인공지능
새로운 Deepfake 방법은 ‘얼굴 호스트’ 문제를 해결한다

여러 해에 걸쳐 디프페이크 이미지로 인해 비디오 영상을 실제로 믿을 수 있는지에 대한 우리의 오랜 신뢰가 흔들릴 수 있다는 매체의 과장에도 불구하고, 현재 인기 있는 모든 방법은 대상을 닮은 모양의 ‘얼굴 호스트’를 찾는 데 의존한다.
원래 영상을 넓은 얼굴로 특징지을 수 있지만 대상 주체는 좁은 얼굴을 가지고 있는 경우, 결과는 항상 문제가 있었는데, 이는 그러한 전송이 원래 얼굴의 일부를 절단하고 이제 노출된 배경을 재구성하는 것을 포함하기 때문이다. 현재 패키지인 DeepFaceLab과 FaceSwap은 구성이 반대인 경우(좁은>넓은) 제한된 결과를 생성할 수 있지만 그러한 시나리오를 уб적으로 해결할 수 있는 시설이 없다.
이제 텐센트와 중국의 시아먼 대학 간의 협력이 ‘얼굴 호스트’ 문제를 해결하기 위해 설계된 새로운 접근 방식을 개발했다.

두 개의 HifiFace 디프페이크, 첫 번째는 앤 해서웨이로 호환되지 않는 호스트 얼굴 모양에도 불구하고 좋은 유사성을 얻는다. HifiFace는 또한 전통적으로 디프페이크에서 걸림돌이 되는 안경을 쓴 대상에 대해 잘 작동한다. 출처: https://arxiv.org/pdf/2106.09965.pdf
디프페이크 얼굴 재구성
이전 접근 방식은 2019年的 주제 불변 얼굴 스와핑 및 재연산(FSGAN)과 같이 3DMM 피팅(3D Morphable Models) 또는 얼굴 랜드마크 인식 또는 변환을 기반으로 하는 다른 방법론에 의존했다. 여기서 얼굴의 선명한 특징은 스와핑의 범위를 결정한다.

3DMM 얼굴 랜드마크 감지. 출처: https://github.com/Yinghao-Li/3DMM-fitting
경쟁 방법은 얼굴 인식 네트워크에서 파생된 기능을 사용했지만, 이는 주로 질감을 재구성하는 데 사용되며, 호스트 얼굴이 완전히 호환되지 않는 경우(즉, 모발, 턱선, 광대뼈의 한계와 모양) 마스크와 같은 효과를 낸다.
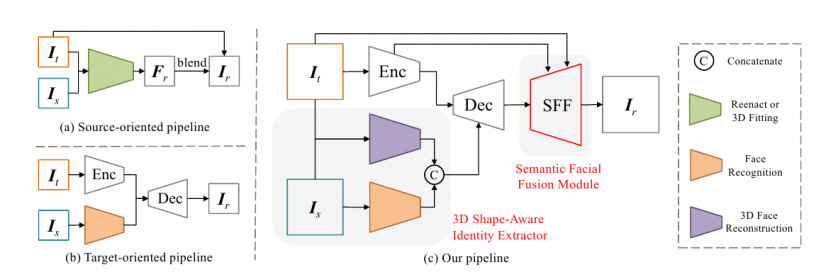
이러한 문제를 해결하기 위해, 중국의 연구자들은 대학의 인공 지능부 미디어 분석 및 컴퓨팅 연구소에 기반을 두고, 3D 재구성 모델을 사용하여 대상과 원본 얼굴의 계수를 회귀하는 엔드 투 엔드 네트워크를 개발했다. 그런 다음 이는 모양 정보로 재결합되고, 얼굴 인식 네트워크에서 파생된 아이디 벡터 정보와 함께 연결된다.
이 기하학적 데이터는 구조 정보로 인코더-디코더 모델에 입력되어, 대상 얼굴의 표현과 배치와 함께 블렌딩된다. 이는 정확한 전송을 위한 보조 소스로 사용된다.

语义 얼굴 융합
또한, HifiFace에는语义 얼굴 융합(SFF) 구성 요소가 포함되어 있다. 이는 인코더의 저수준 기능을 사용하여 공간 및 텍스처 정보를 보존하면서, 대상 이미지의 아이덴티티를 희생하지 않는다. 인코더와 디코더의 기능은 학습된 적응 마스크로 통합되고, 배경 정보는 학습된 얼굴 마스크를 통해 출력으로 블렌딩된다.

HifiFace 동작. 출처: https://johann.wang/HifiFace/
이러한 방식으로, HifiFace는 원래 물질의 얼굴 경계를 사용하여 경계를 설정하는 대신, 확장된 얼굴语义 분할을 사용하여 모델이 얼굴의 경계에서 더 나은 적응 융합을 수행할 수 있다.

이전 두 가지 접근 방식(위쪽과 아래쪽 왼쪽)과 새로운 HifiFace 아키텍처, 이는 인코더, 디코더, 3D 모양 인식 아이디 추출기 및 SFF 모듈로 구성된다.

이전 방법과 비교하여, HifiFace는 이전 방법 FSGAN, SimSwap 및 FaceShifter와 비교하여 얼굴 모양의 재구성을 더 잘 보여준다. 이는 ‘고스트’ 요소를 근사하지 않고, 대신 명확하게 재구성하기 때문이다.

테스트
연구자들은 시스템을 VGGFace2 및 DeepGlint Asian-Celeb 데이터 세트를 사용하여 구현했다. 얼굴은 5개의 외부 랜드마크를 통해 정렬되었으며, 256×256 픽셀로 재자르기했다. 또한 512×512 픽셀 버전을 생성하기 위해 초상화 강화 네트워크를 사용했다. 모델은 Adam하에서 훈련되었다.

FaceShifter는 아이덴티티를 잘 보존하지만, HifiFace와 같은 표현, 색상 및 가려짐과 같은 문제를 효과적으로 해결하지 못하며, 더 복잡한 네트워크 구조를 가지고 있다. FSGAN은 원본에서 대상으로의 조명 전송에 문제가 있다.
연구자들은 FaceForensics++를 사용하여 양적 비교를 수행했으며, 경쟁 방법과 비교하여 HifiFace가 더 우수한 아이디 검색 점수를 얻었다. 다른 요인들, 예를 들어 이미지 품질을 테스트함으로써, 연구자들은 또한 자신의 방법이 라이벌 방법론을 능가한다는 것을 발견했다.

베네딕트 컴버배치의 얼굴 특징이 충실하게 재현된다.
이 연구는 원본 자료를 추상화하여 정확한 아이덴티티를 전송할 수 있는 템플릿으로 만드는 또 하나의 단계이다. 현재 일부 오픈 소스 패키지, DeepFaceLab을 포함하여, 전체 머리 대체에 대한 초기 기능을 특징으로 하지만, HifiFace와 마찬가지로, 이는 모발을 고려하지 않으며, 원하는 대상 소스를 일치시키기 위해 얼굴을 깎아내리는 것보다 얼굴을 구축하는 데 더 효과적이다.













{kind=link}
{kind=link}
{kind=link}
{kind=link}