IA 101
Che cos’è il Teorema di Bayes?
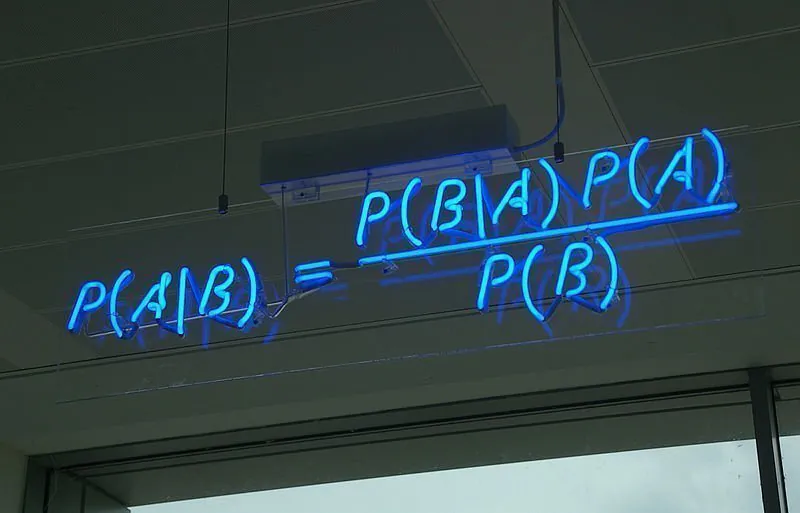
Se hai iniziato a studiare la scienza dei dati o l’apprendimento automatico, c’è una buona probabilità che tu abbia sentito parlare del termine “Teorema di Bayes” in precedenza, o di un “classificatore di Bayes”. Questi concetti possono essere un po’ confusi, soprattutto se non sei abituato a pensare alla probabilità da una prospettiva tradizionale, frequentista. Questo articolo cercherà di spiegare i principi alla base del Teorema di Bayes e di come viene utilizzato nell’apprendimento automatico.
Che cos’è il Teorema di Bayes?
Il Teorema di Bayes è un metodo per calcolare la probabilità condizionale. Il metodo tradizionale per calcolare la probabilità condizionale (la probabilità che un evento si verifichi dato l’occorrenza di un evento diverso) consiste nell’utilizzare la formula della probabilità condizionale, calcolando la probabilità congiunta degli eventi uno e due che si verificano contemporaneamente, e poi dividendo per la probabilità dell’evento due. Tuttavia, la probabilità condizionale può anche essere calcolata in modo leggermente diverso utilizzando il Teorema di Bayes.
Quando si calcola la probabilità condizionale con il teorema di Bayes, si utilizzano i seguenti passaggi:
- Determinare la probabilità che la condizione B sia vera, supponendo che la condizione A sia vera.
- Determinare la probabilità che l’evento A sia vero.
- Moltiplicare le due probabilità insieme.
- Dividere per la probabilità dell’evento B.
Ciò significa che la formula per il Teorema di Bayes potrebbe essere espressa come:
P(A|B) = P(B|A)*P(A) / P(B)
Calcolare la probabilità condizionale in questo modo è particolarmente utile quando la probabilità condizionale inversa può essere facilmente calcolata, o quando il calcolo della probabilità congiunta sarebbe troppo impegnativo.
Esempio del Teorema di Bayes
Potrebbe essere più facile interpretare questo se spendiamo un po’ di tempo esaminando un esempio di come applicare il ragionamento bayesiano e il Teorema di Bayes. Supponiamo di stare giocando a un gioco semplice in cui più partecipanti ti raccontano una storia e devi determinare quale dei partecipanti sta mentendo. Compiliamo l’equazione per il Teorema di Bayes con le variabili in questo scenario ipotetico.
Stiamo cercando di prevedere se ogni individuo nel gioco sta mentendo o dicendo la verità, quindi se ci sono tre giocatori oltre a te, le variabili categoriche possono essere espresse come A1, A2 e A3. La prova delle loro bugie/verità è il loro comportamento. Come quando si gioca a poker, cercheresti certi “segni” che una persona sta mentendo e li useresti come informazioni per informare la tua ipotesi. O se fossi autorizzato a porre loro domande, sarebbe qualsiasi prova che la loro storia non sia coerente. Possiamo rappresentare la prova che una persona sta mentendo come B.
Per essere chiari, stiamo cercando di prevedere la probabilità (A sta mentendo/dice la verità | data la prova del loro comportamento). Per farlo, vorremmo determinare la probabilità di B dato A, o la probabilità che il loro comportamento si verifichi dato che la persona sta mentendo o dicendo la verità. Stai cercando di determinare in quali condizioni il comportamento che stai vedendo avrebbe più senso. Se ci sono tre comportamenti che stai osservando, farebbe il calcolo per ogni comportamento. Ad esempio, P(B1, B2, B3 * A). Farebbe questo per ogni occorrenza di A / per ogni persona nel gioco oltre a te. Questo è questo parte dell’equazione sopra:
P(B1, B2, B3, |A) * P|A
Infine, dividiamo solo per la probabilità di B.
Se ricevessimo prove sui valori reali di questa equazione, ricreeremmo il nostro modello di probabilità, tenendo conto della nuova prova. Questo è chiamato aggiornamento dei priors, poiché aggiorni le tue ipotesi sulla probabilità a priori degli eventi osservati.
Applicazioni di apprendimento automatico per il teorema di Bayes
L’uso più comune del teorema di Bayes nell’apprendimento automatico è nella forma dell’algoritmo Naive Bayes.
Naive Bayes viene utilizzato per la classificazione di set di dati binari e multi-classe, Naive Bayes prende il nome perché i valori assegnati alle prove / attributi – Bs in P(B1, B2, B3 * A) – sono considerati indipendenti l’uno dall’altro. Si suppone che questi attributi non si influenzino a vicenda per semplificare il modello e rendere possibili i calcoli, invece di tentare la complessa operazione di calcolare le relazioni tra ciascuno degli attributi. Nonostante questo modello semplificato, Naive Bayes tende a funzionare abbastanza bene come algoritmo di classificazione, anche quando questa ipotesi probabilmente non è vera (il che accade nella maggior parte dei casi).
Esistono anche varianti comunemente utilizzate del classificatore Naive Bayes, come Multinomial Naive Bayes, Bernoulli Naive Bayes e Gaussian Naive Bayes.
Gli algoritmi Multinomial Naive Bayes vengono spesso utilizzati per classificare i documenti, poiché sono efficaci nell’interpretare la frequenza delle parole all’interno di un documento.
Gli algoritmi Bernoulli Naive Bayes operano in modo simile ai Multinomial Naive Bayes, ma le previsioni rese dall’algoritmo sono booleane. Ciò significa che quando si prevede una classe, i valori saranno binari, sì o no. Nel dominio della classificazione del testo, un algoritmo Bernoulli Naive Bayes assegnerebbe i parametri sì o no in base alla presenza o meno di una parola all’interno del documento di testo.
Se il valore dei predittori / caratteristiche non è discreto ma continuo, Gaussian Naive Bayes può essere utilizzato. Si suppone che i valori delle caratteristiche continue siano stati campionati da una distribuzione gaussiana.












