AI 101
ベイズの定理とは?
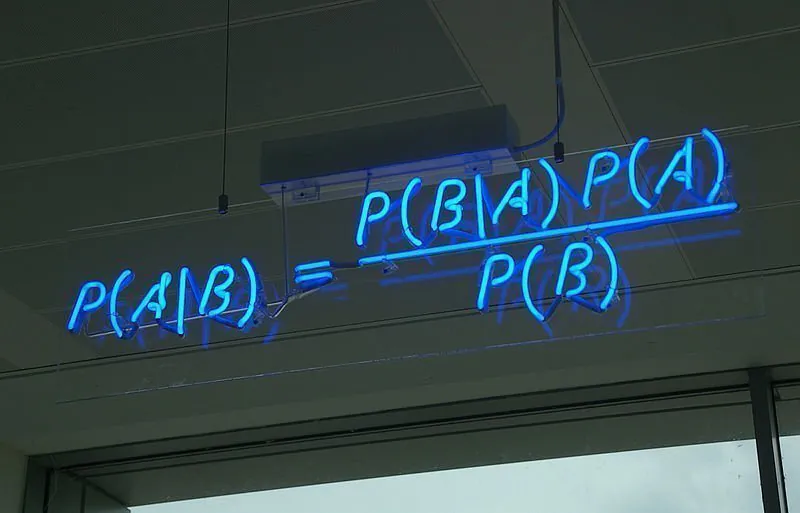
データサイエンスや機械学習について学習している場合、ベイズの定理またはベイズ分類器という用語を以前聞いたことがあるかもしれません。これらの概念は、伝統的な頻度主義統計学の観点から確率を考えることに慣れていない場合、少し混乱する可能性があります。この記事では、ベイズの定理の背後にある原理と、機械学習でどのように使用されるかを説明します。
ベイズの定理とは?
ベイズの定理は、条件付き確率を計算する方法です。条件付き確率(あるイベントが発生した場合に別のイベントが発生する確率)を計算する伝統的な方法は、条件付き確率の式を使用して、イベント1とイベント2が同時に発生する合同確率を計算し、それをイベント2が発生する確率で割ることです。ただし、条件付き確率は、ベイズの定理を使用して、少し異なる方法で計算することもできます。
ベイズの定理を使用して条件付き確率を計算する場合、次の手順に従います:
- 条件Aが真であると仮定して、条件Bが真である確率を決定します。
- イベントAが真である確率を決定します。
- 2つの確率を掛け合わせます。
- イベントBが発生する確率で割ります。
これは、ベイズの定理の式が次のように表現できることを意味します:
P(A|B) = P(B|A)*P(A) / P(B)
条件付き確率をこのように計算することは、逆の条件付き確率を簡単に計算できる場合、または合同確率を計算するのが非常に困難な場合に特に役立ちます。
ベイズの定理の例
これは、ベイズの定理とベイズ的推論をどのように適用するかを示す例を見てみることで、より簡単に解釈できるかもしれません。複数の参加者が物語を語り、どの参加者があなたに嘘を言っているかを判断する必要があるシンプルなゲームを想像してください。ベイズの定理の式にこの仮想シナリオの変数を埋め込んでみましょう。
私たちは、各個人が嘘を言っているか真実を言っているかを予測しようとしています。したがって、参加者が3人いる場合、カテゴリ変数はA1、A2、A3と表すことができます。彼らの嘘/真実の証拠は、彼らの行動です。ポーカーをプレイするように、嘘を言っている人が出す「テール」を探して、それを情報として使用してあなたの推測を情報に基づいて行うことができます。または、質問することが許可されていた場合は、彼らの話が一致していない証拠が見つかります。彼らが嘘を言っている証拠をBと表すことができます。
明確に言うと、行動の証拠が与えられた場合にAが嘘を言っている/真実を言っている確率を予測しようとしています。彼らが本当に嘘を言っている/真実を言っている場合に、見ている行動が最も意味を成す条件を判断しようとしています。見ている行動が3つある場合、各行動について計算を行う必要があります。たとえば、P(B1, B2, B3 * A)です。ゲームに参加している人ごとに、A/各人についてこれを行う必要があります。これは、上記の式の次の部分です:
P(B1, B2, B3,|A) * P|A
最終的に、それをBの確率で割ります。
この式の実際の確率についての証拠を受け取った場合、観測されたイベントの事前の確率についての仮定を更新して、確率モデルを再作成します。これは、事前の確率を更新することとして知られています。
ベイズの定理の機械学習への応用
ベイズの定理を機械学習で使用する最も一般的な方法は、ナイーブベイズアルゴリズムの形式です。
ナイーブベイズは、バイナリとマルチクラスの両方のデータセットの分類に使用されます。ナイーブベイズは、証拠/属性 – Bs in P(B1, B2, B3 * A) – に割り当てられた値が相互に独立しているという仮定に基づいています。モデルを簡素化し、計算を可能にするために、これらの属性が互いに影響を与えないと仮定します。複雑なタスクである各属性間の関係を計算するのではなく、ナイーブベイズは分類アルゴリズムとしてかなりよく機能します。つまり、ほとんどの場合、この仮定は真実ではないでしょう。
ナイーブベイズ分類器の一般的なバリエーションには、多項ナイーブベイズ、ベルヌーイナイーブベイズ、ガウシアンベイズがあります。
多項ナイーブベイズアルゴリズムは、ドキュメントの分類に頻繁に使用されます。ドキュメント内の単語の頻度を解釈するのに効果的だからです。
ベルヌーイナイーブベイズは、多項ナイーブベイズと同様に機能しますが、アルゴリズムによって生成される予測はブール値です。つまり、クラスを予測するときに、値はバイナリになります。テキスト分類のドメインでは、ベルヌーイナイーブベイズアルゴリズムは、単語がテキストドキュメント内に存在するかどうかによって、パラメータにはいまたはいいえを割り当てます。
予測子/特徴の値が離散的ではなく連続的である場合、ガウシアンベイズを使用できます。特徴の連続値はガウシアンベースからサンプリングされたものと想定されます。












