēzes arhitektūrai. Avots: https://genforce.github.io/eqgan/
Pēc analoģijas šī ir atšķirība starp vienreizēju braukšanu uz Londonas centru vai rūpīgu apgūšanu Zināšanas.
Rezultāts ir augsta līmeņa funkciju kolekcija apmācītā modeļa latentā telpā. Augsta līmeņa iezīmes semantiskais rādītājs varētu būt “persona”, savukārt nolaišanās, kas saistīta ar specifiku, kas saistīta ar pazīmi, var atklāt citas apgūtas īpašības, piemēram, “vīrietis” un “sieviete”. Zemākos līmeņos apakšiezīmes var sadalīties līdz “blondiņam”, “kaukāzietim” u.c.
Sapīšanās ir ievērojams jautājums GAN un kodētāja/dekodētāja ietvaru latentā telpā: vai smaids uz GAN ģenerētas sievietes sejas ir viņas 'identitātes' sapinusies iezīme latentā telpā, vai arī tā ir paralēla atzara?

Šīs personas GAN ģenerētas sejas neeksistē. Avots: https://this-person-does-not-exist.com/en
Pēdējo pāris gadu laikā ir radušies arvien vairāk jaunu pētniecības iniciatīvu šajā jomā, iespējams, paverot ceļu funkciju līmeņa, Photoshop stila rediģēšanai GAN latentā telpā, taču šobrīd daudzas transformācijas ir efektīvas. visu vai neko” paketes. Proti, NVIDIA 2021. gada beigās izdotais EditGAN laidiens sasniedz a augsts interpretējamības līmenis latentā telpā, izmantojot semantiskās segmentācijas maskas.
Populārs lietojums
Papildus (faktiski diezgan ierobežotajai) iesaistei populāros dziļi viltotos videoklipos, uz attēliem/video orientēti GAN pēdējo četru gadu laikā ir izplatījušies, sajūsminot gan pētniekus, gan sabiedrību. Lai gan GitHub repozitorijs, sekot līdzi reibinošajam jauno izlaidumu ātrumam un biežumam ir izaicinājums Lieliskas GAN lietojumprogrammas mērķis ir nodrošināt visaptverošu sarakstu.
Ģeneratīvie pretrunīgie tīkli teorētiski var iegūt funkcijas no jebkura labi ierāmēta domēna, ieskaitot tekstu.
3: SVM
Radies jo 1963, Atbalstiet vektoru mašīnu (SVM) ir galvenais algoritms, kas bieži tiek izmantots jaunos pētījumos. Zem SVM vektori kartē datu punktu relatīvo izvietojumu datu kopā, kamēr atbalstīt vektori iezīmē robežas starp dažādām grupām, pazīmēm vai pazīmēm.
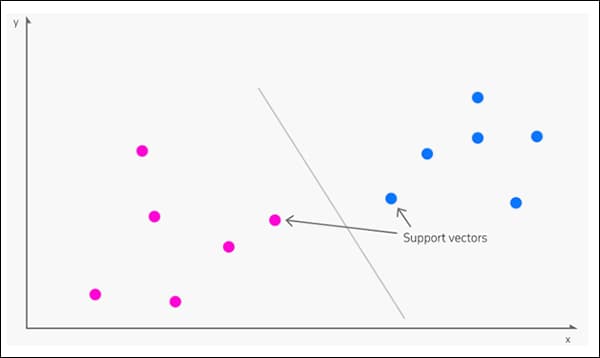
Atbalsta vektori nosaka robežas starp grupām. Avots: https://www.kdnuggets.com/2016/07/support-vector-machines-simple-explanation.html
Atvasināto robežu sauc par a hiperplāns.
Zemā funkciju līmenī SVM ir divdimensiju (attēls augšā), bet, ja ir lielāks atpazīto grupu vai veidu skaits, tas kļūst trīsdimensiju.

Lai iegūtu dziļāku punktu un grupu masīvu, ir nepieciešams trīsdimensiju SVM. Avots: https://cml.rhul.ac.uk/svm.html
Populārs lietojums
Tā kā atbalsta vektora mašīnas var efektīvi un agnostiski risināt dažāda veida augstas dimensijas datus, tie ir plaši izplatīti dažādās mašīnmācīšanās nozarēs, tostarp dziļa viltojumu noteikšana, attēlu klasifikācija, naida runas klasifikācija, DNS analīze un iedzīvotāju struktūras prognozēšana, Starp daudziem citiem.
4: K-Means klasterizācija
Klasterizācija kopumā ir mācīšanās bez uzraudzības pieeja, kas mēģina klasificēt datu punktus blīvuma novērtējums, izveidojot pētāmo datu sadalījuma karti.

K-Means grupē dievišķos segmentus, grupas un kopienas datos. Avots: https://aws.amazon.com/blogs/machine-learning/k-means-clustering-with-amazon-sagemaker/
K-Means klasterizācija ir kļuvusi par populārāko šīs pieejas ieviešanu, apkopojot datu punktus atšķirīgās "K grupās", kas var norādīt uz demogrāfiskajiem sektoriem, tiešsaistes kopienām vai jebkuru citu iespējamu slepenu apkopojumu, kas gaida, lai tos atklātu neapstrādātos statistikas datos.

K-Means analīzē veidojas klasteri. Avots: https://www.geeksforgeeks.org/ml-determine-the-optimal-value-of-k-in-k-means-clustering/
Pati K vērtība ir noteicošais faktors procesa lietderībā un klastera optimālās vērtības noteikšanā. Sākotnēji K vērtība tiek piešķirta nejauši, un tās pazīmes un vektora raksturlielumi tiek salīdzināti ar kaimiņiem. Tie kaimiņi, kas visvairāk līdzinās datu punktam ar nejauši piešķirto vērtību, tiek piešķirti tā klasterim iteratīvi, līdz dati ir radījuši visas procesa atļautās grupas.
Kvadrātveida kļūdas vai dažādu klasteru vērtību “izmaksu” diagramma atklās elkoņa punkts par datiem:

"Elkoņa punkts" klastera diagrammā. Avots: https://www.scikit-yb.org/en/latest/api/cluster/elbow.html
Elkoņa punkts pēc koncepcijas ir līdzīgs tam, kā datu kopas apmācības sesijas beigās zaudējumi tiek izlīdzināti, samazinot atdevi. Tas atspoguļo punktu, kurā vairs neparādīsies atšķirības starp grupām, norādot brīdi, kad jāpāriet uz nākamajām datu plūsmas fāzēm vai jāziņo par konstatējumiem.
Populārs lietojums
Acīmredzamu iemeslu dēļ K-Means klasterizācija ir primārā tehnoloģija klientu analīzē, jo tā piedāvā skaidru un izskaidrojamu metodiku, lai lielu daudzumu komerciālo ierakstu pārvērstu demogrāfiskos ieskatos un “potenciālajos pirkumos”.
Ārpus šīs lietojumprogrammas tiek izmantota arī K-Means klasterēšana zemes nogruvumu prognoze, medicīniskā attēla segmentācija, attēlu sintēze ar GAN, dokumentu klasifikācija, un pilsētas plānošana, starp daudziem citiem potenciālajiem un faktiskajiem lietojumiem.
5: Random Forest
Random Forest ir an ansambļa mācības metode, kas nosaka vidējo rezultātu no masīva lēmumu koki lai izveidotu vispārēju iznākuma prognozi.

Avots: https://www.tutorialandexample.com/wp-content/uploads/2019/10/Decision-Trees-Root-Node.png
Ja esat to pētījis pat tik maz, cik skatījies Atpakaļ uz nākotni triloģijā, lēmumu koku pats par sevi ir diezgan viegli konceptualizēt: jūsu priekšā ir vairāki ceļi, un katrs ceļš atzarojas līdz jaunam iznākumam, kas savukārt satur tālākus iespējamos ceļus.
In pastiprināt mācīšanās, jūs varētu atkāpties no ceļa un sākt no jauna no agrākas nostājas, savukārt lēmumu koki apņemas savus ceļojumus.
Tādējādi Random Forest algoritms būtībā ir lēmumu pieņemšanas likmes. Algoritms tiek saukts par “nejaušot”, jo tas veido ad hoc atlases un novērojumus, lai saprastu mediāna lēmumu koku masīva rezultātu summa.
Tā kā tajā tiek ņemti vērā daudzi faktori, izlases veida meža pieeju var būt grūtāk pārvērst jēgpilnos grafikos nekā lēmumu koku, taču tā, visticamāk, ir ievērojami produktīvāka.
Lēmumu koki ir pakļauti pārmērīgai pielāgošanai, ja iegūtie rezultāti ir specifiski datiem un, visticamāk, netiks vispārināti. Random Forest patvaļīgā datu punktu atlase cīnās pret šo tendenci, izpētot jēgpilnas un noderīgas datu reprezentatīvās tendences.

Lēmumu koka regresija. Avots: https://scikit-learn.org/stable/auto_examples/tree/plot_tree_regression.html
Populārs lietojums
Tāpat kā daudzi šajā sarakstā iekļautie algoritmi, Random Forest parasti darbojas kā datu “agrīnais” šķirotājs un filtrs, un tādējādi tas pastāvīgi tiek parādīts jaunos pētnieciskajos rakstos. Daži Random Forest izmantošanas piemēri ietver Magnētiskās rezonanses attēlu sintēze, Bitcoin cenu prognoze, skaitīšanas segmentācija, teksta klasifikācija un kredītkaršu krāpšanas atklāšana.
Tā kā Random Forest ir zema līmeņa algoritms mašīnmācīšanās arhitektūrās, tas var veicināt arī citu zema līmeņa metožu veiktspēju, kā arī vizualizācijas algoritmus, t.sk. Induktīvā klasterizācija, Iezīmju pārvērtības, teksta dokumentu klasifikācija izmantojot retas funkcijas, un Cauruļvadu attēlošana.
6: naivais Bejs
Kopā ar blīvuma novērtējumu (sk 4, augstāk), a naivais Bejs Klasifikators ir spēcīgs, bet salīdzinoši viegls algoritms, kas spēj novērtēt varbūtības, pamatojoties uz aprēķinātajām datu iezīmēm.

Iezīmju attiecības naivajā Bayes klasifikatorā. Avots: https://www.sciencedirect.com/topics/computer-science/naive-bayes-model
Termins “naivs” attiecas uz pieņēmumu Bayes teorēma ka funkcijas ir nesaistītas, zināmas kā nosacīta neatkarība. Ja pieņemat šo nostāju, ar staigāšanu un runāšanu kā pīlei nepietiek, lai noteiktu, ka mums ir darīšana ar pīli, un nekādi "acīmredzami" pieņēmumi netiek pieņemti priekšlaicīgi.
Šāds akadēmiskās un izmeklēšanas stingrības līmenis būtu pārmērīgs, ja ir pieejams “veselais saprāts”, taču tas ir vērtīgs standarts, pārvarot daudzās neskaidrības un potenciāli nesaistītas korelācijas, kas var pastāvēt mašīnmācīšanās datu kopā.
Sākotnējā Beijesa tīklā funkcijas ir pakļautas punktu skaitīšanas funkcijas, ieskaitot minimālo apraksta garumu un Beijesa vārti, kas var noteikt ierobežojumus datiem attiecībā uz aprēķinātajiem savienojumiem, kas atrasti starp datu punktiem, un virzienu, kurā šie savienojumi plūst.
Savukārt naivais Beijesa klasifikators darbojas, pieņemot, ka konkrētā objekta pazīmes ir neatkarīgas, pēc tam izmantojot Bayes teorēmu, lai aprēķinātu dotā objekta varbūtību, pamatojoties uz tā pazīmēm.
Populārs lietojums
Naivi Bayes filtri ir labi pārstāvēti slimības prognozēšana un dokumentu klasifikācija, surogātpasta filtrēšana, sentimenta klasifikācija, ieteikuma sistēmas, un krāpšanas atklāšana, starp citiem lietojumiem.
7: K — tuvākie kaimiņi (KNN)
Pirmo reizi ierosināja ASV Gaisa spēku Aviācijas medicīnas skola jo 1951un jāpielāgojas 20. gadsimta vidus jaunākajai skaitļošanas tehnikai, K-Tuvākie kaimiņi (KNN) ir vienkāršs algoritms, kas joprojām ir pamanāms akadēmiskajos rakstos un privātā sektora mašīnmācīšanās pētniecības iniciatīvās.
KNN ir saukts par "slinko apmācāmo", jo tas pilnībā skenē datu kopu, lai novērtētu attiecības starp datu punktiem, nevis pieprasa pilnvērtīga mašīnmācīšanās modeļa apmācību.

KNN grupējums. Avots: https://scikit-learn.org/stable/modules/neighbors.html
Lai gan KNN ir arhitektoniski slaids, tā sistemātiskā pieeja rada ievērojamu pieprasījumu pēc lasīšanas/rakstīšanas darbībām, un tā izmantošana ļoti lielās datu kopās var būt problemātiska bez papildu tehnoloģijām, piemēram, galveno komponentu analīzes (PCA), kas var pārveidot sarežģītas un liela apjoma datu kopas. iekšā reprezentatīvas grupas ka KNN var izbraukt ar mazāku piepūli.
A Nesenais pētījums novērtēja vairāku algoritmu efektivitāti un ekonomiju, kuru uzdevums bija paredzēt, vai darbinieks pametīs uzņēmumu, atklājot, ka septiņgadnieks KNN joprojām ir pārāks par modernākiem pretendentiem precizitātes un prognozēšanas efektivitātes ziņā.
Populārs lietojums
Neskatoties uz populāro koncepcijas un izpildes vienkāršību, KNN nav iestrēdzis 1950. gados — tas ir pielāgots vairāk uz DNN vērsta pieeja 2018. gada Pensilvānijas štata universitātes priekšlikumā, un tas joprojām ir centrālais agrīnās stadijas process (vai pēcapstrādes analītiskais rīks) daudzās daudz sarežģītākās mašīnmācīšanās sistēmās.
Dažādās konfigurācijās KNN ir izmantots vai priekš tiešsaistes paraksta pārbaude, attēlu klasifikācija, teksta ieguve, ražas prognozēšana, un sejas atpazīšana, papildus citiem lietojumiem un inkorporācijām.

Uz KNN balstīta sejas atpazīšanas sistēma apmācībā. Source: https://pdfs.semanticscholar.org/6f3d/d4c5ffeb3ce74bf57342861686944490f513.pdf
8: Markova lēmumu process (MDP)
Matemātiskā sistēma, ko ieviesa amerikāņu matemātiķis Ričards Belmans jo 1957, Markova lēmumu process (MDP) ir viens no visvienkāršākajiem blokiem pastiprināt mācīšanās arhitektūrām. Konceptuāls algoritms pats par sevi, tas ir pielāgots daudziem citiem algoritmiem un bieži atkārtojas pašreizējā AI/ML pētniecībā.
MDP pēta datu vidi, izmantojot tās pašreizējā stāvokļa novērtējumu (ti, “kur tas atrodas datos”), lai izlemtu, kuru datu mezglu izpētīt nākamo.

Avots: https://www.sciencedirect.com/science/article/abs/pii/S0888613X18304420
Pamata Markova lēmumu pieņemšanas procesā prioritāte būs tuvākā termiņa priekšrocībām salīdzinājumā ar vēlamākiem ilgtermiņa mērķiem. Šī iemesla dēļ tas parasti tiek iestrādāts visaptverošākas politikas arhitektūras kontekstā pastiprināšanas mācībās un bieži vien ir pakļauts ierobežojošiem faktoriem, piemēram, diskontēta atlīdzība, un citi modificējoši vides mainīgie, kas neļaus tai steigties uz tūlītēju mērķi, neņemot vērā plašāku vēlamo rezultātu.
Populārs lietojums
MDP zemā līmeņa koncepcija ir plaši izplatīta gan pētniecībā, gan aktīvā mašīnmācības ieviešanā. Tas ir ierosināts IoT drošības aizsardzības sistēmas, zivju ieguve, un tirgus prognozēšana.
Papildus tam acīmredzama pielietojamība uz šahu un citām stingri secīgām spēlēm, MDP ir arī dabisks sāncensis robotikas sistēmu procesuālā apmācība, kā mēs redzam tālāk esošajā videoklipā.

9: terminu biežums-apgrieztā dokumenta biežums
Termiņu biežums (TF) dala vārda reižu skaitu dokumentā ar kopējo vārdu skaitu šajā dokumentā. Tādējādi vārds aizzīmogot vienu reizi parādās tūkstoš vārdu rakstā, un terminu biežums ir 0.001. Pats par sevi TF lielākoties ir bezjēdzīgs kā termina nozīmīguma rādītājs, jo bezjēdzīgi raksti (piemēram, a, un, o, un it) dominē.
Lai terminam iegūtu jēgpilnu vērtību, Inverse Document Frequency (IDF) aprēķina vārda TF vairākos dokumentos datu kopā, piešķirot zemu vērtējumu ļoti augstai frekvencei. stopvārdi, piemēram, raksti. Iegūtie pazīmju vektori tiek normalizēti līdz veselām vērtībām, katram vārdam piešķirot atbilstošu svaru.

TF-IDF izsver terminu atbilstību, pamatojoties uz to biežumu vairākos dokumentos, un retāk sastopamie gadījumi liecina par nozīmīgumu. Avots: https://moz.com/blog/inverse-document-frequency-and-the-importance-of-uniqueness
Lai gan šī pieeja novērš semantiski svarīgu vārdu pazaudēšanu kā novirzes, frekvences svara invertēšana automātiski nenozīmē, ka zemas frekvences termins ir nav izņēmums, jo dažas lietas ir reti sastopamas un nevērtīgs. Tāpēc zemas frekvences terminam būs jāpierāda tā vērtība plašākā arhitektūras kontekstā, iekļaujot to (pat ar zemu biežumu vienā dokumentā) vairākos datu kopas dokumentos.
Neskatoties uz to vecumsTF-IDF ir jaudīga un populāra metode sākotnējās filtrēšanas caurlaidēm dabiskās valodas apstrādes sistēmās.
Populārs lietojums
Tā kā TF-IDF pēdējo divdesmit gadu laikā ir spēlējis vismaz zināmu lomu Google lielākoties okultā PageRank algoritma izstrādē, tas ir kļuvis ļoti plaši pieņemts kā manipulatīva SEO taktika, neskatoties uz Džona Millera 2019 atteikšanās par tā nozīmi meklēšanas rezultātos.
PageRank slepenības dēļ nav skaidru pierādījumu, ka TF-IDF tāds ir nav pašlaik ir efektīva taktika, lai paceltos Google reitingos. Aizdedzinošs diskusija IT profesionāļu vidū pēdējā laikā norāda uz populāru izpratni (pareizu vai nē), ka termina ļaunprātīga izmantošana joprojām var uzlabot SEO izvietojumu (lai gan apsūdzības monopola ļaunprātīgā izmantošanā un pārmērīga reklāma izpludināt šīs teorijas robežas).
10: Stohastiskā gradienta nolaišanās
Stohastiskā gradienta nolaišanās (SGD) ir arvien populārāka metode mašīnmācīšanās modeļu apmācības optimizēšanai.
Gradient Descent pati par sevi ir metode, kā optimizēt un pēc tam kvantitatīvi noteikt uzlabojumus, ko modelis veic apmācības laikā.
Šajā ziņā "gradients" norāda slīpumu uz leju (nevis uz krāsu balstītu gradāciju, skatiet attēlu zemāk), kur "kalna" augstākais punkts kreisajā pusē apzīmē apmācības procesa sākumu. Šajā posmā modelis vēl nav redzējis visu datu kopumu pat vienu reizi un nav pietiekami iemācījies par attiecībām starp datiem, lai radītu efektīvas transformācijas.

Gradienta nolaišanās FaceSwap apmācības sesijā. Mēs redzam, ka treniņš kādu laiku ir nokritis otrajā pusē, bet galu galā ir atguvis ceļu lejup pa gradientu uz pieņemamu konverģenci.
Zemākais punkts labajā pusē apzīmē konverģenci (punktu, kurā modelis ir tikpat efektīvs, cik tas jebkad būs pakļauts noteiktajiem ierobežojumiem un iestatījumiem).
Gradients darbojas kā ieraksts un prognozētājs atšķirībai starp kļūdu biežumu (cik precīzi modelis pašlaik ir kartējis datu attiecības) un svērumiem (iestatījumiem, kas ietekmē veidu, kādā modelis mācīsies).
Šo progresa ierakstu var izmantot, lai informētu a mācību ātruma grafiks, automātisks process, kas liek arhitektūrai kļūt smalkākai un precīzākai, jo agrīnās neskaidrās detaļas pārvēršas skaidrās attiecībās un kartējumos. Faktiski gradienta zudums nodrošina precīzu karti par to, kur apmācībai vajadzētu notikt tālāk un kā tai vajadzētu turpināties.
Stochastic Gradient Descent inovācija ir tāda, ka tā atjaunina modeļa parametrus katrā apmācības piemērā vienā iterācijā, kas kopumā paātrina konverģences ceļu. Sakarā ar hipermēroga datu kopu parādīšanos pēdējos gados, SGD pēdējā laikā ir kļuvusi populāra kā viena no iespējamām metodēm, kā risināt radušās loģistikas problēmas.
No otras puses, SGD ir negatīvas sekas funkciju mērogošana, un var būt nepieciešams vairāk iterāciju, lai sasniegtu tādu pašu rezultātu, kas prasa papildu plānošanu un papildu parametrus, salīdzinot ar parasto Gradient Descent.
Populārs lietojums
Pateicoties tā konfigurējamībai un neskatoties uz trūkumiem, SGD ir kļuvis par populārāko optimizācijas algoritmu neironu tīklu pielāgošanai. Viena SGD konfigurācija, kas kļūst par dominējošo jauno AI/ML pētījumu dokumentos, ir adaptīvā momenta novērtējuma (ADAM, ieviests) izvēle. jo 2015) optimizētājs.
ADAM dinamiski pielāgo katra parametra mācīšanās ātrumu (“adaptīvā mācīšanās ātrums”), kā arī iekļauj iepriekšējo atjauninājumu rezultātus nākamajā konfigurācijā (“impulss”). Turklāt to var konfigurēt, lai izmantotu vēlākus jauninājumus, piemēram, Ņesterova impulss.
Tomēr daži apgalvo, ka impulsa izmantošana var arī paātrināt ADAM (un līdzīgus algoritmus) līdz a suboptimāls secinājums. Tāpat kā lielākajā daļā mašīnmācības pētniecības sektora izplūdušo malu, SGD ir darbs, kas turpinās.
Pirmo reizi publicēts 10. gada 2022. februārī. Grozīts 10. februārī 20.05 EET — formatējums.















