인공 지능
OpenAI의 GPT-4o: 인간-기계 상호 작용을 변화시키는 다중 모드 AI 모델

OpenAI는 지금까지 가장 진보된 최신 언어 모델을 출시했습니다. GPT-4o, "옴니" 모델. 이 혁신적인 AI 시스템은 인간과 인공 지능 사이의 경계를 모호하게 만드는 기능을 갖춘 거대한 도약을 의미합니다.
GPT-4o의 핵심은 텍스트, 오디오, 이미지, 비디오 전반에 걸쳐 콘텐츠를 원활하게 처리하고 생성할 수 있는 기본 다중 모드 특성입니다. 여러 양식을 단일 모델로 통합한 것은 최초의 것으로, AI 보조자와 상호 작용하는 방식을 재구성할 것을 약속합니다.
그러나 GPT-4o는 단순한 다중 모드 시스템 그 이상입니다. 이전 모델인 GPT-4에 비해 놀라운 성능 향상을 자랑하며 Gemini 1.5 Pro, Claude 3 및 Llama 3-70B와 같은 경쟁 모델을 뒤흔들었습니다. 이 AI 모델이 진정으로 획기적인 이유가 무엇인지 자세히 살펴보겠습니다.
비교할 수 없는 성능과 효율성
GPT-4o의 가장 인상적인 측면 중 하나는 전례 없는 성능입니다. OpenAI의 평가에 따르면 이 모델은 이전 최고 성능을 발휘했던 GPT-60 Turbo에 비해 Elo 포인트가 4점이나 앞서 있습니다. 이러한 중요한 이점으로 GPT-4o는 현재 사용 가능한 가장 진보된 AI 모델을 능가하는 자체 리그에 속하게 됩니다.
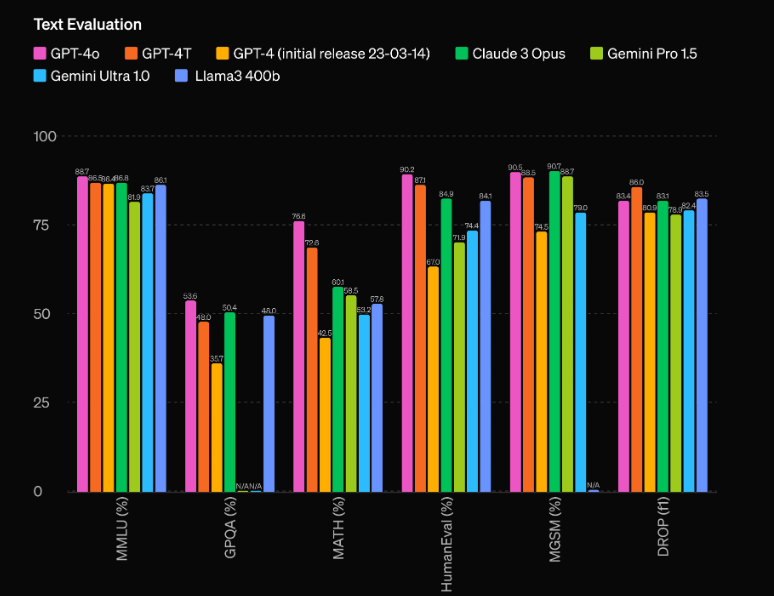
그러나 GPT-4o가 빛나는 유일한 영역은 원시 성능이 아닙니다. 이 모델은 또한 GPT-4 Turbo보다 두 배 빠른 속도로 작동하면서 작동 비용은 절반에 불과하여 인상적인 효율성을 자랑합니다. 우수한 성능과 비용 효율성의 조합으로 인해 GPT-4o는 최첨단 AI 기능을 애플리케이션에 통합하려는 개발자와 기업에게 매우 매력적인 제안입니다.
다중 모드 기능: 텍스트, 오디오 및 비전 혼합
아마도 GPT-4o의 가장 획기적인 측면은 기본 다중 모드 특성으로, 텍스트, 오디오, 비전을 포함한 여러 양식에 걸쳐 콘텐츠를 원활하게 처리하고 생성할 수 있습니다. 여러 양식을 단일 모델로 통합한 것은 최초의 사례이며 AI 비서와 상호 작용하는 방식에 혁명을 가져올 것을 약속합니다.
GPT-4o를 사용하면 사용자는 음성을 사용하여 자연스러운 실시간 대화에 참여할 수 있으며, 모델은 오디오 입력을 즉시 인식하고 응답합니다. 그러나 기능은 여기서 끝나지 않습니다. GPT-4o는 시각적 콘텐츠를 해석하고 생성할 수도 있어 이미지 분석 및 생성에서 비디오 이해 및 생성에 이르는 응용 분야의 가능성을 열어줍니다.
GPT-4o의 다중 모드 기능에 대한 가장 인상적인 시연 중 하나는 장면이나 이미지를 실시간으로 분석하고 인식하는 시각적 요소를 정확하게 설명하고 해석하는 능력입니다. 이 기능은 시각 장애인을 위한 보조 기술뿐만 아니라 보안, 감시, 자동화와 같은 분야에도 큰 영향을 미칩니다.
그러나 GPT-4o의 다중 모드 기능은 다양한 형식에 걸쳐 콘텐츠를 이해하고 생성하는 것 이상으로 확장됩니다. 또한 이 모델은 이러한 양식을 완벽하게 혼합하여 진정으로 몰입적이고 매력적인 경험을 만들어낼 수 있습니다. 예를 들어, OpenAI의 라이브 데모 중에 GPT-4o는 입력 조건을 기반으로 노래를 생성하여 언어, 음악 이론 및 오디오 생성에 대한 이해를 결합하여 일관되고 인상적인 출력을 생성할 수 있었습니다.
Python을 사용하여 GPT0 사용
import openai
# Replace with your actual API key
OPENAI_API_KEY = "your_openai_api_key_here"
# Function to extract the response content
def get_response_content(response_dict, exclude_tokens=None):
if exclude_tokens is None:
exclude_tokens = []
if response_dict and response_dict.get("choices") and len(response_dict["choices"]) > 0:
content = response_dict["choices"][0]["message"]["content"].strip()
if content:
for token in exclude_tokens:
content = content.replace(token, '')
return content
raise ValueError(f"Unable to resolve response: {response_dict}")
# Asynchronous function to send a request to the OpenAI chat API
async def send_openai_chat_request(prompt, model_name, temperature=0.0):
openai.api_key = OPENAI_API_KEY
message = {"role": "user", "content": prompt}
response = await openai.ChatCompletion.acreate(
model=model_name,
messages=[message],
temperature=temperature,
)
return get_response_content(response)
# Example usage
async def main():
prompt = "Hello!"
model_name = "gpt-4o-2024-05-13"
response = await send_openai_chat_request(prompt, model_name)
print(response)
if __name__ == "__main__":
import asyncio
asyncio.run(main())
나는 가지고있다:
- 사용자 정의 클래스를 사용하는 대신 openai 모듈을 직접 가져왔습니다.
- openai_chat_resolve 함수의 이름을 get_response_content로 변경하고 구현을 약간 변경했습니다.
- AsyncOpenAI 클래스를 OpenAI Python 라이브러리에서 제공하는 공식 비동기 메서드인 openai.ChatCompletion.acreate 함수로 대체했습니다.
- send_openai_chat_request 함수를 사용하는 방법을 보여주는 예제 기본 함수를 추가했습니다.
코드가 올바르게 작동하려면 "your_openai_api_key_here"를 실제 OpenAI API 키로 바꿔야 합니다.


















