AI 101
CNNs(Convolutional Neural Networks)とは何か?
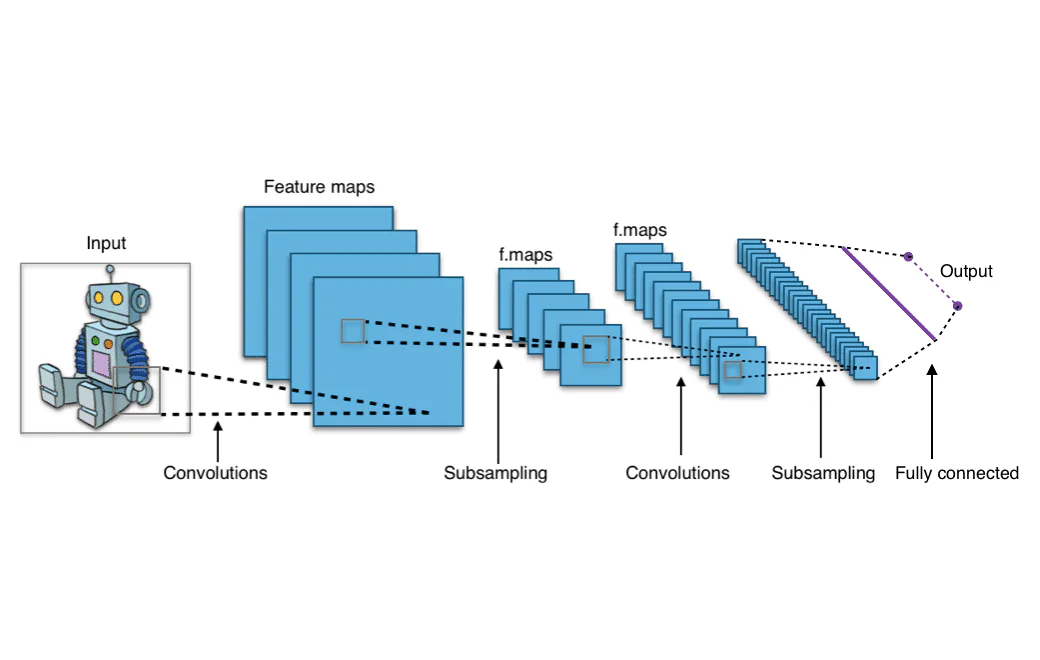
もしもあなたは、FacebookやInstagramが画像の中の顔を自動的に認識する方法、またはGoogleがあなたのアップロードした画像と似た写真を検索できる方法について疑問に思ったことがあるかもしれません。これらの機能は、コンピュータビジョンの例であり、畳み込みニューラルネットワーク(CNNs)によって動作します。ただし、畳み込みニューラルネットワークとは何でしょうか?CNNのアーキテクチャに深く潜り込み、どのように動作するかを理解してみましょう。
ニューラルネットワークとは何か?
畳み込みニューラルネットワークについて話し始める前に、通常のニューラルネットワークを定義してみましょう。ニューラルネットワークについての別の記事があるため、ここでは詳細に説明しません。しかし、簡単に説明すると、ニューラルネットワークは人間の脳にインスパイアされた計算モデルです。ニューラルネットワークは、データを受け取り、「重み」を調整することによってデータを操作します。重みは、入力特徴が互いに、またオブジェクトのクラスに関連しているという仮定です。ネットワークがトレーニングされると、重みの値が調整され、最終的に特徴間の関係を正確に捉える重みに収束することが期待されます。
これがフィードフォワードニューラルネットワークの動作方法であり、CNNはフィードフォワードニューラルネットワークと畳み込み層の2つの部分で構成されています。
畳み込みニューラルネットワーク(CNNs)とは何か?
畳み込みニューラルネットワークで起こる「畳み込み」とは何か?畳み込みは、画像の部分を表現する重みのセットを作成する数学演算です。この重みのセットは、カーネルまたはフィルタと呼ばれます。作成されるフィルタは、入力画像よりも小さく、画像のサブセクションのみをカバーします。フィルタ内の値は画像内の値と乗算され、フィルタは新しい画像の部分を表現するために移動され、このプロセスは画像全体がカバーされるまで繰り返されます。
別の方法としては、入力画像のピクセルを表すレンガの壁を想像し、フィルタをスライドさせながら壁を移動する「窓」を想像します。窓から見えるレンガは、フィルタ内の値と乗算されるピクセルです。このため、この方法は「スライディングウィンドウ」テクニックと呼ばれます。
画像全体を移動するフィルタからの出力は、画像全体を表す二次元配列です。この配列は「特徴マップ」と呼ばれます。
畳み込みの重要性
畳み込みを作成する目的は何でしょうか?畳み込みは、ニューラルネットワークが画像のピクセルを数値値として解釈できるようにするために必要です。畳み込み層の機能は、画像をニューラルネットワークが解釈し、関連するパターンを抽出できる数値値に変換することです。畳み込みネットワークのフィルタの役割は、後続のニューラルネットワークの層に渡されることができる二次元配列の値を作成することです。
フィルタとチャンネル
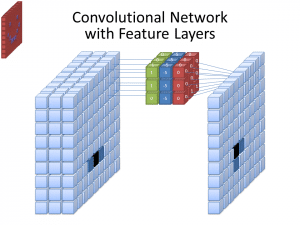
Photo: cecebur via Wikimedia Commons, CC BY SA 4.0 (https://commons.wikimedia.org/wiki/File:Convolutional_Neural_Network_NeuralNetworkFeatureLayers.gif)










