Angolo di Anderson
HunyuanCustom porta video Deepfakes con un’immagine, con audio e sincronizzazione labiale
Questo articolo discute una nuova versione di un modello di video multimodale Hunyuan chiamato ‘HunyuanCustom’. La vastità della copertura del nuovo articolo, combinata con diversi problemi in molti dei video di esempio forniti nella pagina del progetto*, ci costringe a una copertura più generale del solito e a una riproduzione limitata della grande quantità di materiale video che accompagna questo rilascio (poiché molti dei video richiedono una significativa riduzione e elaborazione per migliorare la leggibilità del layout).
Si prega inoltre di notare che l’articolo si riferisce al sistema generativo basato su API Kling come ‘Keling’. Per chiarezza, mi riferisco a ‘Kling’ in tutto.
Tencent sta rilasciando una nuova versione del suo modello di video Hunyuan, intitolato HunyuanCustom. Il nuovo rilascio sembra essere in grado di rendere superflui i modelli Hunyuan LoRA, consentendo all’utente di creare personalizzazioni di video di stile ‘deepfake’ attraverso un’unica immagine:
Fare clic per riprodurre. Prompt: ‘Un uomo sta ascoltando musica e cucinando noodles di lumaca in cucina’. Il nuovo metodo è stato confrontato con metodi sia closed-source che open-source, tra cui Kling, che è un concorrente significativo in questo spazio. Fonte: https://hunyuancustom.github.io/ (avvertenza: sito CPU/memoria-intensivo!)
Nella colonna più a sinistra del video sopra, vediamo l’immagine sorgente singola fornita a HunyuanCustom, seguita dall’interpretazione del prompt del nuovo sistema nella seconda colonna, accanto ad essa. Le colonne restanti mostrano i risultati di vari sistemi proprietari e FOSS: Kling; Vidu; Pika; Hailuo; e il Wan-based SkyReels-A2.
Nel video seguente, vediamo rendering di tre scenari essenziali per questo rilascio: rispettivamente, persona + oggetto; emulazione di un singolo personaggio; e prova virtuale (persona + abiti):
Fare clic per riprodurre. Tre esempi modificati dal materiale del sito di supporto per Hunyuan Video.
Possiamo notare alcune cose da questi esempi, principalmente relative al fatto che il sistema si basa su un’ immagine sorgente singola, invece che su più immagini dello stesso soggetto.
Nel primo clip, l’uomo è essenzialmente sempre rivolto verso la telecamera. Si china in basso e di lato di non più di 20-25 gradi di rotazione, ma, a un’inclinazione superiore a quella, il sistema dovrebbe iniziare a indovinare come apparirebbe di profilo. Questo è difficile, probabilmente impossibile da valutare con precisione da un’unica immagine frontale.
Nel secondo esempio, vediamo che la piccola ragazza è sorridente nel video generato come lo è nell’immagine statica sorgente. Ancora una volta, con questa sola immagine come riferimento, HunyuanCustom dovrebbe fare una stima relativamente non informata su come apparirebbe il suo ‘viso a riposo’. Inoltre, il suo viso non si discosta dalla posizione rivolta alla telecamera di più dell’esempio precedente (‘uomo che mangia patatine’).
Nell’ultimo esempio, vediamo che poiché il materiale sorgente – la donna e gli abiti che indossa – non sono immagini complete, il rendering ha ritagliato la scena per adattarla – che è in realtà una soluzione abbastanza buona a un problema di dati!
Il punto è che sebbene il nuovo sistema possa gestire più immagini (come persona + patatine, o persona + abiti), non sembra consentire più angoli o viste alternative di un singolo personaggio, in modo che possano essere rappresentate espressioni diverse o angoli insoliti. In questo senso, il sistema potrebbe quindi faticare a sostituire l’ecosistema in crescita dei modelli LoRA che sono nati intorno a HunyuanVideo dal suo rilascio lo scorso dicembre, poiché questi possono aiutare HunyuanVideo a produrre personaggi coerenti da qualsiasi angolo e con qualsiasi espressione facciale rappresentata nel set di dati di training (20-60 immagini è tipico).
Collegato al suono
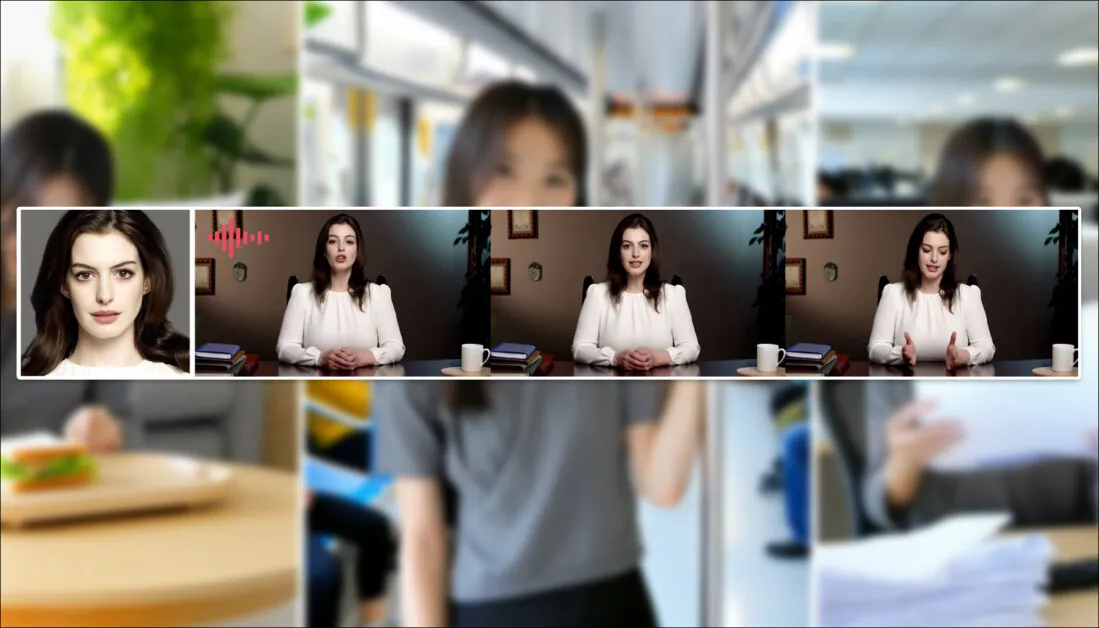
Per l’audio, HunyuanCustom sfrutta il sistema LatentSync (notoriamente difficile per gli appassionati da configurare e ottenere buoni risultati) per ottenere movimenti labiali che corrispondono all’audio e al testo fornito dall’utente:
Caratteristiche audio. Fare clic per riprodurre. Vari esempi di sincronizzazione labiale da HunyuanCustom, modificati insieme.
Al momento della stesura, non ci sono esempi in lingua inglese, ma questi sembrano essere piuttosto buoni – tanto più se il metodo di crearli è facilmente installabile e accessibile.
Modifica di video esistenti
Il nuovo sistema offre risultati apparentemente molto impressionanti per la modifica video-to-video (V2V, o Vid2Vid), in cui un segmento di un video esistente (reale) viene mascherato e sostituito in modo intelligente da un soggetto fornito in un’unica immagine di riferimento. Ecco un esempio dal materiale supplementare del sito:
Fare clic per riprodurre. Solo l’oggetto centrale è stato preso di mira, ma ciò che rimane intorno ad esso viene anche alterato in un passaggio vid2vid di HunyuanCustom.
Come possiamo vedere, e come è standard in uno scenario vid2vid, l’ intero video viene alterato in qualche misura dal processo, anche se la maggior parte alterata nella regione target, ovvero il giocattolo di peluche. Presumibilmente, potrebbero essere sviluppati pipeline per creare tali trasformazioni sotto un approccio garbage matte che lascia la maggior parte del contenuto video identico all’originale. Questo è ciò che fa Adobe Firefly sotto il cofano e lo fa abbastanza bene – ma è un processo poco studiato nella scena generativa FOSS.
Tuttavia, la maggior parte degli esempi alternativi forniti fa un lavoro migliore nell’integrare questi contenuti, come possiamo vedere nella compilazione assemblata di seguito:
Fare clic per riprodurre. Diversi esempi di contenuti interiettivi utilizzando vid2vid in HunyuanCustom, mostrando un notevole rispetto per il materiale non target.
Un nuovo inizio?
Questa iniziativa è uno sviluppo del progetto Hunyuan Video, non un cambio di direzione netto da quel flusso di sviluppo. I miglioramenti del progetto sono introdotti come inserzioni architettoniche discrete piuttosto che cambiamenti strutturali radicali, con l’obiettivo di consentire al modello di mantenere la fedeltà dell’identità tra i frame senza affidarsi alla regolazione fine soggetto-specifica, come con gli approcci LoRA o inversione testuale.
Per essere chiari, quindi, HunyuanCustom non è stato addestrato da zero, ma piuttosto è una regolazione fine del modello di base HunyuanVideo di dicembre 2024.
Coloro che hanno sviluppato HunyuanVideo LoRAs potrebbero chiedersi se funzioneranno ancora con questa nuova edizione, o se dovranno reinventare la ruota LoRA ancora una volta se desiderano maggiori capacità di personalizzazione rispetto a quelle costruite in questo nuovo rilascio.
In generale, un rilascio fortemente regolato di un modello iperscalabile altera i pesi del modello abbastanza da rendere difficile che i LoRAs creati per il modello precedente funzionino correttamente, o affatto, con il modello raffinato di recente.
A volte, tuttavia, la popolarità di una regolazione può sfidare le sue origini: un esempio di una regolazione che diventa un fork efficace, con un ecosistema dedicato e seguaci propri, è la regolazione Pony Diffusion di Stable Diffusion XL (SDXL). Pony attualmente ha 592.000+ download nel dominio in costante evoluzione CivitAI, con una vasta gamma di LoRAs che hanno utilizzato Pony (e non SDXL) come modello di base, e che richiedono Pony al momento dell’inferenza.
Rilascio
La pagina del progetto per il nuovo articolo (che è intitolato HunyuanCustom: un’architettura multimodale guidata per la generazione di video personalizzati) presenta collegamenti a un sito GitHub che, mentre scrivo, è appena diventato funzionale e sembra contenere tutto il codice e i pesi necessari per l’implementazione locale, insieme a una timeline proposta (dove l’unica cosa importante ancora da venire è l’integrazione di ComfyUI).
Al momento della stesura, la presenza del progetto su Hugging Face è ancora un 404. Tuttavia, c’è una versione basata su API in cui si può apparentemente dimostrare il sistema, a condizione di poter fornire un codice di scansione WeChat.
Ho raramente visto un utilizzo così elaborato e diffuso di una tale varietà di progetti in un’unica assemblea, come è evidente in HunyuanCustom – e presumibilmente alcune delle licenze obbligherebbero comunque a un rilascio completo.
Due modelli sono annunciati nella pagina GitHub: una versione da 720px1280px che richiede 8)GB di memoria GPU Peak, e una versione da 512px896px che richiede 60GB di memoria GPU Peak.
Il repository afferma ‘La memoria GPU minima richiesta è di 24GB per 720px1280px129f ma molto lenta… Consigliamo l’uso di una GPU con 80GB di memoria per una migliore qualità di generazione’ – e ribadisce che il sistema è stato testato finora solo su Linux.
Il modello Hunyuan Video precedente è stato, dal rilascio ufficiale, quantizzato verso dimensioni in cui può essere eseguito con meno di 24GB di VRAM, e sembra ragionevole supporre che il nuovo modello sarà altrettanto adattato in forme più amichevoli per i consumatori dalla comunità e che sarà rapidamente adattato per l’uso su sistemi Windows.
A causa di limiti di tempo e della grande quantità di informazioni che accompagnano questo rilascio, possiamo solo dare uno sguardo più ampio, piuttosto che approfondito, a questo rilascio. Tuttavia, proviamo a dare un’occhiata più da vicino a HunyuanCustom.
Uno sguardo al documento
La pipeline di dati per HunyuanCustom, apparentemente conforme al quadro GDPR, incorpora sia dataset video sintetici che open-source, tra cui OpenHumanVid, con otto categorie core rappresentate: umani, animali, piante, paesaggi, veicoli, oggetti, architettura, e anime.

Dal documento di rilascio, una panoramica dei diversi pacchetti che contribuiscono alla pipeline di costruzione dei dati di HunyuanCustom. Fonte: https://arxiv.org/pdf/2505.04512
La filtrazione iniziale inizia con PySceneDetect, che segmenta i video in clip a un singolo shot. TextBPN-Plus-Plus viene quindi utilizzato per rimuovere i video che contengono testo eccessivo su schermo, sottotitoli, filigrane o loghi.
Per affrontare le incoerenze nella risoluzione e nella durata, i clip vengono standardizzati a cinque secondi di lunghezza e ridimensionati a 512 o 720 pixel sul lato corto. La filtrazione estetica è gestita utilizzando Koala-36M, con una soglia personalizzata di 0,06 applicata per il set di dati personalizzato curato dai ricercatori del nuovo articolo.
Il processo di estrazione del soggetto combina il modello di linguaggio Qwen7B, il framework di riconoscimento di oggetti YOLO11X e l’architettura InsightFace popolare, per identificare e convalidare le identità umane.
Per i soggetti non umani, QwenVL e Grounded SAM 2 vengono utilizzati per estrarre le caselle di delimitazione rilevanti, che vengono scartate se troppo piccole.

Esempi di segmentazione semantica con Grounded SAM 2, utilizzato nel progetto Hunyuan Control. Fonte: https://github.com/IDEA-Research/Grounded-SAM-2
L’estrazione di più soggetti utilizza Florence2 per l’annotazione delle caselle di delimitazione e Grounded SAM 2 per la segmentazione, seguiti da clustering e segmentazione temporale dei frame di training.
I clip elaborati vengono ulteriormente arricchiti tramite annotazione, utilizzando un sistema di etichettatura strutturata proprietario sviluppato dal team Hunyuan, che fornisce metadati stratificati come descrizioni e suggerimenti di movimento della telecamera.
Strategie di aumento di maschera, tra cui la conversione in caselle di delimitazione, sono state applicate durante l’addestramento per ridurre l’overfitting e assicurarsi che il modello si adatti a forme di oggetto diverse.
I dati audio sono stati sincronizzati utilizzando il già menzionato LatentSync e i clip sono stati scartati se i punteggi di sincronizzazione scendevano al di sotto di una soglia minima.
Il framework di valutazione della qualità delle immagini cieche HyperIQA è stato utilizzato per escludere i video con punteggi inferiori a 40 (nella scala personalizzata di HyperIQA). Le tracce audio valide sono state quindi elaborate con Whisper per estrarre le caratteristiche per le attività a valle.
Gli autori incorporano il modello di assistente linguistico LLaVA durante la fase di annotazione e sottolineano la posizione centrale che questo framework ha in HunyuanCustom. LLaVA viene utilizzato per generare didascalie delle immagini e aiutare nell’allineamento del contenuto visivo con i prompt di testo, supportando la costruzione di un segnale di allenamento coerente tra modalità:

Il framework HunyuanCustom supporta la generazione di video coerenti con l’identità condizionata su testo, immagine, audio e input video.
Sfruttando le capacità di allineamento visione-linguaggio di LLaVA, la pipeline guadagna un ulteriore livello di coerenza semantica tra elementi visivi e relative descrizioni testuali – particolarmente prezioso in scenari multi-soggetto o complessi.
Video personalizzato
Per consentire la generazione di video in base a un’immagine di riferimento e a un prompt, sono stati creati due moduli centrati su LLaVA, adattando prima la struttura di input di HunyuanVideo in modo che potesse accettare un’immagine insieme al testo.
Ciò ha comportato la formattazione del prompt in un modo che incorpora l’immagine direttamente o la etichetta con una breve descrizione di identità. Un token di separazione è stato utilizzato per evitare che l’incorporamento dell’immagine sopraffaccia il contenuto del prompt.
Poiché l’encoder visivo di LLaVA tende a comprimere o scartare dettagli spaziali fine-granulari durante l’allineamento delle caratteristiche dell’immagine e del testo (in particolare quando si traduce un’unica immagine di riferimento in un’impronta semantica generale), è stato incorporato un modulo di miglioramento dell’identità. Poiché quasi tutti i modelli di diffusione di video latente hanno difficoltà a mantenere un’identità senza un LoRA, anche in un clip di cinque secondi, le prestazioni di questo modulo nella prova della comunità potrebbero rivelarsi significative.
In ogni caso, l’immagine di riferimento viene quindi ridimensionata e codificata utilizzando il 3D-VAE causale dell’originale modello HunyuanVideo e il suo latente viene inserito nel video latente lungo l’asse temporale, con un offset spaziale applicato per evitare che l’immagine venga riprodotta direttamente nel output, mentre ancora guida la generazione.
Il modello è stato addestrato utilizzando Flow Matching, con campioni di rumore tratti da una distribuzione logit-normale – e la rete è stata addestrata per recuperare il video corretto da questi latenti rumorosi. LLaVA e il generatore di video sono stati entrambi regolati insieme in modo che l’immagine e il prompt potessero guidare l’output in modo più fluido e mantenere la coerenza dell’identità del soggetto.
Per i prompt multi-soggetto, ogni coppia immagine-testo è stata incorporata separatamente e assegnata a una posizione temporale distinta, consentendo di distinguere le identità e supportando la generazione di scene che coinvolgono più soggetti interagenti.
Suono e visione
HunyuanCustom condiziona la generazione di audio/discorso utilizzando sia l’audio di input dell’utente che un prompt di testo, consentendo ai personaggi di parlare all’interno di scene che riflettono l’ambientazione descritta.
Per supportare ciò, un modulo AudioNet a identità disaccoppiata introduce le caratteristiche audio senza disturbare i segnali di identità incorporati dall’immagine di riferimento e dal prompt. Queste caratteristiche sono allineate con la timeline video compressa, divise in segmenti a livello di frame e iniettate utilizzando un meccanismo di cross-attenzione spaziale che mantiene ogni frame isolato, preservando la coerenza del soggetto e evitando interferenze temporali.
Un secondo modulo di iniezione temporale fornisce un controllo più fine sulla temporizzazione e sul movimento, lavorando in tandem con AudioNet, mappando le caratteristiche audio in regioni specifiche della sequenza latente e utilizzando un Multi-Layer Perceptron (MLP) per convertirle in offset di movimento token-wise. Ciò consente ai gesti e ai movimenti facciali di seguire il ritmo e l’enfasi dell’input parlato con maggiore precisione.
HunyuanCustom consente di modificare direttamente i soggetti in video esistenti, sostituendo o inserendo persone o oggetti in una scena senza dover ricostruire l’intero clip da zero. Ciò lo rende utile per attività che coinvolgono la modifica dell’aspetto o del movimento in modo mirato.
Fare clic per riprodurre. Un ulteriore esempio dal sito di supporto.
Per facilitare la sostituzione efficiente dei soggetti in video esistenti, il nuovo sistema evita l’approccio risorsivo-intensivo dei metodi recenti come il popolare VACE, o quelli che fondono intere sequenze video insieme, favorendo invece la compressione di un video di riferimento utilizzando il 3D-VAE pre-addestrato – allineandolo con i latenti video della pipeline di generazione e aggiungendoli insieme. Ciò mantiene il processo relativamente leggero, mentre consente ancora ai contenuti video esterni di guidare l’output.
Una piccola rete neurale gestisce l’allineamento tra il video di input pulito e i latenti rumorosi utilizzati nella generazione. Il sistema testa due modi di iniettare queste informazioni: fondendo i due set di caratteristiche prima di comprimerle di nuovo; e aggiungendo le caratteristiche frame per frame. Il secondo metodo funziona meglio, gli autori hanno trovato, ed evita la perdita di qualità mentre mantiene invariato il carico computazionale.
Dati e test
Nei test, le metriche utilizzate sono state: il modulo di coerenza dell’identità in ArcFace, che estrae le impronte facciali dall’immagine di riferimento e da ogni frame del video generato, e poi calcola la somiglianza media dei coseni tra loro; somiglianza del soggetto, tramite l’invio di segmenti YOLO11x a Dino 2 per il confronto; CLIP-B, allineamento testo-video, che misura la somiglianza tra il prompt e il video generato; CLIP-B ancora, per calcolare la somiglianza tra ogni frame e sia i frame adiacenti che il primo frame, nonché la coerenza temporale; e grado dinamico, come definito da VBench.
Come indicato in precedenza, i concorrenti di base closed source erano Hailuo; Vidu 2.0; Kling (1.6); e Pika. I framework FOSS concorrenti erano VACE e SkyReels-A2.

Valutazione delle prestazioni del modello che confronta HunyuanCustom con i principali metodi di personalizzazione video in termini di coerenza dell’identità (Face-Sim), somiglianza del soggetto (DINO-Sim), allineamento testo-video (CLIP-B-T), coerenza temporale (Temp-Consis) e intensità del movimento (DD). I risultati ottimali e sub-ottimali sono mostrati in grassetto e sottolineato, rispettivamente.
Di questi risultati, gli autori affermano:
‘Il nostro [HunyuanCustom] raggiunge la migliore coerenza dell’identità e la migliore coerenza del soggetto. Raggiunge anche risultati paragonabili nel seguire il prompt e nella coerenza temporale. [Hailuo] ha il miglior punteggio CLIP perché può seguire le istruzioni del testo molto bene con solo la coerenza dell’identità, sacrificando la coerenza dei soggetti non umani (il peggiore DINO-Sim). In termini di Dynamic-degree, [Vidu] e [VACE] si esibiscono male, il che potrebbe essere dovuto alle dimensioni ridotte del modello.’
Sebbene il sito del progetto sia saturo di video di confronto (la cui disposizione sembra essere stata progettata per l’estetica del sito Web piuttosto che per una facile comparazione), attualmente non presenta un video equivalente ai risultati statici stipati insieme nel PDF, per quanto riguarda i test qualitativi iniziali. Tuttavia, vi incoraggio a esaminare attentamente i video nel sito del progetto, poiché offrono una migliore impressione degli esiti:

Dal documento, un confronto sulla personalizzazione video centrata sugli oggetti. Sebbene il lettore debba (come sempre) fare riferimento al PDF di origine per una migliore risoluzione, i video nel sito del progetto potrebbero essere una risorsa più illuminante in questo caso.
Gli autori commentano qui:
‘Si può vedere che [Vidu], [Skyreels A2] e il nostro metodo raggiungono risultati relativamente buoni nell’allineamento del prompt e nella coerenza del soggetto, ma la nostra qualità video è migliore di Vidu e Skyreels, grazie alle buone prestazioni di generazione video del nostro modello di base, ovvero [Hunyuanvideo-13B].
‘Tra i prodotti commerciali, sebbene [Kling] abbia una buona qualità video, il primo frame del video ha un problema di copia-incolla, e a volte il soggetto si muove troppo velocemente e [sbiadisce], portando a una cattiva esperienza di visualizzazione.’
Gli autori affermano inoltre che Pika si esibisce male in termini di coerenza temporale, introducendo artefatti di sottotitoli (effetti di cattiva cura dei dati, in cui elementi di testo nei clip video sono stati consentiti di inquinare i concetti fondamentali).
Hailuo mantiene l’identità facciale, affermano, ma non riesce a preservare la coerenza del corpo intero. Tra i metodi open-source, VACE, i ricercatori affermano, non riesce a mantenere la coerenza dell’identità, mentre sostengono che HunyuanCustom produce video con una forte preservazione dell’identità, mantenendo la qualità e la diversità.
Successivamente, sono stati condotti test per la personalizzazione video multi-soggetto, contro gli stessi concorrenti. Come nell’esempio precedente, i risultati del PDF appiattiti non sono equivalenti dei video disponibili nel sito del progetto, ma sono unici tra i risultati presentati:

Confronti utilizzando personalizzazioni video multi-soggetto. Si prega di fare riferimento al PDF per una migliore dettaglio e risoluzione.
Il documento afferma:
‘[Pika] può generare i soggetti specificati ma mostra instabilità nei frame video, con istanze di un uomo che scompare in una scena e una donna che non riesce ad aprire una porta come richiesto. [Vidu] e [VACE] catturano parzialmente l’identità umana ma perdono dettagli significativi di oggetti non umani, indicando una limitazione nella rappresentazione di soggetti non umani.
‘[SkyReels A2] sperimenta una grave instabilità dei frame, con cambiamenti notevoli nelle patatine e numerosi artefatti nella scena di destra.
‘In contrasto, il nostro HunyuanCustom cattura efficacemente sia le identità umane che quelle non umane, genera video che aderiscono ai prompt dati e mantiene un’elevata qualità visiva e stabilità.’
Un ulteriore esperimento è stato ‘pubblicità umana virtuale’, in cui i framework sono stati impegnati a integrare un prodotto con una persona:

Dall’round di test qualitativi, esempi di ‘posizionamento di prodotto’ neurale. Si prega di fare riferimento al PDF per una migliore dettaglio e risoluzione.
Per questo round, gli autori affermano:
‘I risultati dimostrano che HunyuanCustom mantiene efficacemente l’identità umana mentre preserva i dettagli del prodotto bersaglio, inclusi il testo su di esso.
‘Inoltre, l’interazione tra l’umano e il prodotto appare naturale e il video aderisce strettamente al prompt dato, evidenziando il notevole potenziale di HunyuanCustom nella generazione di video pubblicitari.’
Un’area in cui i risultati video sarebbero stati molto utili è stata la prova qualitativa per la personalizzazione del soggetto guidata dall’audio, in cui il personaggio parla l’audio corrispondente da una scena e una postura descritte nel testo.

Risultati parziali per il round audio – sebbene i risultati video potrebbero essere stati preferibili in questo caso. Solo la metà superiore della figura del PDF è riprodotta qui, poiché è grande e difficile da accomodare in questo articolo. Si prega di fare riferimento al PDF di origine per una migliore dettaglio e risoluzione.
Gli autori affermano:
‘I metodi di animazione umana guidata dall’audio precedenti immettono un’immagine umana e un audio, dove la postura, l’abbigliamento e l’ambiente dell’umano rimangono coerenti con l’immagine data e non possono generare video in altre pose e ambienti, il che potrebbe [limitare] la loro applicazione.
‘…[Il nostro] HunyuanCustom consente la personalizzazione umana guidata dall’audio, in cui il personaggio parla l’audio corrispondente in una scena e postura descritte nel testo, consentendo una personalizzazione umana guidata dall’audio più flessibile e controllabile.’
Ulteriori test (si prega di fare riferimento al PDF per tutti i dettagli) hanno incluso un round che ha opposto il nuovo sistema a VACE e Kling 1.6 per la sostituzione del soggetto nel video:

Test della sostituzione del soggetto nel video in modalità video-to-video. Si prega di fare riferimento al PDF di origine per una migliore dettaglio e risoluzione.
Di questi, gli ultimi test presentati nel nuovo documento, i ricercatori opinano:
‘VACE soffre di artefatti di bordo a causa dell’aderenza rigorosa alle maschere di input, risultando in forme di soggetto innaturali e continuità del movimento interrotta. [Kling], al contrario, esibisce un effetto di copia-incolla, in cui i soggetti vengono sovrapposti direttamente al video, portando a una cattiva integrazione con lo sfondo.
‘In confronto, HunyuanCustom evita efficacemente gli artefatti di bordo, raggiunge un’integrazione senza soluzione di continuità con lo sfondo del video e mantiene una forte preservazione dell’identità – dimostrando la sua prestazione superiore nelle attività di editing video.’
Conclusione
Questo è un rilascio affascinante, non da ultimo perché affronta qualcosa che la scena degli appassionati sempre insoddisfatta ha lamentato di più ultimamente – la mancanza di sincronizzazione labiale, in modo che il realismo aumentato possibile in sistemi come Hunyuan Video e Wan 2.1 potesse essere dato una nuova dimensione di autenticità.
Sebbene la disposizione della maggior parte degli esempi di video comparativi nel sito del progetto renda piuttosto difficile confrontare le capacità di HunyuanCustom con i concorrenti precedenti, è da notare che pochi progetti nello spazio della sintesi video hanno il coraggio di opporsi in test a Kling, l’API di diffusione video commerciale che è sempre in cima o vicino alla cima delle classifiche; Tencent sembra aver fatto progressi contro questo incumbent in modo abbastanza impressionante.
* Il problema è che alcuni dei video sono così ampi, corti e ad alta risoluzione che non si riproducono in lettori video standard come VLC o Windows Media Player, mostrando schermi neri.
Pubblicato per la prima volta giovedì 8 maggio 2025












