Intelligenza artificiale
Cerebras Introduce la Soluzione di Inferenza AI più Veloce al Mondo: 20 Volte la Velocità a un Prezzo Ridotto
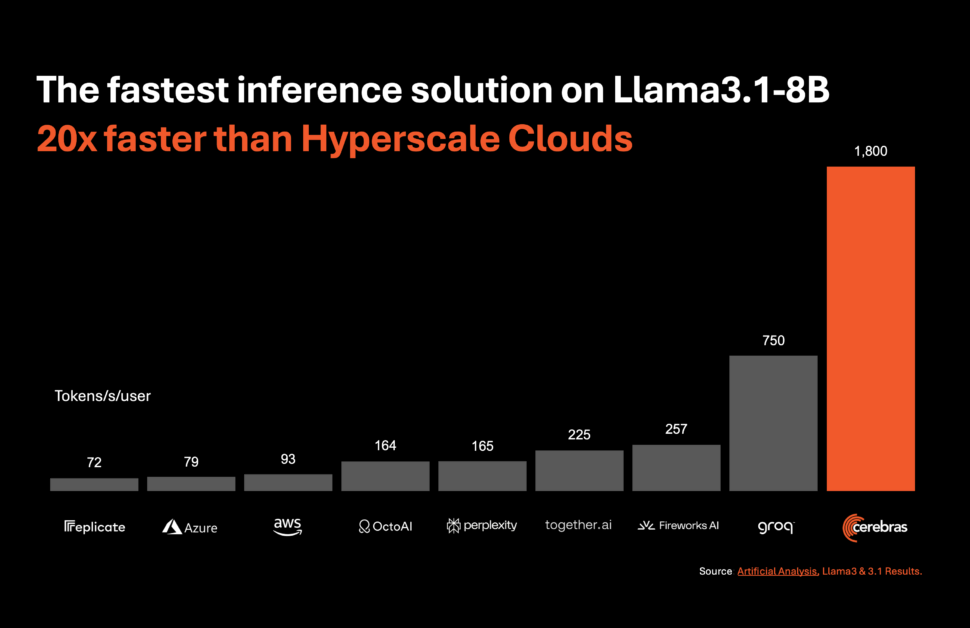
Cerebras Systems, un pioniere nel calcolo AI ad alte prestazioni, ha introdotto una soluzione rivoluzionaria che è destinata a rivoluzionare l’inferenza AI. Il 27 agosto 2024, l’azienda ha annunciato il lancio di Cerebras Inference, il servizio di inferenza AI più veloce al mondo. Con metriche di prestazione che oscurano quelle dei sistemi basati su GPU tradizionali, Cerebras Inference offre 20 volte la velocità a un prezzo ridotto, stabilendo un nuovo standard nel calcolo AI.
Velocità e Efficienza dei Costi senza Precedenti
Cerebras Inference è progettato per offrire prestazioni eccezionali in vari modelli AI, in particolare nel segmento in rapida evoluzione dei modelli linguistici di grandi dimensioni (LLM). Ad esempio, elabora 1.800 token al secondo per il modello Llama 3.1 8B e 450 token al secondo per il modello Llama 3.1 70B. Questa prestazione non è solo 20 volte più veloce rispetto a quella delle soluzioni basate su GPU NVIDIA, ma è anche disponibile a un prezzo significativamente inferiore. Cerebras offre questo servizio a partire da soli 10 centesimi per milione di token per il modello Llama 3.1 8B e 60 centesimi per milione di token per il modello Llama 3.1 70B, rappresentando un miglioramento della prestazione dei prezzi di 100 volte rispetto alle offerte basate su GPU esistenti.
Mantenere l’Precisione mentre si Spingono i Limiti della Velocità
Uno degli aspetti più impressionanti di Cerebras Inference è la sua capacità di mantenere la precisione di stato dell’arte mentre offre una velocità senza precedenti. A differenza di altri approcci che sacrificano la precisione per la velocità, la soluzione di Cerebras rimane nel dominio a 16 bit per l’intera esecuzione dell’inferenza. Ciò garantisce che i guadagni di prestazione non si verifichino a scapito della qualità dei risultati del modello AI, un fattore cruciale per gli sviluppatori focalizzati sulla precisione.
Micah Hill-Smith, co-fondatore e amministratore delegato di Artificial Analysis, ha sottolineato l’importanza di questo risultato: “Cerebras offre velocità di un ordine di grandezza superiore rispetto alle soluzioni basate su GPU per i modelli AI Llama 3.1 8B e 70B di Meta. Stiamo misurando velocità superiori a 1.800 token di output al secondo su Llama 3.1 8B e superiori a 446 token di output al secondo su Llama 3.1 70B – un nuovo record in questi benchmark.”
L’Importanza Crescente dell’Inferenza AI
L’inferenza AI è il segmento in più rapida crescita del calcolo AI, rappresentando circa il 40% del mercato totale dell’hardware AI. L’avvento dell’inferenza AI ad alta velocità, come quella offerta da Cerebras, è paragonabile all’introduzione di Internet a larga banda – sbloccando nuove opportunità e segnando l’inizio di una nuova era per le applicazioni AI. Con Cerebras Inference, gli sviluppatori possono ora costruire applicazioni AI di prossima generazione che richiedono prestazioni complesse e in tempo reale, come ad esempio agenti AI e sistemi intelligenti.
Andrew Ng, fondatore di DeepLearning.AI, ha sottolineato l’importanza della velocità nello sviluppo AI: “DeepLearning.AI ha più flussi di lavoro agente che richiedono di richiamare un LLM ripetutamente per ottenere un risultato. Cerebras ha costruito una capacità di inferenza impressionantemente veloce che sarà molto utile per tali carichi di lavoro.”

Ampio Supporto Industriale e Partnership Strategiche
Cerebras ha ottenuto un forte sostegno da leader del settore e ha formato partnership strategiche per accelerare lo sviluppo di applicazioni AI. Kim Branson, SVP di AI/ML di GlaxoSmithKline, un cliente precursore di Cerebras, ha enfatizzato il potenziale trasformativo di questa tecnologia: “Velocità e scala cambiano tutto.”
Altre aziende, come LiveKit, Perplexity e Meter, hanno espresso entusiasmo per l’impatto che Cerebras Inference avrà sulle loro operazioni. Queste aziende stanno sfruttando la potenza delle capacità di calcolo di Cerebras per creare esperienze AI più rispondenti e simili all’uomo, migliorare l’interazione degli utenti nei motori di ricerca ed elevare i sistemi di gestione della rete.
Cerebras Inference: Livelli e Accessibilità
Cerebras Inference è disponibile su tre livelli a prezzi competitivi: Free, Developer e Enterprise. Il livello Free offre l’accesso gratuito all’API con limiti di utilizzo generosi, rendendolo accessibile a un’ampia gamma di utenti. Il livello Developer offre un’opzione di distribuzione flessibile e serverless, con modelli Llama 3.1 a 10 centesimi e 60 centesimi per milione di token. Il livello Enterprise è destinato alle organizzazioni con carichi di lavoro sostenuti, offrendo modelli personalizzati, accordi di livello di servizio personalizzati e supporto dedicato, con prezzi disponibili su richiesta.
Alimentazione di Cerebras Inference: Wafer Scale Engine 3 (WSE-3)
Al cuore di Cerebras Inference c’è il sistema Cerebras CS-3, alimentato dal motore AI di classe mondiale Wafer Scale Engine 3 (WSE-3). Questo processore AI è senza pari per dimensioni e velocità, offrendo 7.000 volte più larghezza di banda della memoria rispetto all’H100 di NVIDIA. La scala massiccia del WSE-3 gli consente di gestire molti utenti contemporanei, garantendo velocità mozzafiato senza compromettere le prestazioni. Questa architettura consente a Cerebras di evitare i compromessi che di solito affliggono i sistemi basati su GPU, offrendo le migliori prestazioni di classe per i carichi di lavoro AI.
Integrazione Senza Soluzione di Continuità e API Amichevole per gli Sviluppatori
Cerebras Inference è progettato con gli sviluppatori in mente. Presenta un’API completamente compatibile con l’API OpenAI Chat Completions, consentendo una facile migrazione con modifiche minime al codice. Questo approccio amichevole per gli sviluppatori garantisce che l’integrazione di Cerebras Inference nei flussi di lavoro esistenti sia il più possibile senza soluzione di continuità, consentendo un rapido deploy di applicazioni AI ad alte prestazioni.
Cerebras Systems: Guida l’Innovazione in Tutti i Settori
Cerebras Systems non è solo un leader nel calcolo AI, ma anche un attore chiave in vari settori, tra cui sanità, energia, governo, calcolo scientifico e servizi finanziari. Le soluzioni dell’azienda sono state strumentali nel guidare innovazioni in istituzioni come i National Laboratories, Aleph Alpha, The Mayo Clinic e GlaxoSmithKline.
Fornendo velocità, scalabilità e precisione senza precedenti, Cerebras sta abilitando le organizzazioni in questi settori ad affrontare alcuni dei problemi più impegnativi nell’AI e oltre. Che si tratti di accelerare la scoperta di farmaci nel settore sanitario o di migliorare le capacità computazionali nella ricerca scientifica, Cerebras è alla forefront della guida dell’innovazione.
Conclusione: Una Nuova Era per l’Inferenza AI
Cerebras Systems sta stabilendo un nuovo standard per l’inferenza AI con il lancio di Cerebras Inference. Offrendo 20 volte la velocità dei sistemi basati su GPU tradizionali a un prezzo ridotto, Cerebras non solo rende l’AI più accessibile, ma apre la strada alle prossime generazioni di applicazioni AI. Con la sua tecnologia all’avanguardia, partnership strategiche e impegno per l’innovazione, Cerebras è pronta a guidare l’industria AI in una nuova era di prestazioni e scalabilità senza precedenti.
Per ulteriori informazioni su Cerebras Systems e per provare Cerebras Inference, visitare www.cerebras.ai.












