Sudut Anderson
Mengapa Serangan Gambar Adversarial Bukanlah Bahan Lelucon
Menggunakan gambar yang dirancang dengan hati-hati untuk menyerang sistem pengenalan gambar telah dianggap sebagai konsep yang lucu tetapi sepele selama lima tahun terakhir. Namun, penelitian baru dari Australia menunjukkan bahwa penggunaan kasual dari kumpulan data gambar yang sangat populer untuk proyek AI komersial dapat menciptakan masalah keamanan baru yang berkelanjutan.
Beberapa tahun terakhir, sekelompok akademisi di Universitas Adelaide telah berusaha menjelaskan sesuatu yang sangat penting tentang masa depan sistem pengenalan gambar berbasis AI.
Ini adalah sesuatu yang akan sulit (dan sangat mahal) untuk diperbaiki sekarang, dan yang akan sangat mahal untuk diperbaiki sekali tren penelitian pengenalan gambar saat ini telah sepenuhnya dikembangkan menjadi penerapan komersial dan industri dalam 5-10 tahun ke depan.
Sebelum kita memasuki topik tersebut, mari kita lihat bunga yang diklasifikasikan sebagai Presiden Barack Obama, dari salah satu enam video yang dipublikasikan di halaman proyek:
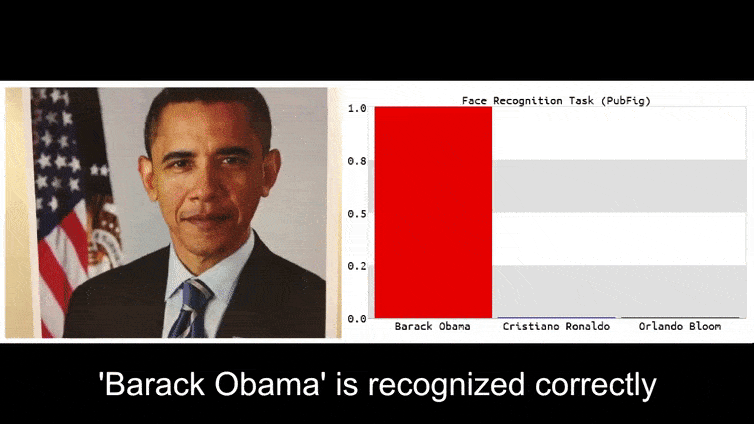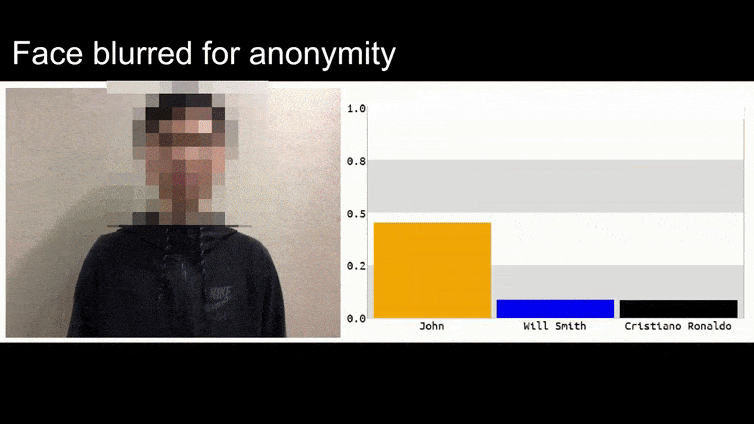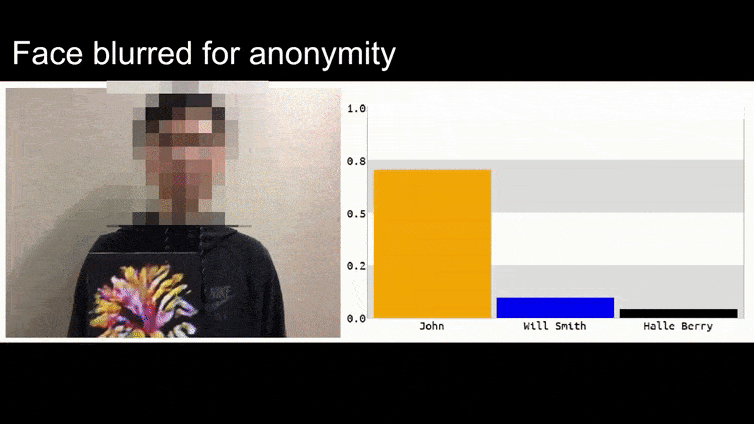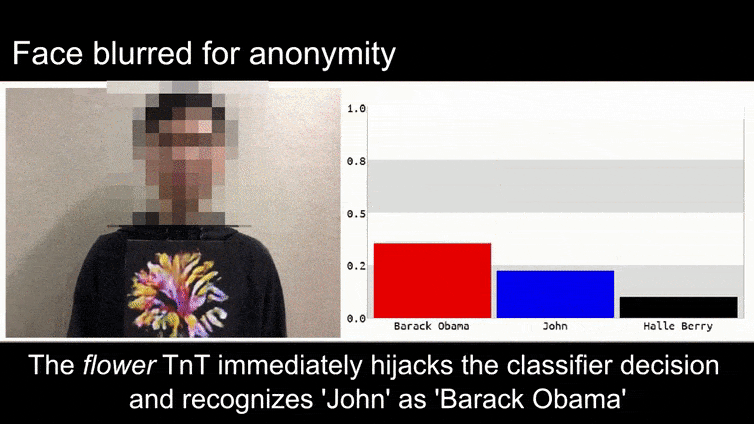
Sumber: https://www.youtube.com/watch?v=Klepca1Ny3c
Di gambar di atas, sistem pengenalan wajah yang jelas tahu cara mengenali Barack Obama dipengaruhi oleh 80% keyakinan bahwa seorang pria anonim yang memegang gambar adversarial yang dirancang dan dicetak dari bunga juga adalah Barack Obama. Sistem tidak peduli bahwa ‘wajah palsu’ berada di dada subjek, bukan di bahu.
Walaupun impresif bahwa peneliti telah dapat melakukan jenis penangkapan identitas ini dengan menghasilkan gambar yang koheren (sebuah bunga) bukan hanya noise acak, tampaknya eksploitasi yang konyol seperti ini muncul secara teratur dalam penelitian keamanan tentang penglihatan komputer. Misalnya, kacamata yang berpola aneh yang dapat menipu pengenalan wajah pada tahun 2016, atau gambar adversarial yang dirancang khusus yang berusaha untuk menulis ulang tanda jalan.
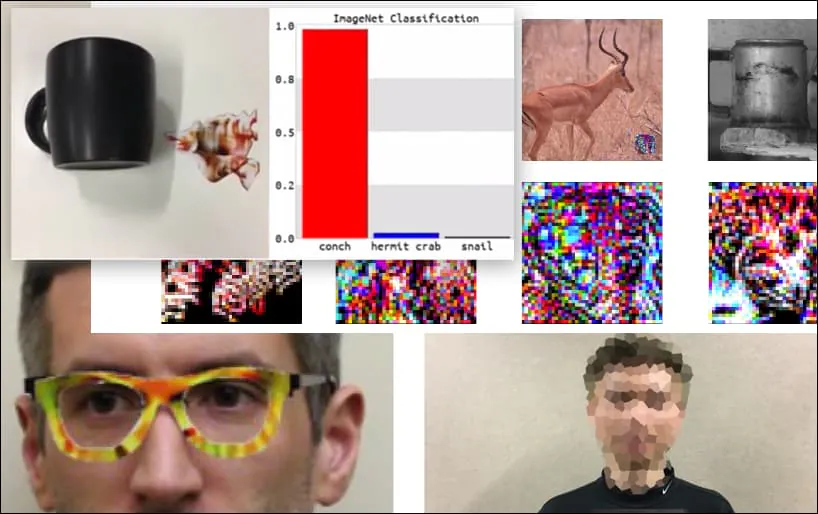
Jika Anda tertarik, model Convolutional Neural Network (CNN) yang diserang dalam contoh di atas adalah VGGFace (VGG-16), yang dilatih pada dataset PubFig dari Universitas Columbia. Contoh serangan lain yang dikembangkan oleh peneliti menggunakan sumber daya yang berbeda dalam kombinasi yang berbeda.

Sebuah keyboard diklasifikasikan sebagai conch, dalam model WideResNet50 pada ImageNet. Peneliti juga telah memastikan bahwa model tidak memiliki bias terhadap conch. Lihat video lengkap untuk demonstrasi tambahan di https://www.youtube.com/watch?v=dhTTjjrxIcU
Pengenalan Gambar sebagai Vektor Serangan yang Muncul
Banyak serangan yang impresif yang dilakukan oleh peneliti dan diilustrasikan tidak merupakan kritik terhadap dataset atau arsitektur pembelajaran mesin tertentu yang menggunakan dataset tersebut. Tidak juga dapat dengan mudah dibela dengan beralih ke dataset atau model lain, melatih kembali model, atau salah satu “obat” sederhana lainnya yang menyebabkan praktisi ML menganggap enteng demonstrasi tipu muslihat seperti ini.
Sebaliknya, eksploitasi tim Adelaide menggambarkan kelemahan sentral dalam arsitektur pengembangan AI pengenalan gambar saat ini; kelemahan yang dapat memaparkan banyak sistem pengenalan gambar di masa depan pada manipulasi yang mudah oleh penyerang, dan memasang langkah-langkah pertahanan pada posisi yang sulit.
Bayangkan serangan gambar adversarial terbaru (seperti bunga di atas) ditambahkan sebagai ‘zero-day exploits’ ke sistem keamanan di masa depan, sama seperti kerangka anti-malware dan antivirus saat ini memperbarui definisi virus setiap hari.
Potensi untuk serangan gambar adversarial baru akan tidak terbatas, karena arsitektur sistem tidak memprediksi masalah hilir, seperti yang terjadi dengan internet, Millennium Bug, dan Menara Pisa yang miring.
Dalam cara apa, maka, kita mempersiapkan diri untuk ini?
Mendapatkan Data untuk Serangan
Gambar adversarial seperti contoh ‘bunga’ di atas dihasilkan dengan memiliki akses ke dataset gambar yang melatih model komputer. Anda tidak perlu ‘akses istimewa’ ke data pelatihan (atau arsitektur model), karena dataset paling populer (dan banyak model yang dilatih) tersedia secara luas dalam torrent yang kuat dan terus diperbarui.
Sebagai contoh, dataset Goliath dari Computer Vision, ImageNet, tersedia di Torrent dalam semua iterasinya, melewati batasan biasanya, dan membuat tersedia elemen sekunder yang penting, seperti set validasi.

Sumber: https://academictorrents.com
Jika Anda memiliki data, Anda dapat (seperti yang diamati oleh peneliti Adelaide) secara efektif ‘mengembalikan’ dataset populer mana pun, seperti CityScapes, atau CIFAR.
Dalam kasus PubFig, dataset yang memungkinkan ‘Obama Flower’ dalam contoh sebelumnya, Universitas Columbia telah menangani tren yang berkembang dalam masalah hak cipta sekitar redistribusi dataset gambar dengan menginstruksikan peneliti tentang cara menghasilkan kembali dataset melalui tautan yang dikurasi, bukan membuat kompilasi langsung tersedia, dengan mengamati ‘Ini tampaknya merupakan cara yang digunakan oleh basis data web besar lainnya’.
Di sebagian besar kasus, itu tidak perlu; Kaggle memperkirakan bahwa sepuluh dataset gambar paling populer dalam penglihatan komputer adalah: CIFAR-10 dan CIFAR-100 (keduanya dapat diunduh langsung); CALTECH-101 dan 256 (keduanya tersedia, dan keduanya saat ini tersedia sebagai torrent); MNIST (tersedia secara resmi, juga di torrent); ImageNet (lihat di atas); Pascal VOC (tersedia, juga di torrent); MS COCO (tersedia, dan di torrent); Sports-1M (tersedia); dan YouTube-8M (tersedia).
Ketersediaan ini juga merupakan representasi dari kisaran dataset gambar penglihatan komputer yang tersedia, karena kerahasiaan adalah kematian dalam budaya pengembangan sumber terbuka ‘publikasikan atau mati’.
Dalam kasus apa pun, kelangkaan dataset baru yang dapat dikelola, biaya tinggi pengembangan dataset gambar, ketergantungan pada ‘favorit lama’, dan kecenderungan untuk menyesuaikan dataset lama semuanya memperburuk masalah yang diuraikan dalam makalah Adelaide baru.
Kritik Umum terhadap Metode Serangan Gambar Adversarial
Kritik paling sering dan persisten dari insinyur pembelajaran mesin terhadap efektivitas teknik serangan gambar adversarial terbaru adalah bahwa serangan tersebut spesifik untuk dataset tertentu, model tertentu, atau keduanya; bahwa tidak ‘dapat digeneralisasi’ ke sistem lain; dan, konsekuensinya, mewakili ancaman yang sepele.
Kritik kedua paling sering adalah bahwa serangan gambar adversarial adalah ‘white box’, yang berarti bahwa Anda perlu memiliki akses langsung ke lingkungan pelatihan atau data. Ini memang merupakan skenario yang tidak mungkin, dalam kebanyakan kasus – misalnya, jika Anda ingin mengeksploitasi proses pelatihan untuk sistem pengenalan wajah Polisi Metropolitan London, Anda harus membobol jalan ke NEC, baik dengan konsol atau gergaji.
‘DNA’ Jangka Panjang dari Dataset Penglihatan Komputer Populer
Mengenai kritik pertama, kita harus mempertimbangkan tidak hanya bahwa segelintir dataset penglihatan komputer mendominasi industri dengan sektor tahun demi tahun (yaitu ImageNet untuk banyak jenis objek, CityScapes untuk adegan mengemudi, dan FFHQ untuk pengenalan wajah); tetapi juga bahwa, sebagai data gambar yang dianotasi sederhana, mereka ‘platform agnostik’ dan sangat dapat dipindahkan.
Bergantung pada kemampuannya, arsitektur pelatihan penglihatan komputer mana pun akan menemukan beberapa fitur objek dan kelas dalam dataset ImageNet. Beberapa arsitektur mungkin menemukan lebih banyak fitur daripada yang lain, atau membuat koneksi yang lebih berguna daripada yang lain, tetapi semua harus menemukan setidaknya fitur tingkat tertinggi:

Data ImageNet, dengan jumlah identifikasi yang benar minimum – fitur ‘tingkat tinggi’.
Itulah ‘fitur tingkat tinggi’ yang membedakan dan ‘mencetak’ dataset, dan yang merupakan ‘kait’ yang dapat diandalkan untuk menggantungkan metode serangan gambar adversarial jangka panjang yang dapat melintasi sistem yang berbeda, dan tumbuh seiring dengan ‘dataset lama’ saat dataset tersebut dipertahankan dalam penelitian dan produk baru.
Arsitektur yang lebih canggih akan menghasilkan identifikasi yang lebih akurat dan granular, fitur dan kelas:

Namun, semakin banyak generator serangan adversarial bergantung pada fitur lebih rendah (yaitu ‘Pria Kaukasia Muda’ bukan ‘Wajah’), semakin tidak efektifnya akan dalam arsitektur yang berbeda atau kemudian yang menggunakan versi yang berbeda dari dataset asli – seperti subset atau set yang disaring, di mana banyak gambar asli dari dataset penuh tidak hadir:

Serangan Adversarial pada Model Pratrain yang ‘Dinolkan’
Apa yang terjadi pada kasus di mana Anda hanya mengunduh model pratrain yang awalnya dilatih pada dataset yang sangat populer, dan memberinya data baru?
Model telah dilatih pada (misalnya) ImageNet, dan semua yang tersisa adalah bobot, yang mungkin membutuhkan waktu beberapa minggu atau bulan untuk dilatih, dan sekarang siap untuk membantu Anda mengidentifikasi objek yang serupa dengan yang ada dalam data asli (yang sekarang tidak ada).

Dengan data asli dihilangkan dari arsitektur pelatihan, apa yang tersisa adalah ‘kecenderungan’ model untuk mengklasifikasikan objek dengan cara yang sama seperti yang dilakukan sebelumnya, yang pada dasarnya akan menyebabkan banyak ‘tanda tangan’ asli untuk direformasi dan menjadi rentan lagi terhadap metode serangan gambar adversarial yang sama.
Bobot tersebut sangat berharga. Tanpa data atau bobot, Anda pada dasarnya memiliki arsitektur kosong tanpa data. Anda harus melatihnya dari awal, dengan biaya waktu dan sumber daya komputasi yang besar, seperti yang dilakukan oleh penulis asli (mungkin dengan perangkat keras yang lebih kuat dan anggaran yang lebih besar daripada yang Anda miliki).
Masalahnya adalah bobot sudah cukup terbentuk dan kuat. Meskipun akan beradaptasi sedikit dalam pelatihan, mereka akan berperilaku serupa pada data baru seperti yang mereka lakukan pada data asli, menghasilkan fitur tanda tangan yang sistem serangan gambar adversarial dapat kaitkan kembali.
Dalam jangka panjang, ini juga mempertahankan ‘DNA’ dari dataset penglihatan komputer yang berusia dua belas tahun atau lebih, dan mungkin telah melewati evolusi yang signifikan dari upaya sumber terbuka hingga penerapan komersial – bahkan ketika data pelatihan asli sepenuhnya dibuang di awal proyek. Beberapa penerapan komersial ini mungkin tidak terjadi selama beberapa tahun ke depan.
Tidak Perlu ‘White Box’
Mengenai kritik kedua yang umum dari sistem serangan gambar adversarial, penulis makalah baru telah menemukan bahwa kemampuan mereka untuk menipu sistem pengenalan dengan gambar yang dirancang dengan hati-hati sangat dapat dipindahkan di seluruh arsitektur.
Sambil mengamati bahwa metode ‘Universal NaTuralistic adversarial paTches’ (TnT) mereka adalah yang pertama menggunakan gambar yang dapat dikenali (bukan noise gangguan acak) untuk menipu sistem pengenalan gambar, penulis juga menyatakan:
‘[TnTs] efektif melawan banyak kelas pengenalan yang canggih, mulai dari WideResNet50 yang banyak digunakan di ImageNet hingga model VGG-face di dataset PubFig dalam tugas pengenalan wajah, baik dalam serangan targeted maupun untargeted.
‘TnTs dapat memiliki: i) naturalisme yang dapat dicapai [dengan] pemicu yang digunakan dalam metode serangan Trojan; dan ii) generalisasi dan transferabilitas contoh adversarial ke jaringan lain.
‘Ini menimbulkan kekhawatiran keamanan dan keselamatan terkait DNN yang sudah diterapkan serta penerapan DNN di masa depan di mana penyerang dapat menggunakan patch objek alami yang tidak mencolok untuk menyesatkan sistem jaringan saraf tanpa mengganggu model dan berisiko terdeteksi.’
Penulis menyarankan bahwa tindakan pencegahan konvensional, seperti melemahkan Akurasi Bersih dari jaringan, secara teoretis dapat memberikan beberapa pertahanan terhadap patch TnT, tetapi bahwa ‘TnTs masih dapat berhasil melewati metode pertahanan ini dengan sebagian besar sistem pertahanan mencapai 0% Keamanan’.
Penyelesaian lain yang mungkin termasuk pembelajaran terdistribusi, di mana asal-usul gambar yang berkontribusi dilindungi, dan pendekatan baru yang dapat langsung ‘mengenkripsi’ data pada saat pelatihan, seperti yang baru-baru ini disarankan oleh Universitas Penerbangan dan Astronautika Nanjing.
Meskipun demikian, penting untuk melatih pada data gambar yang benar-benar baru – sekarang gambar dan anotasi yang terkait dalam kelompok kecil dataset CV paling populer sangat tertanam dalam siklus pengembangan di seluruh dunia sehingga tampak seperti perangkat lunak lebih dari data; perangkat lunak yang sering tidak diperbarui selama bertahun-tahun.
Kesimpulan
Serangan gambar adversarial dimungkinkan tidak hanya oleh praktik pembelajaran mesin sumber terbuka, tetapi juga oleh budaya pengembangan AI komersial yang termotivasi untuk menggunakan kembali dataset penglihatan komputer yang sudah mapan karena beberapa alasan: mereka sudah terbukti efektif; mereka jauh lebih murah daripada ‘memulai dari awal’; dan mereka dipelihara dan diperbarui oleh pikiran dan organisasi terdepan di seluruh akademisi dan industri, pada tingkat pendanaan dan penjadwalan yang akan sulit untuk diulangi oleh perusahaan tunggal.
Selain itu, dalam banyak kasus di mana data tidak asli (tidak seperti CityScapes), gambar-gambar tersebut dikumpulkan sebelum kontroversi sekitar praktik pengumpulan dan privasi data, meninggalkan dataset yang lebih tua ini dalam semacam limbo semi-hukum yang mungkin terlihat seperti ‘pelabuhan yang aman’ dari sudut pandang perusahaan.
TnT Attacks! Universal Naturalistic Adversarial Patches Against Deep Neural Network Systems ditulis oleh Bao Gia Doan, Minhui Xue, Ehsan Abbasnejad, Damith C. Ranasinghe dari Universitas Adelaide, bersama dengan Shiqing Ma dari Departemen Ilmu Komputer di Universitas Rutgers.
Diperbarui 1st Desember 2021, 7:06am GMT+2 – corrected typo.












