Intelligenza Artificiale
Come la diffusione stabile potrebbe svilupparsi come prodotto di consumo mainstream

Ironia della sorte, Diffusione stabilen, il nuovo framework di sintesi delle immagini basato sull'intelligenza artificiale che ha conquistato il mondo, non è né stabile né così "diffuso", almeno non ancora.
L'intera gamma di funzionalità del sistema è distribuita su un variegato assortimento di offerte in continua evoluzione, provenienti da una manciata di sviluppatori che si scambiano freneticamente le ultime informazioni e teorie in diversi colloqui su Discord; inoltre, la stragrande maggioranza delle procedure di installazione per i pacchetti che creano o modificano sono ben lontane dall'essere "plug and play".
Piuttosto, tendono a richiedere la riga di comando o Guidato da BAT installazione tramite GIT, Conda, Python, Miniconda e altri framework di sviluppo all'avanguardia - pacchetti software così rari tra la corsa generale dei consumatori che la loro installazione è spesso segnalato dai fornitori di antivirus e antimalware come prova di un sistema host compromesso.

Solo una piccola selezione di fasi del percorso attualmente richiesto dall'installazione standard di Stable Diffusion. Molte distribuzioni richiedono anche versioni specifiche di Python, che potrebbero entrare in conflitto con le versioni esistenti installate sul computer dell'utente, sebbene questo problema possa essere risolto con installazioni basate su Docker e, in una certa misura, tramite l'utilizzo di ambienti Conda.
I thread di messaggi nelle comunità SFW e NSFW Stable Diffusion sono inondati di suggerimenti e trucchi relativi all'hacking di script Python e installazioni standard, al fine di abilitare funzionalità migliorate o risolvere frequenti errori di dipendenza e una serie di altri problemi.
Questo lascia il consumatore medio, interessato creando immagini straordinarie dai prompt di testo, praticamente in balia del numero crescente di interfacce Web API monetizzate, la maggior parte delle quali offre un numero minimo di generazioni di immagini gratuite prima di richiedere l'acquisto di token.
Inoltre, quasi tutte queste offerte basate sul web rifiutano di pubblicare contenuti NSFW (molti dei quali potrebbero riguardare argomenti non pornografici di interesse generale, come la "guerra"), il che distingue Stable Diffusion dai servizi epurati di DALL-E 2 di OpenAI.
'Photoshop per una diffusione stabile'
Stuzzicato dalle immagini favolose, piccanti o ultraterrene che popolano quotidianamente l'hashtag #stablediffusion di Twitter, ciò che il mondo intero sta probabilmente aspettando è 'Photoshop per una diffusione stabile' – un'applicazione installabile multipiattaforma che integra le funzionalità migliori e più potenti dell'architettura di Stability.ai, nonché le varie ingegnose innovazioni della nascente comunità di sviluppo SD, senza finestre CLI mobili, routine di installazione e aggiornamento oscure e in continua evoluzione o funzionalità mancanti.
Quello che abbiamo attualmente, nella maggior parte delle installazioni più capaci, è una pagina web variamente elegante a cavallo di una finestra della riga di comando disincarnata e il cui URL è una porta localhost:

Similmente alle app di sintesi basate su CLI come FaceSwap e DeepFaceLab incentrato su BAT, l'installazione "prepack" di Stable Diffusion mostra le sue radici da riga di comando, con l'interfaccia accessibile tramite una porta localhost (vedere la parte superiore dell'immagine sopra) che comunica con la funzionalità Stable Diffusion basata su CLI.
Senza dubbio, sta arrivando un'applicazione più snella. Esistono già diverse applicazioni integrali basate su Patreon che possono essere scaricate, come ad esempio GR Rischio e NMKD (vedi immagine sotto) - ma nessuno che, finora, integri l'intera gamma di funzionalità che alcune delle implementazioni più avanzate e meno accessibili di Stable Diffusion possono offrire.

Primi pacchetti di Stable Diffusion basati su Patreon, leggermente "app-izzati". Quello di NMKD è il primo a integrare l'output della CLI direttamente nella GUI.
Diamo un'occhiata a come potrebbe apparire un'implementazione più completa e completa di questa straordinaria meraviglia open source e quali sfide potrebbe dover affrontare.
Considerazioni legali per un'applicazione di diffusione stabile commerciale interamente finanziata
Il fattore NSFW
Il codice sorgente di Stable Diffusion è stato rilasciato con estensione licenza estremamente permissiva che non proibisce reimplementazioni commerciali e opere derivate che si basano ampiamente sul codice sorgente.
Oltre al summenzionato e crescente numero di build Stable Diffusion basate su Patreon, nonché all'ampio numero di plug-in applicativi sviluppati per Figma, Krita, Photoshop, GIMPe Frullatore (tra gli altri), non c'è pratico motivo per cui una casa di sviluppo software ben finanziata non potrebbe sviluppare un'applicazione Stable Diffusion molto più sofisticata e capace. Dal punto di vista del mercato, ci sono tutte le ragioni per ritenere che molte di queste iniziative siano già ben avviate.
Qui, tali sforzi si trovano immediatamente di fronte al dilemma se, come la maggior parte delle API Web per Stable Diffusion, l'applicazione consentirà o meno il filtro NSFW nativo di Stable Diffusion (un frammento di codice), da disattivare.
"Seppellire" il passaggio al NSFW
Sebbene la licenza open source di Stability.ai per Stable Diffusion includa un elenco ampiamente interpretabile di applicazioni per le quali potrebbe non è un essere utilizzato (probabilmente includendo contenuto pornografico e deepfakes), l'unico modo in cui un fornitore potrebbe effettivamente vietare tale uso sarebbe compilare il filtro NSFW in un eseguibile opaco invece di un parametro in un file Python, oppure imporre un confronto di checksum sul file Python o DLL che contiene la direttiva NSFW, in modo che i rendering non possano verificarsi se gli utenti modificano questa impostazione.
Ciò lascerebbe la presunta applicazione "neutrale" più o meno nello stesso modo in cui DALL-E 2 attualmente lo è, riducendone l'attrattiva commerciale. Inoltre, inevitabilmente, nella comunità torrent/hacking emergerebbero versioni decompilate e "manipolate" di questi componenti (sia elementi runtime Python originali che file DLL compilati, come quelli ora utilizzati nella linea Topaz di strumenti di intelligenza artificiale per il miglioramento delle immagini) per sbloccare tali restrizioni, semplicemente sostituendo gli elementi ostruenti e annullando qualsiasi requisito di checksum.
Alla fine, il fornitore potrebbe semplicemente scegliere di ripetere l'avvertimento di Stability.ai contro l'uso improprio che caratterizza la prima esecuzione di molte attuali distribuzioni Stable Diffusion.
Tuttavia, i piccoli sviluppatori open source che attualmente utilizzano dichiarazioni di non responsabilità casuali in questo modo hanno poco da perdere rispetto a una società di software che ha investito notevoli quantità di tempo e denaro per rendere Stable Diffusion completo e accessibile, il che invita a una considerazione più approfondita.
Responsabilità di falsi falsi
Come abbiamo recentemente notato, il database LAION-aesthetics, parte dei 4.2 miliardi di immagini su cui sono stati formati i modelli in corso di Stable Diffusion, contiene un gran numero di immagini di celebrità, consentendo agli utenti di creare in modo efficace deepfake, tra cui deepfake pornografici di celebrità.

Dal nostro recente articolo, quattro fasi di Jennifer Connelly in quattro decenni della sua carriera, dedotte da Stable Diffusion.
Si tratta di una questione distinta e più controversa rispetto alla generazione di materiale pornografico "astratto" (solitamente) legale, che non raffigura persone "reali" (sebbene tali immagini siano dedotte da numerose foto reali presenti nel materiale di formazione).
Poiché un numero sempre maggiore di stati e paesi degli Stati Uniti sta sviluppando o ha istituito leggi contro la pornografia deepfake, la capacità di Stable Diffusion di creare materiale pornografico sulle celebrità potrebbe significare che un'applicazione commerciale non completamente censurata (ovvero in grado di creare materiale pornografico) potrebbe comunque aver bisogno di una certa capacità di filtrare i volti delle celebrità percepite.
Un metodo potrebbe essere quello di fornire una "lista nera" integrata di termini che non saranno accettati in un prompt utente, relativi a nomi di celebrità e a personaggi fittizi a cui potrebbero essere associati. Presumibilmente tali impostazioni dovrebbero essere istituite in più lingue oltre all'inglese, poiché i dati di origine includono anche altre lingue. Un altro approccio potrebbe essere quello di incorporare sistemi di riconoscimento delle celebrità come quelli sviluppati da Clarifai.
Potrebbe essere necessario che i produttori di software incorporino tali metodi, forse inizialmente disattivati, in quanto potrebbero aiutare a impedire a un'applicazione Stable Diffusion autonoma a tutti gli effetti di generare volti di celebrità, in attesa di una nuova legislazione che potrebbe rendere illegale tale funzionalità.
Ancora una volta, però, tale funzionalità potrebbe inevitabilmente essere decompilata e ribaltata dagli interessati; tuttavia, il produttore del software potrebbe, in tale eventualità, affermare che si tratta effettivamente di vandalismo non autorizzato, a condizione che questo tipo di ingegneria inversa non sia reso eccessivamente facile.
Funzionalità che potrebbero essere incluse
La funzionalità di base in qualsiasi distribuzione di Stable Diffusion ci si aspetterebbe da qualsiasi applicazione commerciale ben finanziata. Questi includono la possibilità di utilizzare prompt di testo per generare immagini appropriate (da testo a immagine); la capacità di utilizzare schizzi o altre immagini come linee guida per le nuove immagini generate (da immagine a immagine); i mezzi per regolare quanto "immaginativo" il sistema è istruito a essere; un modo per bilanciare il tempo di rendering con la qualità; e altre "basi", come l'archiviazione automatica opzionale di immagini/prompt e l'upscaling opzionale di routine tramite RealESRGAN, e almeno un 'fissaggio del viso' di base con GFPGAN or CodeFormer.
Si tratta di un'installazione piuttosto "vanilla". Diamo un'occhiata ad alcune delle funzionalità più avanzate attualmente in fase di sviluppo o ampliamento, che potrebbero essere incorporate in un'applicazione Stable Diffusion "tradizionale" a tutti gli effetti.
Congelamento stocastico
Anche se tu riutilizzare un seme da un precedente rendering di successo, è terribilmente difficile ottenere Stable Diffusion per ripetere accuratamente una trasformazione se qualsiasi parte del prompt o l'immagine di origine (o entrambi) viene modificata per un rendering successivo.
Questo è un problema se si desidera utilizzare Eb Synth per imporre le trasformazioni di Stable Diffusion su video reali in modo temporalmente coerente, sebbene la tecnica possa essere molto efficace per semplici riprese di testa e spalle:

Il movimento limitato può rendere EbSynth un mezzo efficace per trasformare le trasformazioni Stable Diffusion in video realistici. Fonte: https://streamable.com/u0pgzd
EbSynth funziona estrapolando una piccola selezione di fotogrammi chiave "modificati" in un video che è stato elaborato in una serie di file immagine (e che può essere successivamente riassemblato in un video).

In questo esempio dal sito EbSynth, una piccola manciata di fotogrammi di un video sono stati dipinti in modo artistico. EbSynth utilizza questi fotogrammi come guide di stile per alterare in modo simile l'intero video in modo che corrisponda allo stile dipinto. Fonte: https://www.youtube.com/embed/eghGQtQhY38
Nell'esempio seguente, in cui non si nota quasi nessun movimento da parte della (vera) istruttrice di yoga bionda sulla sinistra, Stable Diffusion ha ancora difficoltà a mantenere un volto coerente, perché le tre immagini trasformate come "fotogrammi chiave" non sono completamente identiche, anche se condividono tutte lo stesso seed numerico.

Qui, anche con lo stesso prompt e seme in tutte e tre le trasformazioni e pochissimi cambiamenti tra i fotogrammi sorgente, i muscoli del corpo variano in dimensioni e forma, ma soprattutto il volto è incoerente, ostacolando la coerenza temporale in un potenziale rendering EbSynth.
Sebbene il video SD/EbSynth qui sotto sia molto creativo, in cui le dita dell'utente sono state trasformate (rispettivamente) in un paio di gambe di pantaloni che camminano e in un'anatra, l'incoerenza dei pantaloni è tipica del problema che Stable Diffusion ha nel mantenere la coerenza tra diversi fotogrammi chiave, anche quando i fotogrammi sorgente sono simili tra loro e il seed è coerente.

Le dita di un uomo diventano un uomo che cammina e un'anatra, tramite Stable Diffusion ed EbSynth. Fonte: https://old.reddit.com/r/StableDiffusion/comments/x92itm/proof_of_concept_using_img2img_ebsynth_to_animate/
L'utente che ha creato questo video ha commentato che la trasformazione della papera, probabilmente la più efficace delle due, anche se meno sorprendente e originale, richiedeva solo un singolo fotogramma chiave trasformato, mentre era necessario renderizzare 50 immagini Stable Diffusion per creare i pantaloni da passeggio, che mostrano più incoerenza. L'utente ha anche notato che sono stati necessari cinque tentativi per ottenere la coerenza per ciascuno dei 50 fotogrammi chiave.
Pertanto sarebbe un grande vantaggio per un'applicazione Stable Diffusion veramente completa fornire funzionalità che preservino le caratteristiche nella massima misura possibile attraverso i fotogrammi chiave.
Una possibilità è che l'applicazione consenta all'utente di "congelare" la codifica stocastica per la trasformazione su ogni frame, cosa che attualmente può essere ottenuta solo modificando manualmente il codice sorgente. Come mostra l'esempio seguente, questo favorisce la coerenza temporale, anche se certamente non la risolve:

Un utente di Reddit ha trasformato le riprese della webcam di se stesso in diversi personaggi famosi non solo persistendo il seme (cosa che qualsiasi implementazione di Stable Diffusion può fare), ma assicurandosi che il parametro stochastic_encode() fosse identico in ogni trasformazione. Ciò è stato ottenuto modificando il codice, ma potrebbe facilmente diventare uno switch accessibile all'utente. Chiaramente, però, non risolve tutte le questioni temporali. Fonte: https://old.reddit.com/r/StableDiffusion/comments/wyeoqq/turning_img2img_into_vid2vid/
Inversione testuale basata su cloud
Una soluzione migliore per suscitare personaggi e oggetti temporalmente coerenti è quella di "cuocerli" in un Inversione testuale – un file da 5 KB che può essere addestrato in poche ore sulla base di sole cinque immagini annotate, che possono quindi essere richiamate da uno speciale '*' rapido, consentendo, ad esempio, la comparsa persistente di nuovi personaggi da includere in una narrazione.

Le immagini associate ad appositi tag possono essere convertite in entità discrete tramite Textual Inversion, ed evocate senza ambiguità, e nel corretto contesto e stile, da speciali token words. Fonte: https://huggingface.co/docs/diffusers/training/text_inversion
Le inversioni testuali sono file aggiuntivi al modello molto ampio e completamente addestrato utilizzato da Stable Diffusion e sono effettivamente "inserite" nel processo di elicitazione/sollecitazione, in modo che possano partecipare in scene derivate da modelli e trarre vantaggio dall'enorme database di conoscenze del modello su oggetti, stili, ambienti e interazioni.
Tuttavia, sebbene un'inversione testuale non richieda molto tempo per l'addestramento, richiede un'elevata quantità di VRAM; secondo varie procedure dettagliate attuali, da qualche parte tra 12, 20 e persino 40 GB.
Poiché è improbabile che la maggior parte degli utenti occasionali abbia a disposizione quel tipo di GPU, stanno già emergendo servizi cloud che gestiranno l'operazione, inclusa una versione Hugging Face. Anche se ci sono Implementazioni di Google Colab che possono creare inversioni testuali per Stable Diffusion, la VRAM richiesta e i requisiti di tempo possono renderli difficili per gli utenti Colab di livello gratuito.
Per una potenziale applicazione Stable Diffusion (installata) completa e ben investita, trasferire questo compito gravoso ai server cloud dell'azienda sembra un'ovvia strategia di monetizzazione (supponendo che un'applicazione Stable Diffusion a basso costo o gratuita sia permeata da tale funzionalità non gratuita, il che sembra probabile in molte possibili applicazioni che emergeranno da questa tecnologia nei prossimi 6-9 mesi).
Inoltre, il processo piuttosto complesso di annotazione e formattazione delle immagini e del testo inviati potrebbe trarre vantaggio dall'automazione in un ambiente integrato. Il potenziale "fattore di dipendenza" nel creare elementi unici in grado di esplorare e interagire con i vasti mondi di Stable Diffusion sembrerebbe potenzialmente compulsivo, sia per gli appassionati in generale che per gli utenti più giovani.
Ponderazione rapida versatile
Esistono molte implementazioni correnti che consentono all'utente di assegnare maggiore enfasi a una sezione di un lungo prompt di testo, ma la strumentalità varia molto tra queste ed è spesso goffa o poco intuitiva.
La popolarissima forcella Stable Diffusion da AUTOMATIC1111, ad esempio, può abbassare o aumentare il valore di una parola rapida racchiudendola tra parentesi singole o multiple (per de-enfasi) o parentesi quadre per maggiore enfasi.

Parentesi quadre e/o tonde possono trasformare la tua colazione in questa versione dei pesi suggeriti da Stable Diffusion, ma in entrambi i casi è un incubo per il colesterolo.
Altre iterazioni di Stable Diffusion utilizzano punti esclamativi per dare enfasi, mentre le più versatili consentono agli utenti di assegnare pesi a ciascuna parola nel prompt tramite la GUI.
Il sistema dovrebbe anche consentire pesi prompt negativi – non solo per fan dell'orrore, ma perché potrebbero esserci misteri meno allarmanti e più edificanti nello spazio latente di Stable Diffusion di quanto il nostro limitato uso del linguaggio possa evocare.
Verniciatura
Poco dopo il sensazionale open-sourcing di Stable Diffusion, OpenAI ha tentato, in gran parte invano, di recuperare parte del suo tuono DALL-E 2 annunciando 'outpainting', che consente all'utente di estendere un'immagine oltre i suoi confini con logica semantica e coerenza visiva.
Naturalmente, questo è stato da allora implementato in varie forme per Diffusione Stabile, nonché a Crita, e dovrebbe certamente essere incluso in una versione completa, in stile Photoshop, di Stable Diffusion.
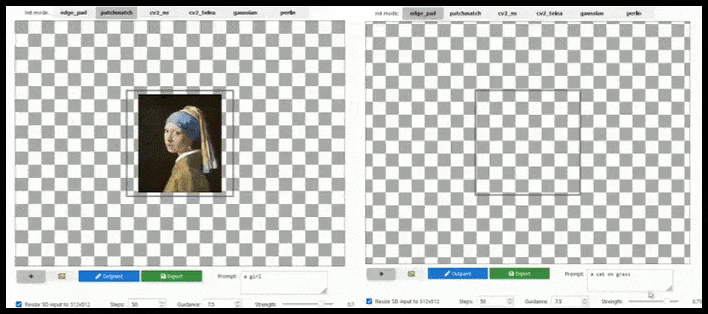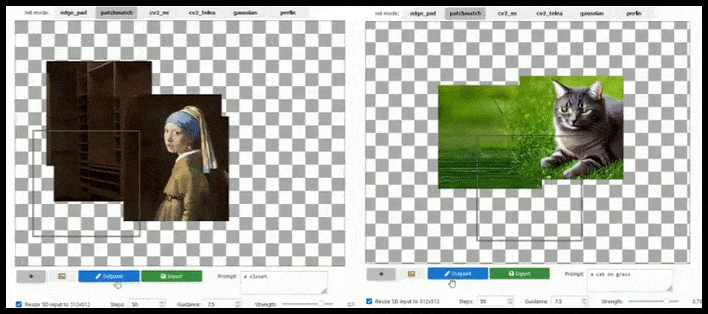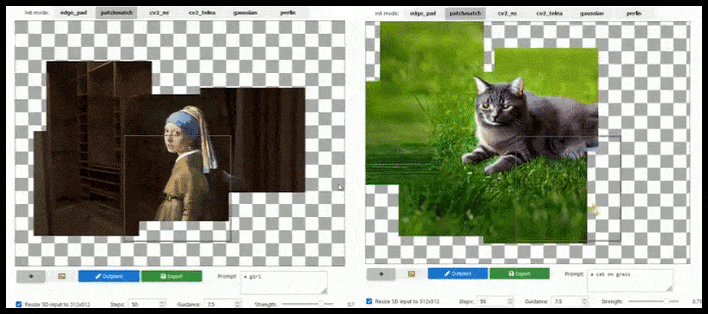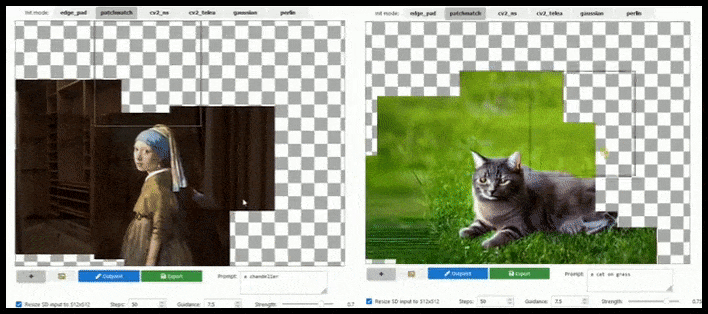
L'aumento basato su tile può estendere un rendering 512×512 standard quasi all'infinito, purché i prompt, l'immagine esistente e la logica semantica lo consentano. Fonte: https://github.com/lkwq007/stablediffusion-infinity
Poiché Stable Diffusion è addestrato su immagini da 512x512px (e per una serie di altri motivi), spesso taglia le teste (o altre parti essenziali del corpo) dei soggetti umani, anche quando il prompt indicava chiaramente "enfasi sulla testa", ecc.

Tipici esempi di "decapitazione" della diffusione stabile; ma la pittura esterna potrebbe rimettere George in scena.
Qualsiasi implementazione di outpainting del tipo illustrato nell'immagine animata sopra (che si basa esclusivamente su librerie Unix, ma dovrebbe essere in grado di essere replicata su Windows) dovrebbe anche essere utilizzata come rimedio con un clic/immediato per questo.
Attualmente, diversi utenti estendono verso l'alto la tela delle raffigurazioni "decapitate", riempiono approssimativamente l'area della testa e usano img2img per completare il rendering mal riuscito.
Mascheramento efficace che comprende il contesto
Masking-tape può essere un'operazione terribilmente imprevedibile in Stable Diffusion, a seconda del fork o della versione in questione. Spesso, laddove è possibile disegnare una maschera coesa, l'area specificata finisce per essere dipinta con contenuti che non tengono conto dell'intero contesto dell'immagine.
In un'occasione, ho mascherato le cornee di un'immagine del viso e ho fornito il suggerimento 'occhi azzurri' come una maschera dipinta, solo per scoprire che sembrava che stessi guardando attraverso due occhi umani ritagliati un'immagine lontana di un lupo dall'aspetto ultraterreno. Immagino di essere fortunato che non fosse Frank Sinatra.
L'editing semantico è possibile anche tramite identificare il rumore che ha costruito l'immagine in primo luogo, che consente all'utente di indirizzare elementi strutturali specifici in un rendering senza interferire con il resto dell'immagine:

Modifica di un elemento in un'immagine senza mascheramento tradizionale e senza alterare il contenuto adiacente, identificando il rumore che per primo ha originato l'immagine e indirizzando le parti di esso che hanno contribuito all'area di destinazione. Fonte: https://old.reddit.com/r/StableDiffusion/comments/xboy90/a_better_way_of_doing_img2img_by_finding_the/
Questo metodo si basa sul Campionatore K-diffusione.
Filtri semantici per errori fisiologici
Come abbiamo già detto, Stable Diffusion può spesso aggiungere o sottrarre arti, in gran parte a causa di problemi di dati e carenze nelle annotazioni che accompagnano le immagini che lo hanno addestrato.

Proprio come quel ragazzino ribelle che ha tirato fuori la lingua nella foto di gruppo della scuola, le atrocità biologiche di Stable Diffusion non sono sempre immediatamente evidenti, e potresti aver postato su Instagram il tuo ultimo capolavoro di intelligenza artificiale prima di notare le mani in più o gli arti sciolti.
È così difficile correggere questo tipo di errori che sarebbe utile se un'applicazione di diffusione stabile a grandezza naturale contenesse una sorta di sistema di riconoscimento anatomico che utilizza la segmentazione semantica per calcolare se l'immagine in arrivo presenta gravi carenze anatomiche (come nell'immagine sopra ) e lo scarta a favore di un nuovo rendering prima di presentarlo all'utente.

Ovviamente, potresti voler rendere la dea Kali, o Doctor Octopus, o persino salvare una parte non interessata di un'immagine afflitta da un arto, quindi questa funzione dovrebbe essere un interruttore opzionale.
Se gli utenti potessero tollerare l'aspetto della telemetria, tali mancate accensioni potrebbero persino essere trasmesse anonimamente in uno sforzo collettivo di apprendimento federativo che potrebbe aiutare i modelli futuri a migliorare la loro comprensione della logica anatomica.
Miglioramento facciale automatico basato su LAION
Come ho notato nel mio sguardo precedente Ci sono tre cose che Stable Diffusion potrebbe risolvere in futuro, ma non si dovrebbe lasciare che una qualsiasi versione di GFPGAN tenti di "migliorare" i volti renderizzati nei rendering di prima istanza.
I "miglioramenti" di GFPGAN sono terribilmente generici, spesso compromettono l'identità dell'individuo raffigurato e agiscono esclusivamente su un volto che solitamente è stato reso male, in quanto non ha ricevuto più tempo di elaborazione o attenzione di qualsiasi altra parte dell'immagine.
Pertanto, un programma professionale per la diffusione stabile dovrebbe essere in grado di riconoscere un volto (con una libreria standard e relativamente leggera come YOLO), applicare tutta la potenza della GPU disponibile per rielaborarlo e fondere il volto migliorato nel rendering originale a contesto completo, oppure salvarlo separatamente per la ricomposizione manuale. Attualmente, si tratta di un'operazione piuttosto "pratica".
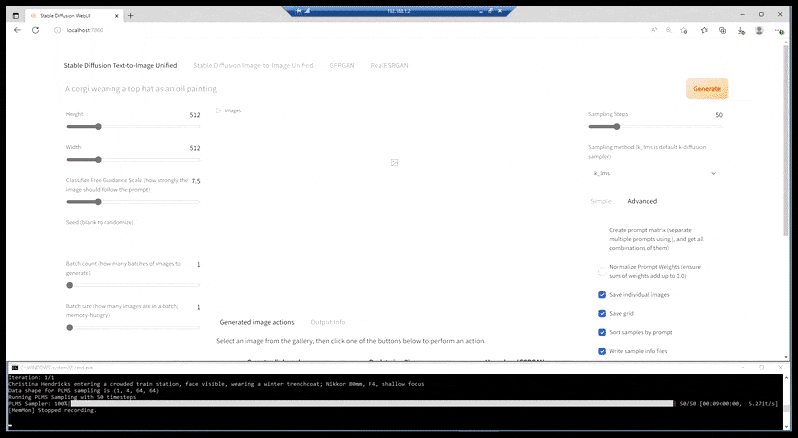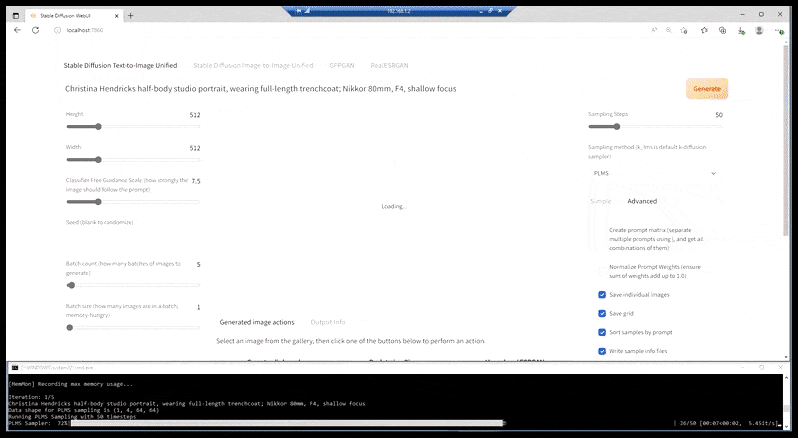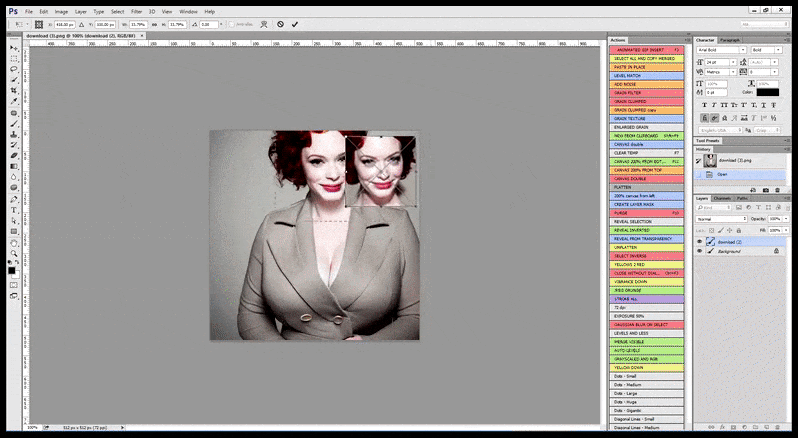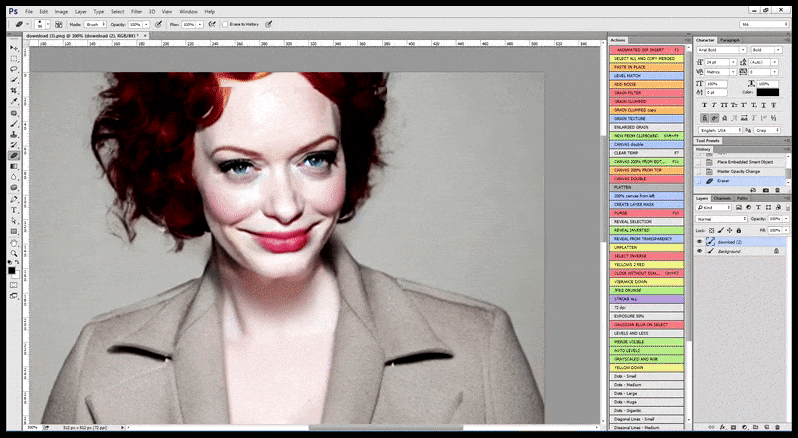
Nei casi in cui Stable Diffusion è stato addestrato su un numero adeguato di immagini di una celebrità, è possibile concentrare l'intera capacità della GPU su un rendering successivo esclusivamente del volto dell'immagine renderizzata, il che rappresenta solitamente un notevole miglioramento e, a differenza di GFPGAN, attinge alle informazioni dai dati addestrati da LAION, anziché semplicemente regolare i pixel renderizzati.
Ricerche LAION in-app
Da quando gli utenti hanno iniziato a rendersi conto che la ricerca di concetti, persone e temi nel database LAION avrebbe potuto rivelarsi utile per un migliore utilizzo di Stable Diffusion, sono stati creati diversi esploratori LAION online, tra cui haveibeentrained.com.

La funzione di ricerca su haveibeentrained.com consente agli utenti di esplorare le immagini che alimentano Stable Diffusion e di scoprire se oggetti, persone o idee che vorrebbero estrarre dal sistema siano stati probabilmente addestrati al suo interno. Tali sistemi sono utili anche per scoprire entità adiacenti, come il modo in cui le celebrità sono raggruppate o la "prossima idea" che deriva da quella attuale. Fonte: https://haveibeentrained.com/?search_text=bowl%20of%20fruit
Sebbene tali database basati sul Web spesso rivelino alcuni dei tag che accompagnano le immagini, il processo di generalizzazione che ha luogo durante l'addestramento del modello significa che è improbabile che una particolare immagine possa essere richiamata utilizzando il suo tag come prompt.
Inoltre, la rimozione di 'parole di stop' e la pratica della derivazione e della lemmatizzazione nell'elaborazione del linguaggio naturale significa che molte delle frasi esposte sono state suddivise o omesse prima di essere addestrate nella diffusione stabile.
Tuttavia, il modo in cui i raggruppamenti estetici si legano tra loro in queste interfacce può insegnare molto all'utente finale sulla logica (o, presumibilmente, sulla "personalità") di Stable Diffusion e rivelarsi un aiuto per una migliore produzione di immagini.
Conclusione
Ci sono molte altre funzionalità che mi piacerebbe vedere in un'implementazione desktop nativa completa di Stable Diffusion, come l'analisi delle immagini nativa basata su CLIP, che inverte il processo standard di Stable Diffusion e consente all'utente di estrarre frasi e parole che il sistema assocerebbe naturalmente all'immagine sorgente o al rendering.
Inoltre, il vero ridimensionamento basato su tessere sarebbe un'aggiunta gradita, poiché ESRGAN è uno strumento quasi altrettanto schietto di GFPGAN. Per fortuna, prevede di integrare il txt2imghd l'implementazione di GOBIG sta rapidamente rendendo questo una realtà attraverso le distribuzioni e sembra una scelta ovvia per un'iterazione desktop.
Alcune altre richieste popolari delle comunità Discord mi interessano meno, come i dizionari di prompt integrati e gli elenchi applicabili di artisti e stili, anche se un taccuino in-app o un lessico personalizzabile di frasi sembrerebbe un'aggiunta logica.
Allo stesso modo, gli attuali limiti dell'animazione incentrata sull'uomo in Stable Diffusion, sebbene avviati da CogVideo e vari altri progetti, rimangono incredibilmente nascenti e alla mercé della ricerca a monte sui precedenti temporali relativi all'autentico movimento umano.
Per ora, il video Stable Diffusion è rigorosamente psichedelici, anche se potrebbe avere un futuro molto più luminoso nel prossimo futuro nel campo dei burattini deepfake, tramite EbSynth e altre iniziative di conversione da testo a video relativamente nascenti (e vale la pena notare la mancanza di persone sintetizzate o "alterate" in Runway ultimo video promozionale).
Un'altra funzionalità preziosa sarebbe il pass-through trasparente di Photoshop, da tempo implementato nell'editor di texture di Cinema4D, tra le altre implementazioni simili. Grazie a questa funzionalità, è possibile trasferire facilmente le immagini tra le applicazioni e utilizzare ciascuna di esse per eseguire le trasformazioni in cui eccelle.
Infine, e forse la cosa più importante, un programma Stable Diffusion desktop completo dovrebbe essere in grado non solo di scambiare facilmente tra i checkpoint (ovvero le versioni del modello sottostante che alimenta il sistema), ma dovrebbe anche essere in grado di aggiornare le inversioni testuali personalizzate che hanno funzionato con versioni precedenti del modello ufficiale, ma potrebbe altrimenti essere rotto da versioni successive del modello (come hanno indicato gli sviluppatori del Discord ufficiale potrebbe essere il caso).
Ironia della sorte, l'organizzazione nella posizione migliore per creare una matrice così potente e integrata di strumenti per la diffusione stabile, Adobe, si è fortemente alleata con il Iniziativa di autenticità dei contenuti che potrebbe sembrare un passo falso retrogrado in termini di pubbliche relazioni per l'azienda, a meno che non ostacoli i poteri generativi di Stable Diffusion in modo così radicale come ha fatto OpenAI con DALL-E 2, e lo posizioni invece come una naturale evoluzione delle sue considerevoli partecipazioni nella fotografia stock.
Pubblicato per la prima volta il 15 settembre 2022.












