テキストプロンプトから3Dデジタルアセットを生成する能力は、AIとコンピュータグラフィックスの分野で最も興奮する最近の開発の1つです。3Dデジタルアセット市場は、2024年に283億ドルから2029年に518億ドル に成長すると予測されており、テキストから3D AIモデルは、ゲーム、映画、電子商取引などさまざまな業界でのコンテンツ作成を革命的に変える役割を果たす可能性があります。しかし、これらのAIシステムはどうやって正確に機能するのでしょうか。この記事では、テキストから3D生成の背後にある技術的な詳細に深く掘り下げます。
3D生成の課題
テキストから3Dアセットを生成することは、2D画像生成よりもはるかに複雑なタスクです。2D画像は基本的にピクセルのグリッドですが、3Dアセットには、3D空間での幾何学、テクスチャ、材料、そしてしばしばアニメーションを表現する必要があります。この追加の次元と複雑さにより、生成タスクははるかに困難になります。
テキストから3D生成の重要な課題には、以下のものがあります。
3D幾何学と構造を表現する
3D表面全体に一貫したテクスチャと材料を生成する
物理的に妥当で、複数の視点からの整合性を確保する
微細な詳細とグローバル構造を同時に捉える
レンダリングまたは3Dプリンティングが容易なアセットを生成する
これらの課題に対処するために、テキストから3Dモデルは、以下のいくつかの重要な技術とテクニックを利用しています。
テキストから3Dシステムの重要なコンポーネント
ほとんどの最先端のテキストから3D生成システムには、以下のいくつかの共通のコンポーネントがあります。
テキストエンコーディング : 入力テキストプロンプトを数値表現に変換する3D表現 : 3D幾何学と外観を表現する方法生成モデル : 3Dアセットを生成するためのコアAIモデルレンダリング : 3D表現を2D画像に変換するために使用されるレンダリング
それぞれについて詳しく見てみましょう。
テキストエンコーディング
最初のステップは、入力テキストプロンプトをAIモデルが利用できる数値表現に変換することです。これは通常、BERTやGPT などの大規模言語モデルを使用して行われます。
3D表現
3D幾何学をAIモデルで表現する一般的な方法は以下のとおりです。
ボクセルグリッド : 3D配列の値で、占有または機能を表現する点群 : 3D点のセットメッシュ : 頂点と面で表面を定義する暗黙的関数 : 3D空間で表面を定義する連続関数(例:符号付き距離関数)ニューラル放射率場 (NeRFs)
それぞれに解像度、メモリ使用量、生成の容易さに関するトレードオフがあります。最近のモデルでは、NeRFsや暗黙的関数を使用することが多く、計算要件が妥当な範囲内で高品質の結果を得ることができます。
たとえば、単純な球体を符号付き距離関数として表現できます。
import numpy as np
def sphere_sdf(x, y, z, radius=1.0):
return np.sqrt(x**2 + y**2 + z**2) - radius
# 3D点でSDFを評価する
point = [0.5, 0.5, 0.5]
distance = sphere_sdf(*point)
print(f"球面の表面からの距離: {distance}")
生成モデル
テキストから3Dシステムのコアは、テキスト埋め込み から3Dアセットを生成する生成モデルです。ほとんどの最先端モデルは、2D画像生成で使用されるものと同様の拡散モデルを使用しています。
拡散モデルは、データに徐々にノイズを加え、次にこのプロセスを逆にすることを学習することで機能します。3D生成の場合、このプロセスは選択した3D表現の空間で発生します。
拡散モデルのトレーニングステップの簡略化された疑似コードは以下のようになります。
def diffusion_training_step(model, x_0, text_embedding):
# ランダムなタイムステップをサンプリングする
t = torch.randint(0, num_timesteps, (1,))
# 入力にノイズを加える
noise = torch.randn_like(x_0)
x_t = add_noise(x_0, noise, t)
# ノイズを予測する
predicted_noise = model(x_t, t, text_embedding)
# ロスを計算する
loss = F.mse_loss(noise, predicted_noise)
return loss
# トレーニングループ
for batch in dataloader:
x_0, text = batch
text_embedding = encode_text(text)
loss = diffusion_training_step(model, x_0, text_embedding)
loss.backward()
optimizer.step()
生成中は、純粋なノイズから始めて、テキスト埋め込みに基づいて反復的にノイズ除去を行います。
レンダリング
結果を視覚化し、トレーニング中にロスを計算するために、3D表現を2D画像にレンダリングする必要があります。これは、レンダリングプロセスを介して逆伝播できる微分可能なレンダリング技術を使用して行われます。
メッシュベースの表現の場合、ラスタライズベースのレンダラーを使用する可能性があります。
import torch
import torch.nn.functional as F
import pytorch3d.renderer as pr
def render_mesh(vertices, faces, image_size=256):
# レンダラーを作成する
renderer = pr.MeshRenderer(
rasterizer=pr.MeshRasterizer(),
shader=pr.SoftPhongShader()
)
# カメラを設定する
cameras = pr.FoVPerspectiveCameras()
# レンダリングする
images = renderer(vertices, faces, cameras=cameras)
return images
# 例の使用法
vertices = torch.rand(1, 100, 3) # ランダムな頂点
faces = torch.randint(0, 100, (1, 200, 3)) # ランダムな面
rendered_images = render_mesh(vertices, faces)
NeRFなどの暗黙的表現の場合、レンダリングには通常レイマーチング技術を使用します。
まとめ: テキストから3Dパイプライン
ここで、重要なコンポーネントについて説明しました。次に、典型的なテキストから3D生成パイプラインでどのようにまとめられるかを見てみましょう。
テキストエンコーディング : 入力プロンプトは、言語モデルを使用して濃密なベクトル表現にエンコードされます。初期生成 : テキスト埋め込みに基づいて、拡散モデルが初期の3D表現(例:NeRFまたは暗黙的関数)を生成します。マルチビュー整合性 : モデルは生成された3Dアセットの複数のビューをレンダリングし、視点間の整合性を確保します。精緻化 : 追加のネットワークが幾何学、テクスチャ、または詳細を精緻化する場合があります。最終出力 : 3D表現は、ダウンストリームアプリケーションで使用するために望ましい形式(例:テクスチャ化メッシュ)に変換されます。
これは、コードでどのように見えるかについて、簡略化された例です。
class TextTo3D(nn.Module):
def __init__(self):
super().__init__()
self.text_encoder = BertModel.from_pretrained('bert-base-uncased')
self.diffusion_model = DiffusionModel()
self.refiner = RefinerNetwork()
self.renderer = DifferentiableRenderer()
def forward(self, text_prompt):
# テキストをエンコードする
text_embedding = self.text_encoder(text_prompt).last_hidden_state.mean(dim=1)
# 初期の3D表現を生成する
initial_3d = self.diffusion_model(text_embedding)
# 複数のビューをレンダリングする
views = self.renderer(initial_3d, num_views=4)
# マルチビュー整合性に基づいて精緻化する
refined_3d = self.refiner(initial_3d, views)
return refined_3d
# 使用法
model = TextTo3D()
text_prompt = "赤いスポーツカー"
generated_3d = model(text_prompt)
利用可能なトップテキストから3Dアセットモデル
3DGen – Meta
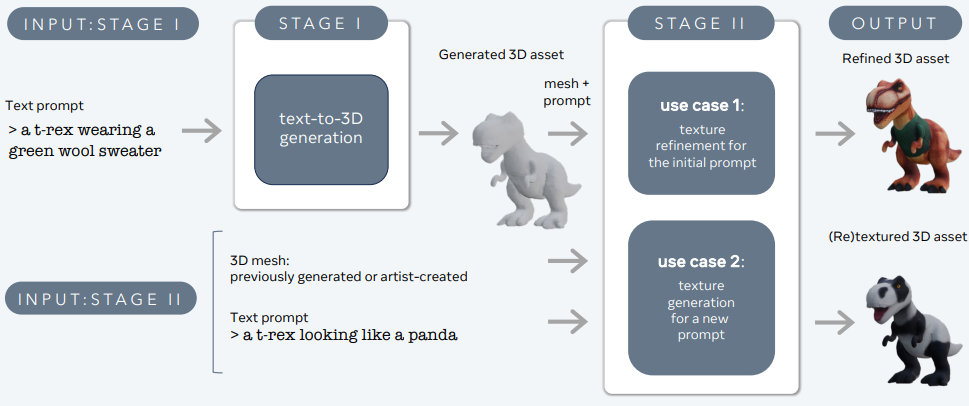
3DGen は、テキストの説明から3Dコンテンツ(キャラクター、プロップ、シーンなど)を生成する問題に対処するように設計されています。
3DGenは、物理ベースのレンダリング(PBR)をサポートしており、実際のアプリケーションで3Dアセットのリアライトを行うために不可欠です。また、以前生成された、またはアーティストによって作成された3D形状の新しいテキスト入力で生成される3D形状の再テクスチャリングを可能にします。パイプラインには、テキストから3Dとテキストからテクスチャの生成を担当する2つのコアコンポーネント、Meta 3D AssetGenとMeta 3D TextureGenが統合されています。
Meta 3D AssetGen
Meta 3D AssetGen(Siddiqui et al.、2024)は、テキストプロンプトから初期の3Dアセットを生成する責任があります。このコンポーネントは、約30秒でテクスチャとPBRマテリアルマップを備えた3Dメッシュを生成します。
Meta 3D TextureGen
Meta 3D TextureGen(Bensadoun et al.、2024)は、AssetGenによって生成されたテクスチャを精緻化します。また、既存の3Dメッシュの新しいテクスチャを追加のテキスト説明に基づいて生成することもできます。このステージには約20秒かかります。
Point-E (OpenAI)
Point-E, developed by OpenAI は、もう1つの注目すべきテキストから3D生成モデルです。DreamFusionとは異なり、NeRF表現を生成するのではなく、Point-Eは3D点群を生成します。
Point-Eの重要な機能:
a) 2段階パイプライン : Point-Eは、テキストから画像拡散モデルを使用して合成2Dビューを生成し、次にこの画像を条件として3D点群を生成する2番目の拡散モデルを使用します。
b) 効率性 : Point-Eは計算効率が高く設計されており、単一のGPUで数秒で3D点群を生成できます。
c) 色情報 : モデルは、幾何学的および外観情報を保存したカラーポイントクラウドを生成できます。
制限:
メッシュベースまたはNeRFベースのアプローチに比べて、忠実度が低い
多くのダウンストリームアプリケーションでは、ポイントクラウドを追加処理する必要があります
Shap-E (OpenAI):
Point-Eを基に、OpenAIはShap -Eを導入しました。これは、代わりに3Dメッシュを生成します。これにより、Point-Eのいくつかの制限が解消され、計算効率も維持されます。
Shap-Eの重要な機能:
a) 暗黙的表現 : Shap-Eは、3Dオブジェクトの符号付き距離関数などの3Dオブジェクトの暗黙的表現を生成することを学習します。
b) メッシュ抽出 : モデルは、メッシュを抽出するために、行進キューブアルゴリズムの微分可能な実装を使用します。
c) テクスチャ生成 : Shap-Eは、3Dメッシュのテクスチャも生成できます。これにより、より視覚的に美しい出力が得られます。
利点:
高速生成時間(数秒から数分)
レンダリングやダウンストリームアプリケーションに適した直接メッシュ出力
幾何学とテクスチャの両方を生成する能力
GET3D (NVIDIA):
GET3D は、NVIDIAの研究者によって開発された、テキストから3D生成モデルです。これは、高品質のテクスチャ化された3Dメッシュを生成することに重点を置いています。
GET3Dの重要な機能:
a) 明示的な表面表現 : DreamFusionやShap-Eとは異なり、GET3Dは中間の暗黙的表現を使用せずに、明示的な表面表現(メッシュ)を直接生成します。
b) テクスチャ生成 : モデルには、高品質のテクスチャをメッシュに生成するための微分可能なレンダリング技術が含まれています。
c) GANベースのアーキテクチャ : GET3Dは、生成対抗ネットワーク(GAN)アプローチを使用しており、モデルがトレーニングされた後は高速に生成できます。
利点:
高品質の幾何学とテクスチャ
高速な推論時間
3Dレンダリングエンジンとの直接統合
制限:
一部のオブジェクトカテゴリでは、3Dトレーニングデータが不足している可能性があります
結論
テキストから3D AI生成は、3Dコンテンツの作成とインタラクション方法に根本的な変化をもたらします。高度なディープラーニング技術を利用することで、これらのモデルは、単純なテキスト説明から複雑で高品質の3Dアセットを生成できます。テクノロジーが進化を続けるにつれて、ゲーム、映画、製品設計、建築など、さまざまな業界を変革する、ますます高度で有能なテキストから3Dシステムが見られるようになることが予想されます。