AI 101
Apa itu RNNs dan LSTMs dalam Deep Learning?
Banyak kemajuan paling mengesankan dalam pemrosesan bahasa alami dan AI chatbot didorong oleh Recurrent Neural Networks (RNNs) dan Long Short-Term Memory (LSTM) networks. RNNs dan LSTMs adalah arsitektur jaringan neural khusus yang dapat memproses data sekuen, data di mana urutan kronologis penting. LSTMs pada dasarnya adalah versi yang ditingkatkan dari RNNs, yang dapat menafsirkan urutan data yang lebih panjang. Mari kita lihat bagaimana RNNs dan LSTMS terstruktur dan bagaimana mereka memungkinkan pembuatan sistem pemrosesan bahasa alami yang canggih.
Apa itu Feed-Forward Neural Networks?
Jadi sebelum kita membahas bagaimana Long Short-Term Memory (LSTM) dan Convolutional Neural Networks (CNN) bekerja, kita harus membahas format jaringan neural secara umum.
Jaringan neural dimaksudkan untuk memeriksa data dan mempelajari pola yang relevan, sehingga pola tersebut dapat diterapkan pada data lain dan data baru dapat diklasifikasikan. Jaringan neural dibagi menjadi tiga bagian: lapisan input, lapisan tersembunyi (atau beberapa lapisan tersembunyi), dan lapisan output.
Lapisan input adalah yang mengambil data ke dalam jaringan neural, sedangkan lapisan tersembunyi adalah yang mempelajari pola dalam data. Lapisan tersembunyi dalam dataset dihubungkan dengan lapisan input dan output oleh “bobot” dan “bias” yang hanya asumsi tentang bagaimana titik data terkait satu sama lain. Bobot ini disesuaikan selama pelatihan. Saat jaringan dilatih, tebakan model tentang data pelatihan (nilai output) dibandingkan dengan label pelatihan sebenarnya. Selama proses pelatihan, jaringan seharusnya (semoga) menjadi lebih akurat dalam memprediksi hubungan antara titik data, sehingga dapat mengklasifikasikan titik data baru dengan akurat. Jaringan neural yang dalam adalah jaringan yang memiliki lebih banyak lapisan di tengah/lapisan tersembunyi. Semakin banyak lapisan tersembunyi dan neuron/simpul yang dimiliki model, semakin baik model dapat mengenali pola dalam data.
Jaringan neural feed-forward biasa, seperti yang saya deskripsikan di atas, sering disebut “jaringan neural padat”. Jaringan neural padat ini digabungkan dengan arsitektur jaringan yang berbeda yang berspesialisasi dalam menafsirkan jenis data yang berbeda.
Apa itu RNNs (Recurrent Neural Networks)?

Jaringan Neural Rekuren mengambil prinsip umum jaringan neural feed-forward dan memungkinkan mereka untuk menangani data sekuen dengan memberi model memori internal. Bagian “Rekuren” dari nama RNN berasal dari fakta bahwa input dan output berulang. Setelah output jaringan dihasilkan, output disalin dan dikembalikan ke jaringan sebagai input. Saat membuat keputusan, tidak hanya input dan output saat ini yang dianalisis, tetapi juga input sebelumnya. Dengan kata lain, jika input awal untuk jaringan adalah X dan output adalah H, baik H dan X1 (input berikutnya dalam urutan data) dimasukkan ke dalam jaringan untuk putaran pelatihan berikutnya. Dengan cara ini, konteks data (input sebelumnya) dipertahankan saat jaringan dilatih.
Hasil dari arsitektur ini adalah RNNs dapat menangani data sekuen. Namun, RNNs menderita beberapa masalah. RNNs menderita masalah gradien yang menghilang dan meledak.
Panjang urutan yang dapat diinterpretasikan oleh RNN terbatas, terutama dibandingkan dengan LSTMs.
Apa itu LSTMs (Long Short-Term Memory Networks)?
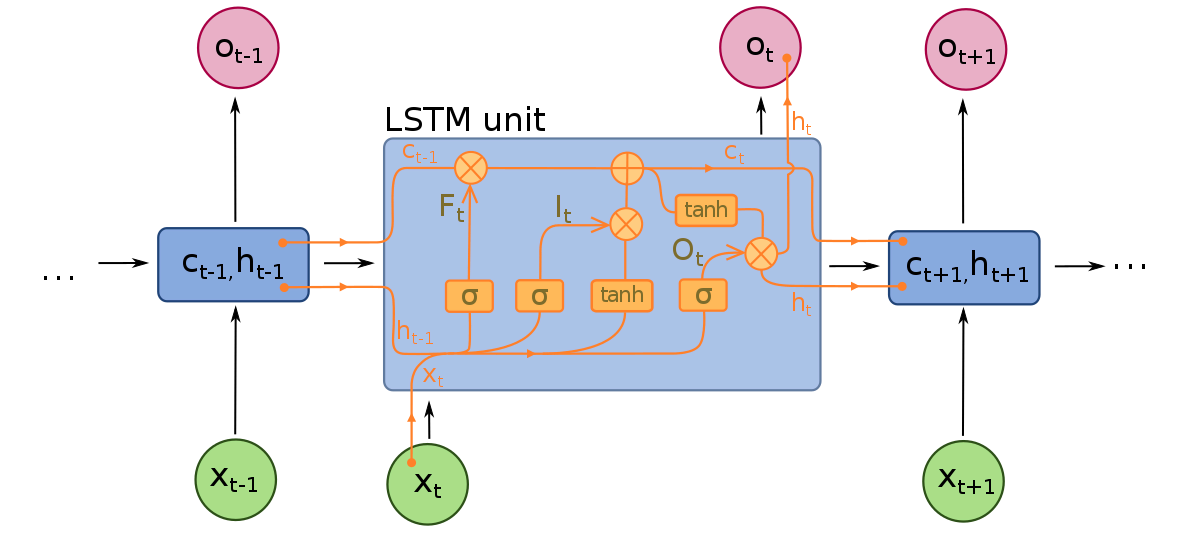
Jaringan Long Short-Term Memory dapat dianggap sebagai ekstensi dari RNNs, sekali lagi menerapkan konsep mempertahankan konteks input. Namun, LSTMs telah dimodifikasi dalam beberapa cara penting yang memungkinkan mereka untuk menafsirkan data masa lalu dengan metode yang lebih baik. Perubahan yang dilakukan pada LSTMs menangani masalah gradien yang menghilang dan memungkinkan LSTMs untuk mempertimbangkan urutan input yang lebih panjang.

Model LSTMs terdiri dari tiga komponen yang berbeda, atau gerbang. Ada gerbang input, gerbang output, dan gerbang lupa. Sama seperti RNNs, LSTMs mengambil input dari waktu sebelumnya dalam memodifikasi memori model dan bobot input. Gerbang input membuat keputusan tentang nilai mana yang penting dan harus dibiarkan melewati model. Fungsi sigmoid digunakan dalam gerbang input, yang membuat keputusan tentang nilai mana yang harus dilewati ke jaringan rekuren. Nol menjatuhkan nilai, sedangkan 1 mempertahankannya. Fungsi TanH juga digunakan di sini, yang memutuskan seberapa penting nilai input bagi model, berkisar dari -1 hingga 1.
Setelah input saat ini dan keadaan memori dihitung, gerbang output memutuskan nilai mana yang harus diteruskan ke langkah waktu berikutnya. Dalam gerbang output, nilai dianalisis dan diberi bobot kepentingan yang berkisar dari -1 hingga 1. Ini mengatur data sebelum dijalankan ke perhitungan langkah waktu berikutnya. Akhirnya, tugas gerbang lupa adalah untuk menjatuhkan informasi yang model anggap tidak perlu untuk membuat keputusan tentang sifat nilai input. Gerbang lupa menggunakan fungsi sigmoid pada nilai, menghasilkan angka antara 0 (lupa ini) dan 1 (pertahankan ini).
Jaringan neural LSTMs terdiri dari lapisan LSTMs khusus yang dapat menafsirkan data kata sekuen dan lapisan yang terhubung rapat seperti yang dijelaskan di atas. Setelah data melewati lapisan LSTMs, maka dilanjutkan ke lapisan yang terhubung rapat.








