
Mākslīgais intelekts
Atdalīšana ir nākamā dziļā viltus revolūcija

CGI datu palielināšana tiek izmantota jaunā projektā, lai iegūtu lielāku kontroli pār dziļi viltotiem attēliem. Lai gan jūs joprojām nevarat efektīvi izmantot CGI galviņas, lai aizpildītu trūkstošās nepilnības dziļi viltotās sejas datu kopās, jauns pētījumu vilnis par identitātes nošķiršanu no konteksta nozīmē, ka drīzumā jums tas vairs nebūs jādara.
Dažu pēdējo gadu veiksmīgāko vīrusu dziļo viltojumu videoklipu veidotāji ļoti rūpīgi atlasa savus avota videoklipus, izvairoties no ilgstošiem profila kadriem (ti, tādiem sānu kadriem, ko popularizē policijas aizturēšanas procedūras), akūtiem leņķiem un neparastiem vai pārspīlētiem izteicieniem. . Arvien biežāk demonstrācijas videoklipi, ko veido vīrusu dziļi viltotāji, ir rediģētas kompilācijas, kurās tiek atlasīti “vieglākie” dziļuma viltošanas leņķi un izteiksmes.
Faktiski vispiemērotākais mērķa videoklips, kurā ievietot dziļi viltotu slavenību, ir tāds, kurā sākotnējā persona (kuras identitāti dzēsīs dziļais viltojums) skatās tieši kamerā ar minimālu izteicienu klāstu.

Lielākajā daļā pēdējo gadu populāro viltojumu ir redzami objekti, kas ir vērsti tieši pret kameru, un tajos ir tikai populāri izteicieni (piemēram, smaids), ko var viegli iegūt no sarkanā paparaci izdrukas, vai arī (kā ar Silvestra Stallones 2019. gada viltojumu). kā terminators, attēlā pa kreisi), ideālā gadījumā bez izteiksmes, jo neitrālie izteicieni ir ļoti izplatīti, tāpēc tos ir viegli iekļaut dziļi viltotos modeļos.
Tā kā deepfake tehnoloģijas, piemēram, DeepFaceLab un Sejas maiņa veikt šos vienkāršākos mijmaiņas darījumus ļoti labi, mēs esam pietiekami apžilbināti no viņu paveiktā, lai nepamanītu, uz ko viņi nav spējīgi, un bieži vien pat nemēģināt:

Iegūti no atzinību guvušā deepfake videoklipa, kurā Arnolds Švarcenegers tiek pārveidots par Silvestru Stalloni — ja vien leņķi nav pārāk sarežģīti. Profili joprojām ir ilgstoša problēma ar pašreizējām dziļo viltojumu pieejām, daļēji tāpēc, ka atvērtā pirmkoda programmatūra, ko izmanto, lai definētu sejas pozas dziļās viltošanas ietvaros, nav optimizēta skatiem no sāniem, bet galvenokārt tāpēc, ka vienā vai abos nepieciešamajos objektos trūkst piemērota izejmateriāla. datu kopas. Avots: https://www.youtube.com/watch?v=AQvCmQFScMA
Jauns pētījums Izraēla ierosina jaunu metodi sintētisko datu, piemēram, CGI galviņu, izmantošanai, lai 2020. gados ieviestu dziļu viltošanu, patiesi nošķirot sejas identitātes (ti, galvenās “Toma Krūza” sejas īpašības no visiem leņķiem) no konteksta (t. Meklēt, skatoties uz sāniem, sariecot, raustoties tumsā, uzacis sarauktas, aizvērtas acis, Utt.)

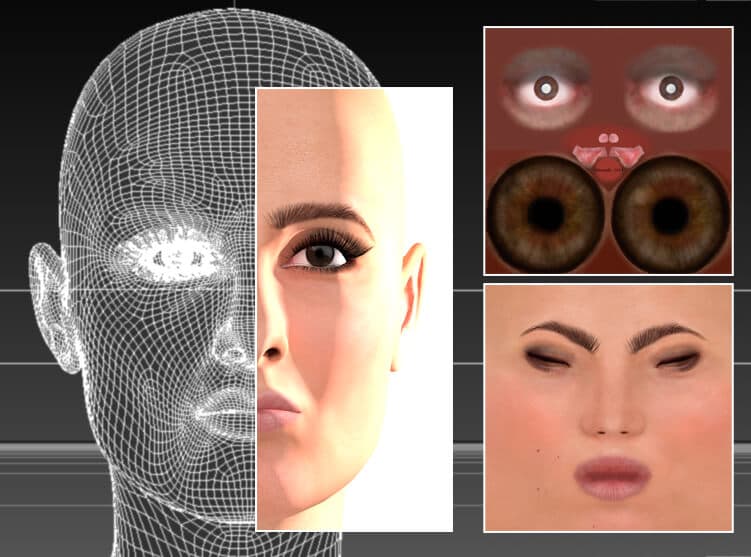
Jaunā sistēma diskrēti atdala pozu un kontekstu (ti, piemiedzot aci) no indivīda identitātes kodējuma, izmantojot nesaistītus sintētiskos sejas datus (attēlā pa kreisi). Augšējā rindā redzams uz Baraka Obamas identitāti pārnests acs acs, ko mudina apgūtais GAN latentās telpas nelineārais ceļš, ko attēlo CGI attēls kreisajā pusē. Zemāk esošajā rindā redzama izstieptā mutes stūra šķautne, kas pārnesta uz bijušo prezidentu. Apakšējā labajā stūrī mēs redzam, ka abi raksturlielumi tiek piemēroti vienlaikus. Avots: https://arxiv.org/pdf/2111.08419.pdf
Tas nav vienkārši deepfake head-leļļu teātris, paņēmiens, kas ir vairāk piemērots iemiesojumiem un daļējai sejas lūpu sinhronizēšanai, un kam ir ierobežots potenciāls pilnvērtīgām deepfake video transformācijām.
Tas drīzāk ir ceļš uz priekšu instrumentalitātes fundamentālai nodalīšanai (piemēram, "mainīt galvas leņķi", 'raukt pieri') no identitātes, piedāvājot ceļu uz augsta līmeņa, nevis uz “atvasinātu” attēlu sintēzi balstītu deepfake ietvaru.
Jaunajam papīram ir nosaukums Delta-GAN-kodētājs: semantisko izmaiņu kodēšana precīzai attēlu rediģēšanai, izmantojot dažus sintētiskos paraugus, un nāk no Technion – Izraēlas Tehnoloģiju institūta pētniekiem.
Lai saprastu, ko nozīmē darbs, apskatīsim, kā pašlaik tiek ražoti dziļi viltojumi visur, sākot no dziļi viltotām pornogrāfijas vietnēm līdz Rūpnieciskā gaisma un maģija (jo DeepFaceLab atvērtā pirmkoda repozitorijs pašlaik dominē gan "amatieru", gan profesionālajā dziļajā viltošanā).
Kas aizkavē pašreizējo Deepfake tehnoloģiju?
Deepfake pašlaik tiek veidotas, apmācot an kodētājs/dekodētājs mašīnmācīšanās modelis uz divām sejas attēlu mapēm — personai, kuru vēlaties “pārkrāsot” (iepriekšējā piemērā tas ir Ārnijs), un personai, kuru vēlaties ievietot materiālā (Sly).

Piemēri dažādām pozām un apgaismojuma apstākļiem divās dažādās sejās. Ņemiet vērā atšķirīgo izteiksmi trešās rindas beigās kolonnā A, kurai, visticamāk, nav tuvu ekvivalenta citā datu kopā.
Tad kodētāja/dekodētāja sistēma salīdzina katru attēlu katrā mapē savā starpā, uzturot, uzlabojot un atkārtojot šo darbību simtiem tūkstošu iterāciju (bieži vien pat nedēļu), līdz tā pietiekami labi izprot abu identitāšu būtiskos raksturlielumus, lai pēc vēlēšanās tās apmainītu.
Katram no diviem cilvēkiem, kas tiek apmainīti šajā procesā, dziļās viltus arhitektūra uzzina par identitāti sapinušies ar kontekstu. Tas nevar iemācīties un pielietot principus par vispārīgu pozu “uz labu un visiem”, bet apmācības datu kopā ir vajadzīgi bagātīgi piemēri katrai identitātei, kas tiks iesaistīta seju maiņā.
Tāpēc, ja vēlaties apmainīties ar divām identitātēm, kas dara kaut ko neparastāku, nekā tikai smaida vai skatās tieši kamerā, jums būs nepieciešams daudz šīs konkrētās pozas/identitātes gadījumi abās seju kopās:

Tā kā sejas ID un pozas raksturlielumi pašlaik ir tik ļoti savstarpēji saistīti, divās sejas datu kopās ir nepieciešama plaša izteiksmes, galvas pozas un (mazākā mērā) apgaismojuma paritāte, lai apmācītu efektīvu dziļo viltojumu modeli tādās sistēmās kā DeepFaceLab. Jo mazāk konkrētas konfigurācijas (piemēram, skats no sāniem/smaidošs/saules apspīdēts) abās seju kopās, jo neprecīzāk tā tiks atveidota dziļi viltotā videoklipā, ja nepieciešams.
Ja komplektā A ir neparastā poza, bet komplektā B tās trūkst, jums nav paveicies; neatkarīgi no tā, cik ilgi jūs apmācīsit modeli, tas nekad neiemācīsies labi atveidot šo pozu starp identitātēm, jo tai bija tikai puse no nepieciešamās informācijas, kad tā tika apmācīta.
Pat ja jums ir atbilstoši attēli, ar to var nepietikt: ja komplektam A ir atbilstoša poza, bet ar skarbu sānu apgaismojumu, salīdzinot ar plakanā apgaismojuma ekvivalentu pozu otrā sejas komplektā, maiņas kvalitāte uzvarēja. nav tik labi, it kā katram būtu kopīgas apgaismojuma īpašības.
Kāpēc datu ir maz
Ja vien jūs netiekat arestēts regulāri, iespējams, jums nav tik daudz sānprofila kadru ar sevi. Visu, kas radās, jūs, iespējams, izmetāt. Tā kā attēlu aģentūras rīkojas tāpat, profila sejas attēlus ir grūti atrast.
Deepfakers bieži iekļauj vairākas ierobežotā sānskata profila datu kopijas, kas viņiem ir identitātei sejas komplektā, lai poza iegūtu vismaz maz uzmanība un laiks treniņa laikā, nevis tiek atņemts kā an ārēji.

Taču ir daudz vairāk iespējamo veidu sānskata sejas attēlu, nekā varētu būt pieejams iekļaušanai datu kopā. smiling, saraucot pieri, kliedz, saucošs, tumši apgaismots, nievājošs, garlaicīgi, jautrs, zibspuldze apgaismota, Meklēt, skatīties lejā, acis vaļā, acis ciet…un tā tālāk. Jebkura no šīm pozām vairākās kombinācijās var būt nepieciešama mērķa dziļa viltota mērķa videoklipā.
Un tie ir tikai profili. Cik tev ir bilžu, kurās tu skaties taisni uz augšu? Vai jums ir pietiekami daudz, lai plaši pārstāvētu 10,000 XNUMX iespējamo izteicienu jūs varētu valkāt, turot tieši šo pozu no šī precīzā kameras leņķa, aptverot vismaz dažus no viens miljons iespējamo apgaismojuma vidi?
Pastāv iespēja, ka jums pat nav viens attēls, kurā jūs skatāties uz augšu. Un tie ir tikai divi leņķi no simts vai vairāk, kas nepieciešami pilnīgam pārklājumam.
Pat ja būtu iespējams ģenerēt pilnīgu sejas pārklājumu no visiem leņķiem dažādos apgaismojuma apstākļos, iegūtā datu kopa būtu pārāk liela, lai to apmācītu — simtiem tūkstošu attēlu; un pat ja tā varētu Apmācības process pašreizējām dziļi viltotām ietvariem izmestu lielāko daļu šo papildu datu par labu ierobežotam skaitam atvasinātu funkciju, jo pašreizējās sistēmas ir reducējošas un nav īpaši mērogojamas.
Sintētiskā aizstāšana
Kopš dziļo viltojumu sākuma dziļi viltotāji ir eksperimentējuši ar CGI stila attēlu izmantošanu, galvām, kas izgatavotas 3D lietojumprogrammās, piemēram, Cinema4D un Maya, lai radītu šīs "trūkstošās pozas".
Nav nepieciešams AI; aktrise tiek atjaunota tradicionālajā CGI programmā Cinema 4D, izmantojot tīklus un bitkartes faktūras – tehnoloģiju, kas aizsākās 1960. gadsimta 1990. gados, taču plaši tika izmantota tikai no XNUMX. gadiem. Teorētiski šo sejas modeli varētu izmantot, lai ģenerētu dziļi viltotus avota datus neparastām pozām, apgaismojuma stiliem un sejas izteiksmēm. Patiesībā tas ir bijis ierobežots vai vispār nav izmantots dziļajā viltošanā, jo apmainītajos videoklipos renderējumu “viltusums” mēdz izplūst. Avots: šī raksta autora attēls vietnē https://rossdawson.com/futurist/implications-of-ai/comprehensive-guide-ai-artificial-intelligence-visual-effects-vfx/
Jaunie dziļo viltojumu praktiķi parasti agri atsakās no šīs metodes, jo, lai gan tā var nodrošināt pozas un izteiksmes, kas citādi nav pieejamas, CGI seju sintētiskais izskats parasti izplūst līdz mijmaiņas darījumiem ID un kontekstuālās/semantiskās informācijas sapīšanās dēļ.
Tas var novest pie pēkšņas “neparastās ielejas” seju uzplaiksnīšanas citādi pārliecinošā dziļi viltotā videoklipā, jo algoritms sāk izmantot vienīgos datus, kas tam var būt par neparastu pozu vai izteiksmi — acīmredzami viltotām sejām.

Viens no populārākajiem dziļo viltojumu priekšmetiem ir Austrālijas aktrises Margotas Robijas 3D dziļās viltošanas algoritms. iekļauts noklusējuma instalācijā DeepFaceLive — DeepFaceLab versija, kas var veikt dziļos viltojumus tiešraides straumē, piemēram, tīmekļa kameras sesijā. CGI versiju, kā parādīts iepriekš, var izmantot, lai iegūtu neparastus “trūkstošus” leņķus dziļās viltotās datu kopās. Source: https://sketchfab.com/3d-models/margot-robbie-bust-for-full-color-3d-printing-98d15fe0403b4e64902332be9cfb0ace
CGI sejas kā atsevišķas, konceptuālas vadlīnijas
Tā vietā Izraēlas pētnieku jaunā Delta-GAN kodētāja (DGE) metode ir efektīvāka, jo poza un kontekstuālā informācija no CGI attēliem ir pilnībā atdalīta no mērķa "identitātes" informācijas.
Šo principu var redzēt darbībā zemāk esošajā attēlā, kur ir iegūtas dažādas galvas orientācijas, izmantojot CGI attēlus kā vadlīnijas. Tā kā identitātes iezīmes nav saistītas ar kontekstuālajām pazīmēm, nav redzams ne CGI sejas viltus izskata sintētiskais izskats, ne tajā attēlotā identitāte:

Izmantojot jauno metodi, jums nav jāatrod trīs atsevišķi reālās dzīves avota attēli, lai veiktu dziļu viltojumu no vairākiem leņķiem — jūs varat vienkārši pagriezt CGI galviņu, kuras augsta līmeņa abstraktās iezīmes tiek uzliktas identitātei, nenopludinot ID. informāciju.


Delta-GAN-kodētājs. Augšējā kreisā grupa: avota attēla leņķi var mainīt sekundē, lai renderētu jaunu avota attēlu, kas tiek atspoguļots izvadē; augšējā labā grupa: apgaismojums ir arī atdalīts no identitātes, ļaujot apvienot apgaismojuma stilus; apakšējā kreisā grupa: vairākas sejas detaļas tiek mainītas, lai radītu "skumju" izteiksmi; apakšējā labā grupa: tiek mainīta viena sejas izteiksmes detaļa, lai acis šķielētu.
Šī identitātes un konteksta nodalīšana tiek panākta apmācības posmā. Jaunās dziļās viltus arhitektūras konveijerā tiek meklēts latentais vektors iepriekš apmācītā ģeneratīvajā pretrunīgajā tīklā (Generative Adversarial Network — GAN), kas atbilst pārveidojamajam attēlam — Sim2Real metodoloģija, kas balstās uz 2018. projekts no IBM AI pētniecības sadaļas.
Pētnieki novēro:
“Izmantojot tikai dažus paraugus, kas atšķiras ar īpašu atribūtu, var uzzināt iepriekš apmācīta sapinušies ģeneratīvā modeļa atdalīto uzvedību. Lai sasniegtu šo mērķi, nav nepieciešami precīzi reālās pasaules paraugi, kas ne vienmēr ir iespējams.
"Izmantojot nereālistiskus datu paraugus, to pašu mērķi var sasniegt, izmantojot kodēto latento vektoru semantiku. Vēlamo izmaiņu piemērošanu esošajiem datu paraugiem var veikt bez skaidras latentās telpas uzvedības izpētes.
Pētnieki paredz, ka projektā izpētītos atdalīšanas pamatprincipus varētu pārnest uz citām jomām, piemēram, interjera arhitektūras simulācijām, un ka Delta-GAN-Encoder pieņemtā Sim2Real metode galu galā varētu nodrošināt dziļu viltojumu instrumentalitāti, kuras pamatā ir tikai skices, nevis CGI stila ievade.
Varētu apgalvot, ka tas, cik lielā mērā jaunā Izraēlas sistēma varētu vai nevarētu sintezēt dziļi viltotus videoklipus, ir daudz mazāk nozīmīgs nekā pētījuma progress konteksta nošķiršanā no identitātes, iegūstot lielāku kontroli pār latento telpu. no GAN.
Atdalīšana ir aktīvs attēlu sintēzes pētījumu lauks; 2021. gada janvārī Amazon vadīts pētījums papīrs demonstrēja līdzīgu pozu kontroli un atdalīšanu, un 2018. gadā a papīrs Ķīnas Zinātņu akadēmijas Šeņdžeņas progresīvo tehnoloģiju institūti ir panākuši progresu, veidojot patvaļīgus viedokļus GAN.















