Kecerdasan buatan
Zero123++: Model Difusi Basis Multi-View Konsisten dari Gambar Tunggal

Beberapa tahun terakhir telah menyaksikan kemajuan pesat dalam kinerja, efisiensi, dan kemampuan generatif model AI generatif baru yang memanfaatkan dataset ekstensif dan praktik generasi difusi 2D. Saat ini, model AI generatif sangat mampu menghasilkan berbagai bentuk konten media 2D dan 3D, termasuk teks, gambar, video, GIF, dan lain-lain.
Dalam artikel ini, kita akan membahas tentang kerangka kerja Zero123++, model AI generatif difusi yang dikondisikan oleh gambar dengan tujuan menghasilkan gambar multi-view konsisten dari satu gambar input. Untuk memaksimalkan keuntungan yang diperoleh dari model generatif pra-dilatih sebelumnya, kerangka kerja Zero123++ menerapkan berbagai skema pelatihan dan kondisi untuk meminimalkan upaya yang diperlukan untuk fine-tuning dari model gambar difusi yang ada. Kita akan membahas lebih lanjut tentang arsitektur, cara kerja, dan hasil kerangka kerja Zero123++, serta menganalisis kemampuannya untuk menghasilkan gambar multi-view konsisten dengan kualitas tinggi dari satu gambar.
Zero123 dan Zero123++: Pengantar
Kerangka kerja Zero123++ adalah model AI generatif difusi yang dikondisikan oleh gambar dengan tujuan menghasilkan gambar multi-view konsisten dari satu gambar input. Kerangka kerja Zero123++ adalah kelanjutan dari kerangka kerja Zero123 atau Zero-1-to-3 yang menggunakan teknik sintesis gambar baru untuk mempelopori konversi gambar tunggal ke 3D yang terbuka. Meskipun kerangka kerja Zero123++ menawarkan kinerja yang menjanjikan, gambar yang dihasilkan oleh kerangka kerja ini memiliki inkonsistensi geometris yang terlihat, dan itulah alasan utama mengapa masih ada kesenjangan antara adegan 3D dan gambar multi-view.
Kerangka kerja Zero-1-to-3 berfungsi sebagai dasar untuk beberapa kerangka kerja lainnya, termasuk SyncDreamer, One-2-3-45, Consistent123, dan lain-lain yang menambahkan lapisan tambahan ke kerangka kerja Zero123 untuk mendapatkan hasil yang lebih konsisten saat menghasilkan gambar 3D. Kerangka kerja lain seperti ProlificDreamer, DreamFusion, DreamGaussian, dan lain-lain mengikuti pendekatan berbasis optimasi untuk mendapatkan gambar 3D dengan menyuling gambar 3D dari berbagai model yang tidak konsisten. Meskipun teknik-teknik ini efektif dan menghasilkan gambar 3D yang memuaskan, hasilnya dapat ditingkatkan dengan implementasi model difusi basis yang mampu menghasilkan gambar multi-view konsisten. Oleh karena itu, kerangka kerja Zero123++ mengambil kerangka kerja Zero-1-to-3 dan fine-tuning model difusi multi-view baru dari Stable Diffusion.
Dalam kerangka kerja Zero-1-to-3, setiap gambar baru dihasilkan secara independen, dan pendekatan ini menyebabkan inkonsistensi antara gambar yang dihasilkan karena model difusi memiliki sifat sampling. Untuk mengatasi masalah ini, kerangka kerja Zero123++ mengadopsi pendekatan tata letak tilting, dengan objek yang dikelilingi oleh enam gambar menjadi satu gambar, dan memastikan pemodelan yang benar untuk distribusi bersama dari gambar multi-view objek.
Masalah besar lain yang dihadapi oleh pengembang yang bekerja pada kerangka kerja Zero-1-to-3 adalah bahwa kerangka kerja ini tidak memanfaatkan kemampuan yang ditawarkan oleh Stable Diffusion secara efektif, yang pada akhirnya menyebabkan ketidakefisienan dan biaya tambahan. Ada dua alasan utama mengapa kerangka kerja Zero-1-to-3 tidak dapat memaksimalkan kemampuan yang ditawarkan oleh Stable Diffusion
- Saat pelatihan dengan kondisi gambar, kerangka kerja Zero-1-to-3 tidak mengintegrasikan mekanisme kondisi lokal atau global yang ditawarkan oleh Stable Diffusion secara efektif.
- Selama pelatihan, kerangka kerja Zero-1-to-3 menggunakan resolusi yang dikurangi, suatu pendekatan di mana resolusi output dikurangi di bawah resolusi pelatihan yang dapat mengurangi kualitas generasi gambar untuk model Stable Diffusion.
Untuk mengatasi masalah-masalah ini, kerangka kerja Zero123++ menerapkan berbagai teknik kondisi yang memaksimalkan pemanfaatan sumber daya yang ditawarkan oleh Stable Diffusion dan mempertahankan kualitas generasi gambar untuk model Stable Diffusion.
Meningkatkan Kondisi dan Konsistensi
Dalam upaya meningkatkan kondisi gambar dan konsistensi gambar multi-view, kerangka kerja Zero123++ menerapkan berbagai teknik, dengan tujuan utama adalah menggunakan kembali teknik-teknik sebelumnya yang bersumber dari model Stable Diffusion yang pra-dilatih.
Generasi Multi-View
Kualitas yang sangat penting dalam menghasilkan gambar multi-view konsisten terletak pada pemodelan distribusi bersama dari gambar multi-view dengan benar. Dalam kerangka kerja Zero-1-to-3, korelasi antara gambar multi-view diabaikan karena untuk setiap gambar, kerangka kerja memodelkan distribusi marginal kondisional secara independen dan terpisah. Namun, dalam kerangka kerja Zero123++, pengembang telah memilih pendekatan tata letak tilting yang menilai enam gambar menjadi satu bingkai/gambar untuk generasi multi-view konsisten, dan proses ini didemonstrasikan dalam gambar berikut.
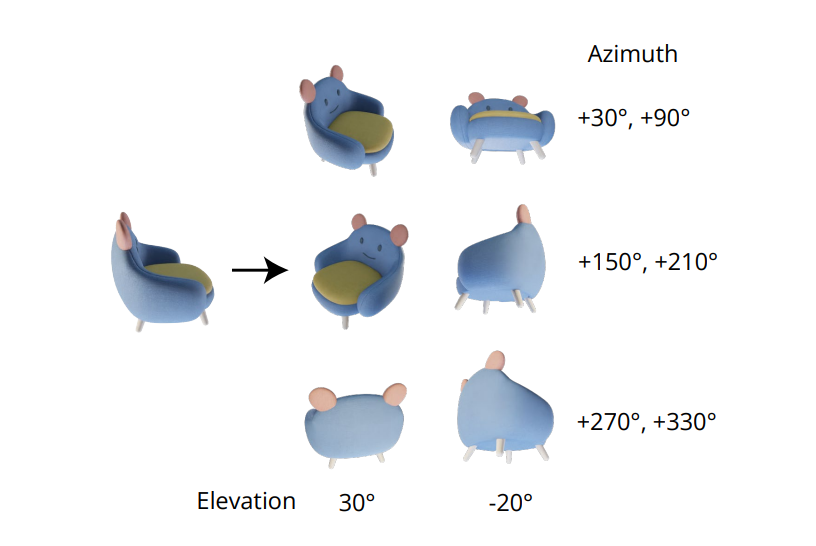

Selain itu, telah ditemukan bahwa orientasi objek cenderung membingungkan saat melatih model pada pose kamera, dan untuk mencegah kebingungan ini, kerangka kerja Zero-1-to-3 melatih pada pose kamera dengan sudut elevasi dan azimut relatif terhadap input. Untuk menerapkan pendekatan ini, perlu diketahui sudut elevasi dari tampilan input yang kemudian digunakan untuk menentukan pose relatif antara tampilan input baru.
Jadwal Kebisingan
Jadwal linier berskala, jadwal kebisingan asli untuk Stable Diffusion, berfokus terutama pada detail lokal, tetapi seperti yang dapat dilihat dalam gambar berikut, jadwal ini memiliki sangat sedikit langkah dengan SNR atau Rasio Sinyal terhadap Kebisingan yang lebih rendah.


Langkah-langkah dengan SNR rendah ini terjadi pada awal tahap denoising, tahap yang sangat penting untuk menentukan struktur frekuensi rendah global. Mengurangi jumlah langkah selama tahap denoising, baik selama interferensi atau pelatihan, seringkali menghasilkan variasi struktural yang lebih besar. Meskipun pengaturan ini ideal untuk generasi gambar tunggal, pengaturan ini membatasi kemampuan kerangka kerja untuk memastikan konsistensi global antara berbagai tampilan. Untuk mengatasi hambatan ini, kerangka kerja Zero123++ fine-tuning model LoRA pada kerangka kerja Stable Diffusion 2 v-prediction untuk melakukan tugas mainan, dan hasilnya didemonstrasikan di bawah.

Dengan jadwal kebisingan linier berskala, model LoRA tidak overfit, tetapi hanya memutihkan gambar sedikit. Sebaliknya, ketika bekerja dengan jadwal kebisingan linier, kerangka kerja LoRA menghasilkan gambar kosong dengan sukses, terlepas dari prompt input, sehingga menunjukkan dampak jadwal kebisingan pada kemampuan kerangka kerja untuk beradaptasi dengan persyaratan global baru.
Perhatian Referensi Berskala untuk Kondisi Lokal
Gambar input tunggal atau gambar kondisi dalam kerangka kerja Zero-1-to-3 dihubungkan dengan input yang berisik dalam dimensi fitur untuk dikondisikan.
Penghubungan ini menyebabkan korespondensi spasial piksel yang tidak tepat antara gambar target dan input. Untuk memberikan input kondisi lokal yang tepat, kerangka kerja Zero123++ menggunakan Perhatian Referensi Berskala, suatu pendekatan di mana menjalankan model denoising UNet yang dirujuk pada gambar referensi tambahan, diikuti oleh penambahan matriks nilai dan kunci perhatian diri dari gambar referensi ke lapisan perhatian yang sesuai ketika input model dikondisikan, dan proses ini didemonstrasikan dalam gambar berikut.

Pendekatan Perhatian Referensi mampu memandu model difusi untuk menghasilkan gambar yang berbagi tekstur yang mirip dengan gambar referensi dan konten semantik tanpa fine-tuning. Dengan fine-tuning, pendekatan Perhatian Referensi memberikan hasil yang lebih baik dengan laten yang diskalakan.

Kondisi Global: FlexDiffuse
Dalam pendekatan Stable Diffusion asli, penyematan teks adalah satu-satunya sumber untuk penyematan global, dan pendekatan ini menggunakan kerangka kerja CLIP sebagai pengkode teks untuk melakukan pemeriksaan silang antara penyematan teks dan laten model. Akibatnya, pengembang bebas menggunakan kesejajaran antara ruang teks dan gambar CLIP yang dihasilkan untuk kondisi gambar global.
Kerangka kerja Zero123++ mengusulkan untuk menggunakan varian trainable dari mekanisme bimbingan linier untuk mengintegrasikan kondisi gambar global ke dalam kerangka kerja dengan fine-tuning minimal yang diperlukan, dan hasilnya didemonstrasikan dalam gambar berikut. Seperti yang dapat dilihat, tanpa kehadiran kondisi gambar global, kualitas konten yang dihasilkan oleh kerangka kerja ini memuaskan untuk wilayah yang terlihat yang sesuai dengan gambar input. Namun, kualitas gambar yang dihasilkan oleh kerangka kerja ini untuk wilayah yang tidak terlihat mengalami penurunan yang signifikan, yang sebagian besar disebabkan oleh ketidakmampuan model untuk menyimpulkan semantik global objek.

Arsitektur Model
Kerangka kerja Zero123++ dilatih dengan model Stable Diffusion 2v sebagai dasar menggunakan pendekatan dan teknik yang disebutkan dalam artikel ini. Kerangka kerja Zero123++ pra-dilatih pada dataset Objaverse yang dirender dengan pencahayaan HDRI acak. Kerangka kerja ini juga mengadopsi pendekatan jadwal pelatihan bertahap yang digunakan dalam kerangka kerja Stable Diffusion Image Variations dalam upaya untuk lebih meminimalkan jumlah fine-tuning yang diperlukan dan mempertahankan sebanyak mungkin prior Stable Diffusion.
Cara kerja atau arsitektur kerangka kerja Zero123++ dapat dibagi lebih lanjut menjadi langkah-langkah atau fase berurutan. Fase pertama menyaksikan kerangka kerja fine-tuning matriks KV dari lapisan perhatian silang dan lapisan perhatian diri dari Stable Diffusion dengan AdamW sebagai pengoptimalkan, 1000 langkah pemanasan, dan jadwal pembelajaran kosinus yang memaksimalkan pada 7×10-5. Pada fase kedua, kerangka kerja ini menggunakan tingkat pembelajaran konstan yang sangat konservatif dengan 2000 set pemanasan, dan menggunakan pendekatan Min-SNR untuk memaksimalkan efisiensi selama pelatihan.
Zero123++: Hasil dan Perbandingan Kinerja
Kinerja Kualitatif
Untuk menilai kinerja kerangka kerja Zero123++ berdasarkan kualitas yang dihasilkan, kerangka kerja ini dibandingkan dengan SyncDreamer dan Zero-1-to-3-XL, dua kerangka kerja terbaik saat ini untuk generasi konten. Kerangka kerja ini dibandingkan dengan empat gambar input yang berbeda dengan cakupan yang berbeda. Gambar pertama adalah mainan kucing listrik, diambil langsung dari dataset Objaverse, dan memiliki ketidakpastian yang besar pada bagian belakang objek. Kedua adalah gambar pemadam api, dan yang ketiga adalah gambar anjing yang duduk di roket, yang dihasilkan oleh model SDXL. Gambar terakhir adalah ilustrasi anime. Langkah-langkah ketinggian yang diperlukan untuk kerangka kerja ini dicapai dengan menggunakan metode estimasi ketinggian dari kerangka kerja One-2-3-4-5, dan penghapusan latar belakang dicapai menggunakan kerangka kerja SAM. Seperti yang dapat dilihat, kerangka kerja Zero123++ menghasilkan gambar multi-view dengan kualitas tinggi secara konsisten dan mampu menggeneralisasi ke ilustrasi 2D di luar domain dan gambar yang dihasilkan oleh AI dengan sama baiknya.


Analisis Kuantitatif
Untuk membandingkan kerangka kerja Zero123++ secara kuantitatif dengan kerangka kerja Zero-1-to-3 dan Zero-1-to-3-XL yang ada, pengembang mengevaluasi skor Similaritas Patch Gambar Perceptual yang Dipelajari (LPIPS) dari model-model ini pada data validasi, subset dari dataset Objaverse. Untuk mengevaluasi kinerja model pada generasi gambar multi-view, pengembang menilai gambar referensi ground truth dan enam gambar yang dihasilkan, kemudian menghitung skor LPIPS. Hasilnya didemonstrasikan di bawah dan seperti yang dapat dilihat, kerangka kerja Zero123++ mencapai kinerja terbaik pada set validasi.

Evaluasi Teks ke Multi-View
Untuk mengevaluasi kemampuan kerangka kerja Zero123++ dalam generasi konten teks ke multi-view, pengembang pertama kali menggunakan kerangka kerja SDXL dengan prompt teks untuk menghasilkan gambar, kemudian menggunakan kerangka kerja Zero123++ pada gambar yang dihasilkan. Hasilnya didemonstrasikan dalam gambar berikut, dan seperti yang dapat dilihat, dibandingkan dengan kerangka kerja Zero-1-to-3 yang tidak dapat menjamin generasi multi-view konsisten, kerangka kerja Zero123++ mengembalikan gambar multi-view yang konsisten, realistis, dan sangat detail dengan menerapkan pendekatan teks-ke-gambar-ke-multi-view atau pipeline.

Zero123++ Depth ControlNet
Selain kerangka kerja Zero123++ dasar, pengembang juga telah merilis Depth ControlNet Zero123++, versi yang dikontrol oleh kedalaman dari kerangka kerja asli yang dibangun menggunakan arsitektur ControlNet. Gambar linier yang dinormalisasi dirender dengan menghormati gambar RGB berikutnya, dan kerangka kerja ControlNet dilatih untuk mengontrol geometri kerangka kerja Zero123++ menggunakan persepsi kedalaman.


Kesimpulan
Dalam artikel ini, kita telah membahas tentang Zero123++, model AI generatif difusi yang dikondisikan oleh gambar dengan tujuan menghasilkan gambar multi-view konsisten dari satu gambar input. Untuk memaksimalkan keuntungan yang diperoleh dari model generatif pra-dilatih sebelumnya, kerangka kerja Zero123++ menerapkan berbagai skema pelatihan dan kondisi untuk meminimalkan upaya yang diperlukan untuk fine-tuning dari model gambar difusi yang ada. Kita juga telah membahas tentang pendekatan dan peningkatan yang diterapkan oleh kerangka kerja Zero123++ yang membantu mencapai hasil yang setara dengan, dan bahkan melebihi, yang dicapai oleh kerangka kerja saat ini.
Namun, meskipun efisiensinya dan kemampuan menghasilkan gambar multi-view dengan kualitas tinggi secara konsisten, kerangka kerja Zero123++ masih memiliki ruang untuk perbaikan, dengan area penelitian potensial seperti Model Pemurni Dua Tahap yang mungkin dapat menyelesaikan ketidakmampuan Zero123++ untuk memenuhi persyaratan konsistensi global. Peningkatan Skala Tambahan untuk lebih meningkatkan kemampuan Zero123++ dalam menghasilkan gambar dengan kualitas yang lebih tinggi.
- Model Pemurni Dua Tahap yang mungkin dapat menyelesaikan ketidakmampuan Zero123++ untuk memenuhi persyaratan konsistensi global.
- Peningkatan Skala Tambahan untuk lebih meningkatkan kemampuan Zero123++ dalam menghasilkan gambar dengan kualitas yang lebih tinggi.












