Intelligenza Artificiale
Il nuovo metodo Deepfake risolve il problema del "Face Host".

Nonostante anni di esagerazioni mediatiche sulla possibilità che le immagini deepfake possano minare la nostra radicata fiducia nell'autenticità dei filmati, tutti i metodi attualmente più diffusi si basano sulla ricerca di "volti ospiti" che siano sostanzialmente simili nella forma al volto di destinazione.
Laddove il filmato originale presenta un volto largo, ma il soggetto di destinazione ha un volto stretto, i risultati sono sempre stati problematici, perché un tale trasferimento comporta il taglio di parte del volto originale e la ricostruzione dello sfondo ora esposto. I pacchetti attuali come DeepFaceLab e FaceSwap sono in grado di produrre risultati limitati quando la configurazione è invertita (stretta>larga), ma non hanno la possibilità di affrontare in modo convincente questo scenario.
Ora, una collaborazione tra Tencent e l'Università cinese di Xiamen ha sviluppato un nuovo approccio, intitolato HifiFace, progettato per colmare questa carenza.

Due deepfake HifiFace, il primo di Anne Hathaway, in cui si ottiene una buona somiglianza nonostante la forma del viso dell'ospite incompatibile. HifiFace si comporta bene anche sugli obiettivi con gli occhiali, tradizionalmente un ostacolo nei deepfake. Fonte: https://arxiv.org/pdf/2106.09965.pdf
Rimodellamento di un volto Deepfake
Approcci precedenti, come quello del 2019 Soggetto Agnostico Scambio di volti e rievocazione storica (FGAN), sono dipesi da Raccordo 3DMM (Modelli Morphable 3D) o altre metodologie basate sul riconoscimento o sulla trasformazione dei punti di riferimento facciali, in cui i lineamenti del volto da "sovrascrivere" determinano in gran parte i limiti dello scambio:

Rilevamento dei punti di riferimento facciali 3DMM. Fonte: https://github.com/Yinghao-Li/3DMM-fitting
Sebbene i metodi concorrenti abbiano attinto a caratteristiche derivate dalle reti di riconoscimento facciale, questi mirano principalmente a ricostituire la consistenza piuttosto che la struttura e, analogamente, producono un effetto "simile a una maschera" nei casi in cui il volto ospite non è del tutto compatibile (ad esempio i limiti e la forma dell'attaccatura dei capelli, della mascella e degli zigomi).
Per affrontare questi problemi, i ricercatori cinesi, con sede nel Media Analytics and Computing Lab del Dipartimento di Intelligenza Artificiale dell'università, hanno sviluppato una rete end-to-end che regredisce i coefficienti del volto target e di quello sorgente utilizzando un modello di ricostruzione 3D, che viene poi ricombinato come informazioni sulla forma e concatenato con informazioni sul vettore di identità provenienti da una rete di riconoscimento facciale.
Questi dati geometrici vengono poi immessi in un modello codificatore-decodificatore come informazioni strutturali, combinandosi con l'espressione e la disposizione del volto target, che vengono sfruttate come fonti ausiliarie per un trasferimento accurato.

Fusione facciale semantica
Inoltre, HifiFace include un componente Semantic Facial Fusion (SFF), che utilizza una funzionalità di basso livello nel codificatore per preservare le informazioni spaziali e sulla trama, senza sacrificare l'identità dell'immagine di destinazione. Le caratteristiche del codificatore e del decodificatore sono integrate in una maschera adattativa appresa e le informazioni di base si fondono nell'output mediante la maschera facciale appresa.

HifiFace in azione. Fonte: https://johann.wang/HifiFace/
In questo modo, HifiFace si discosta dall'uso dei confini della faccia del materiale originale come limite rigido, utilizzando la segmentazione semantica della faccia dilatata, in cui il modello può eseguire una migliore fusione adattiva sui confini del bordo della faccia.
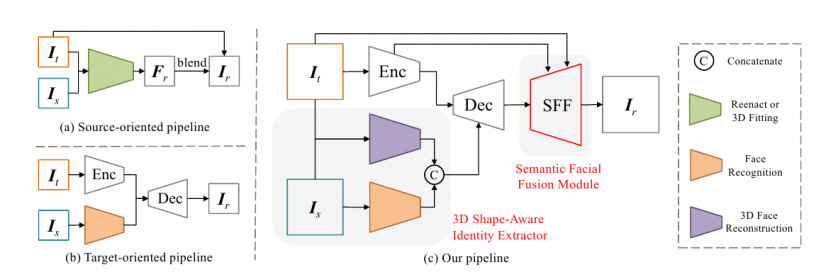
Due approcci precedenti (in alto e in basso a sinistra) e la nuova architettura HifiFace, che consiste in un codificatore, un decodificatore, un estrattore di identità con riconoscimento della forma 3D e un modulo SFF.

In un confronto con i precedenti metodi FSGAN, SimSwap e FaceShifterHifiFace dimostra una ricostruzione superiore della forma del viso, poiché non approssima gli elementi "fantasma" in cui le delimitazioni facciali confondono la mappatura identità>identità, ma li ricostruisce definitivamente.

Collaudo
I ricercatori hanno implementato il sistema utilizzando il VGGFace2 e i set di dati DeepGlint Asian-Celeb. I volti sono stati allineati tramite 5 punti di riferimento esterni e ritagliati nuovamente a 256×256 pixel. È stata utilizzata anche una rete di miglioramento dei ritratti per generare una versione da 512×512 pixel, per un ulteriore modello ad alta risoluzione. Il modello è stato addestrato sotto Adam.

Sebbene FaceShifter mantenga bene l'identità, non può affrontare problemi come espressione, colore e occlusione con la stessa efficacia di HifiFace e ha una struttura di rete più complessa. FSGAN ha problemi nel trasferire l'illuminazione dalla sorgente all'obiettivo.
I ricercatori usano FaceForensics ++ per confronti quantitativi, campionando dieci fotogrammi ciascuno in un batch di video convertiti attraverso i metodi concorrenti e scoprendo che HifiFace ha ottenuto un punteggio di recupero ID superiore. Nel testare una serie di altri fattori, come la qualità dell'immagine, i ricercatori hanno anche scoperto che il loro metodo ha superato le metodologie rivali.

I lineamenti del viso di Benedict Cumberbatch sono riprodotti fedelmente.
Il lavoro rappresenta un ulteriore passo avanti verso l'astrazione del materiale sorgente, in modo che sia solo un modello approssimativo in cui trasferire identità accurate. Alcuni degli attuali pacchetti FOSS, tra cui DeepFaceLab, presentano funzionalità nascenti per la sostituzione completa della testa, ma, come HifiFace, non tengono conto dei capelli e sono più efficaci nel "costruire" un volto piuttosto che nel cesellarlo per adattarlo a una sorgente target desiderata.












