人工知能
AIの推論の進化: チェーンからイテレーティブな戦略と階層的な戦略へ
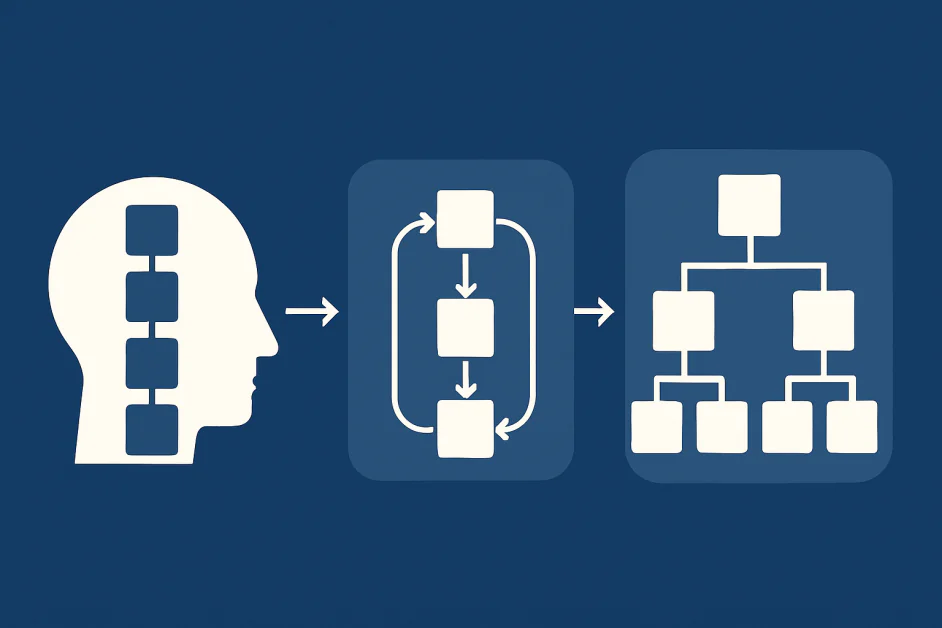
過去数年間、chain-of-thought promptingは、大規模言語モデルにおける推論の中心的な方法となりました。モデルに「大声で考えろ」と促すことで、研究者はステップバイステップの説明が数学や論理などの分野での精度を向上させることを発見しました。ただし、タスクがより複雑になると、CoTの限界が明らかになります。CoTは慎重に選択された推論の例に依存しているため、例よりも簡単または難しいタスクを扱うことが難しくなります。CoTは言語モデルに構造化された思考を導入しましたが、現在、複雑なマルチステップの問題を扱うために、より新しいアプローチが必要です。したがって、研究者はイテレーティブな推論や階層的な推論などの新しい戦略を探究しています。これらの方法は、推論をより深く、効率的で、堅牢にすることを目的としています。この記事では、CoTの限界、CoTの進化、そしてAIの推論のスケーラビリティのためのアプリケーション、課題、将来の方向性について説明します。
Chain-of-Thoughtの限界
CoT推論は、モデルがタスクを小さなステップに分解できるようにすることで、複雑なタスクを扱うことを可能にしました。この能力は、数学のコンテスト、論理パズル、プログラミングタスクなどのベンチマーク結果を向上させるだけでなく、中間ステップを公開することで透明性も提供します。ただし、CoTには課題もあります。研究によると、CoTは、シンボリック推論や精密な計算が必要な問題で最も効果的です。ただし、オープンエンドの質問、コモンスンス推論、または事実の回想の場合、CoTは精度を向上させるのではなく、むしろ低下させることがあります。
CoTは本質的に線形です。モデルは答えに至る一連のステップを生成します。これは、短い、明確に定義された問題にはうまく機能しますが、タスクがより深い探索を必要とする場合には苦労します。さらに、複雑な推論には、分岐、バックトラッキング、仮定の再検討が含まれます。単一の線形チェーンではこれを捉えることができません。モデルが初期のミスを犯すと、すべての後のステップが崩壊します。推論が正しい場合でも、線形出力は新しい情報に適応したり、以前の仮定を再確認したりすることはできません。現実世界の推論には、CoTが提供できない柔軟性が必要です。
研究者はまた、スケーラビリティの問題を強調しています。モデルがより難しいタスクに直面すると、チェーンは長くなり、より壊れやすくなります。複数のチェーンをサンプリングすることは役立ちますが、すぐに非効率的になります。質問は、狭い、単一のパス推論からより堅牢な戦略に移行する方法は何であるかです。
イテレーティブな推論としての次のステップ
一つの有望な方向性はイテレーションです。最終的な答えを一回で生成するのではなく、モデルは推論、評価、改良のサイクルを繰り返します。これは、人々が難しい問題を解決するために、まず解決策を草案化し、チェックし、弱点を特定し、段階的に改良する方法を反映しています。
イテレーティブな方法により、モデルはミスから回復し、代替ソリューションを探索できます。モデルは自身の推論を批判したり、複数のモデルが互いに批判したりするフィードバックループを作成します。一つの強力なアイデアは自己一致性です。単一の思考チェーンを信頼するのではなく、モデルは多くの推論パスをサンプリングし、最も共通の答えを選択します。これは、学生が問題を複数の方法で試みてから答えを信頼することを模倣しています。研究によると、複数の推論パスを集約することで信頼性が向上します。より最近の研究は、このアイデアを構造化されたイテレーションに拡張し、出力を繰り返しチェックし、修正し、拡張します。
この能力により、モデルは外部ツールを使用できます。イテレーションにより、モデルは検索エンジン、ソルバー、またはメモリシステムをループに簡単に統合できます。単一の答えにコミットするのではなく、モデルは外部リソースに照会し、推論を再考し、ステップを修正できます。イテレーションにより、推論は静的なチェーンではなく、ダイナミックなプロセスになります。
複雑性への階層的なアプローチ
イテレーションだけでは、タスクが非常に大きくなる場合には不十分です。長いホライズンやマルチステージのプランニングが必要な問題の場合、階層性は不可欠です。人間は常に階層的な推論を使用します。タスクをサブ問題に分解し、目標を設定し、構造化された層でそれらを解決します。モデルも同じ能力が必要です。
階層的な方法により、モデルはタスクを小さなステップに分解し、並行または順序でそれらを解決できます。プログラムオブソートとツリーオブソートに関する研究は、この方向性を強調しています。フラットなチェーンではなく、推論はツリーまたはグラフとして組織化され、複数のパスを探索および剪定できます。これにより、さまざまな戦略を検索し、最も約束のあるものを選択できます。この方向性では、新しい開発はフォレストオブソートフレームワークです。これは、同時に多くの推論「ツリー」を起動し、それら間のコンセンサスとエラーコレクションを使用します。各ツリーは異なるパスを探索できます。約束のないツリーは剪定され、自己修正メカニズムによりモデルは任意のブランチのエラーを検出および修正できます。すべてのツリーからの投票を組み合わせることで、モデルは集団的な決定を下します。
階層性により、調整も可能になります。大きいタスクは、問題の異なる部分を扱うエージェントに分配できます。1つのエージェントはプランニングに焦点を当て、別のエージェントは計算に焦点を当て、別のエージェントは検証に焦点を当てることができます。結果は、1つのまとまりのある解決策に統合できます。マルチエージェント推論の初期の実験は、単一のチェーンメソッドを上回ることが示唆しています。
検証と信頼性
イテレーティブな戦略と階層的な戦略のもう1つの強みは、それらが自然に検証を可能にすることです。Chain-of-Thoughtは推論ステップを公開しますが、それらの正しさを保証することはできません。イテレーティブなループにより、モデルは自身のステップをチェックしたり、他のモデルにチェックしてもらったりできます。階層性により、異なるレベルを個別に検証できます。
これにより、構造化された評価パイプラインが可能になります。たとえば、モデルは下位レベルで候補ソリューションを生成し、上位レベルのコントローラがそれらを選択または改良します。または、外部の検証者が出力を制約に対してテストする前に受け入れます。これらのメカニズムにより、推論はもはや繊細ではなく、より信頼性が高くなります。
検証は、精度だけに限定されません。推論を解釈可能にすることも改善します。推論を層またはイテレーションに組織化することで、研究者は失敗が発生する場所をより簡単に検査できます。これにより、デバッグと整合性がサポートされ、開発者はモデルが推論する方法に対するコントロールが強化されます。
アプリケーション
高度な推論戦略は、すでにさまざまな分野で使用されています。科学では、先端の数学や研究提案の作成における問題解決を支援します。プログラミングでは、モデルは競争的なコーディング、デバッグ、またはフルソフトウェア開発サイクルでよく機能します。
法的およびビジネス分野では、複雑な契約分析や戦略的計画から利益を得ます。エージェントAIシステムは推論とツールの使用を組み合わせ、API、データベース、ウェブをまたいだマルチステップ操作を管理します。教育では、チュートリアルシステムは概念を段階的に説明し、個別の指導を提供できます。
課題と未解決の質問
イテレーティブな方法と階層的な方法の約束にもかかわらず、まだ多くの課題が残っています。1つは効率です。イテレーティブなループとツリーサーチは計算コストが高くなる可能性があります。徹底性と速度のバランスを取ることは未解決の問題です。
別の課題はコントロールです。モデルが役に立たないループに漂うのではなく、役に立つ戦略に従うことを保証することは困難です。研究者は、ヒューリスティック、プランニングアルゴリズム、または学習されたコントローラを使用して推論を導く方法を探究していますが、分野はまだ若いです。
評価も未解決の問題です。従来の精度ベンチマークは結果のみを捉え、推論プロセスの質を捉えません。堅牢性、適応性、透明性の推論戦略を測定するための新しい評価フレームワークが必要です。
最後に、整合性に関する懸念があります。イテレーティブな推論と階層的な推論は、モデルの強みと弱みの両方を増幅させる可能性があります。推論をより信頼性の高いものにすることができますが、オープンエンドのシナリオでモデルがどのように動作するかを予測することもより困難にします。新しいリスクを避けるために、慎重な設計と監督が必要です。
まとめ
Chain-of-ThoughtはAIにおける構造化された推論の扉を開きましたが、その線形の限界は明らかです。将来は、推論をより適応性の高い、検証可能で、スケーラブルにするイテレーティブな戦略と階層的な戦略にあります。推論と改良のサイクルを使用することで、AIは壊れやすいステップバイステップのチェーンから、堅牢でダイナミックな推論システムに移行できます。












