
Kecerdasan Buatan
Optimasi Preferensi Langsung: Panduan Lengkap

Menyelaraskan model bahasa besar (LLM) dengan nilai-nilai dan preferensi kemanusiaan merupakan sebuah tantangan. Cara tradisional, seperti Pembelajaran Penguatan dari Umpan Balik Manusia (RLHF), telah membuka jalan dengan mengintegrasikan masukan manusia untuk menyempurnakan keluaran model. Namun, RLHF bisa jadi rumit dan membutuhkan banyak sumber daya, sehingga memerlukan daya komputasi dan pemrosesan data yang besar. Optimasi Preferensi Langsung (DPO) muncul sebagai pendekatan baru dan lebih sederhana, menawarkan alternatif yang efisien dibandingkan metode tradisional. Dengan menyederhanakan proses optimasi, DPO tidak hanya mengurangi beban komputasi namun juga meningkatkan kemampuan model untuk beradaptasi dengan cepat terhadap preferensi manusia.
Dalam panduan ini kita akan mendalami DPO, mengeksplorasi dasar-dasarnya, penerapannya, dan penerapan praktisnya.
Perlunya Penyelarasan Preferensi
Untuk memahami DPO, penting untuk memahami mengapa menyelaraskan LLM dengan preferensi manusia sangatlah penting. Meskipun memiliki kemampuan yang mengesankan, LLM yang dilatih pada kumpulan data yang sangat besar terkadang dapat menghasilkan keluaran yang tidak konsisten, bias, atau tidak selaras dengan nilai-nilai manusia. Ketidakselarasan ini dapat terwujud dalam berbagai cara:
- Menghasilkan konten yang tidak aman atau berbahaya
- Memberikan informasi yang tidak akurat atau menyesatkan
- Menunjukkan bias yang ada dalam data pelatihan
Untuk mengatasi masalah ini, para peneliti telah mengembangkan teknik untuk menyempurnakan LLM menggunakan umpan balik manusia. Pendekatan yang paling menonjol adalah RLHF.
Memahami RLHF: Cikal bakal DPO
Pembelajaran Penguatan dari Umpan Balik Manusia (RLHF) telah menjadi metode yang tepat untuk menyelaraskan LLM dengan preferensi manusia. Mari kita uraikan proses RLHF untuk memahami kompleksitasnya:
a) Penyempurnaan yang Diawasi (SFT): Prosesnya dimulai dengan menyempurnakan LLM terlatih pada kumpulan data respons berkualitas tinggi. Langkah ini membantu model menghasilkan keluaran yang lebih relevan dan koheren untuk tugas target.
b) Pemodelan Hadiah: Model penghargaan terpisah dilatih untuk memprediksi preferensi manusia. Ini melibatkan:
- Menghasilkan pasangan respons untuk perintah yang diberikan
- Minta manusia menilai respons mana yang mereka sukai
- Melatih model untuk memprediksi preferensi ini
c) Pembelajaran Penguatan: LLM yang telah disempurnakan kemudian dioptimalkan lebih lanjut menggunakan pembelajaran penguatan. Model penghargaan memberikan umpan balik, memandu LLM untuk menghasilkan tanggapan yang selaras dengan preferensi manusia.
Berikut pseudocode Python yang disederhanakan untuk mengilustrasikan proses RLHF:
Meskipun efektif, RLHF memiliki beberapa kelemahan:
- Hal ini memerlukan pelatihan dan pemeliharaan beberapa model (SFT, model penghargaan, dan model yang dioptimalkan RL)
- Proses RL bisa jadi tidak stabil dan sensitif terhadap hyperparameter
- Ini mahal secara komputasi, memerlukan banyak proses maju dan mundur dalam modelnya
Keterbatasan ini telah memotivasi pencarian alternatif yang lebih sederhana dan efisien, sehingga mengarah pada pengembangan DPO.
Optimasi Preferensi Langsung: Konsep Inti

Optimasi Preferensi Langsung https://arxiv.org/abs/2305.18290
Gambar ini membedakan dua pendekatan berbeda untuk menyelaraskan keluaran LLM dengan preferensi manusia: Pembelajaran Penguatan dari Umpan Balik Manusia (RLHF) dan Optimasi Preferensi Langsung (DPO). RLHF mengandalkan model penghargaan untuk memandu kebijakan model bahasa melalui putaran umpan balik berulang, sementara DPO secara langsung mengoptimalkan keluaran model agar sesuai dengan respons pilihan manusia menggunakan data preferensi. Perbandingan ini menyoroti kekuatan dan potensi penerapan masing-masing metode, memberikan wawasan tentang bagaimana LLM masa depan dapat dilatih agar lebih selaras dengan harapan manusia.
Ide-ide kunci di balik DPO:
a) Pemodelan Imbalan Implisit: DPO menghilangkan kebutuhan akan model penghargaan terpisah dengan memperlakukan model bahasa itu sendiri sebagai fungsi penghargaan implisit.
b) Formulasi Berbasis Kebijakan: Daripada mengoptimalkan fungsi penghargaan, DPO secara langsung mengoptimalkan kebijakan (model bahasa) untuk memaksimalkan kemungkinan respons yang diinginkan.
c) Solusi Bentuk Tertutup: DPO memanfaatkan wawasan matematis yang memungkinkan solusi bentuk tertutup untuk kebijakan optimal, sehingga menghindari perlunya pembaruan RL yang berulang.
Menerapkan DPO: Panduan Kode Praktis
Gambar di bawah menampilkan cuplikan kode yang mengimplementasikan fungsi kerugian DPO menggunakan PyTorch. Fungsi ini memainkan peran penting dalam menyempurnakan cara model bahasa memprioritaskan keluaran berdasarkan preferensi manusia. Berikut rincian komponen utama:
- Tanda Tangan Fungsi: Para
dpo_lossfungsi mengambil beberapa parameter termasuk probabilitas log kebijakan (pi_logps), probabilitas log model referensi (ref_logps), dan indeks yang mewakili penyelesaian yang disukai dan tidak disukai (yw_idxs,yl_idxs). Selain itu, abetaparameter mengontrol kekuatan penalti KL. - Ekstraksi Probabilitas Log: Kode mengekstrak probabilitas log untuk penyelesaian yang disukai dan tidak disukai dari model kebijakan dan referensi.
- Perhitungan Rasio Log: Perbedaan antara probabilitas log untuk penyelesaian yang disukai dan tidak disukai dihitung untuk model kebijakan dan referensi. Rasio ini sangat penting dalam menentukan arah dan besarnya optimasi.
- Perhitungan Kerugian dan Imbalan: Kerugian dihitung menggunakan
logsigmoidfungsi, sedangkan imbalan ditentukan dengan menskalakan perbedaan antara probabilitas log kebijakan dan referensi sebesarbeta.

Fungsi kehilangan DPO menggunakan PyTorch
Mari selami matematika di balik DPO untuk memahami bagaimana DPO mencapai tujuan tersebut.
Matematika DPO
DPO adalah reformulasi cerdas dari masalah preferensi pembelajaran. Berikut rincian langkah demi langkah:
a) Titik Awal: Maksimalisasi Hadiah yang Dibatasi KL
Tujuan awal RLHF dapat dinyatakan sebagai:
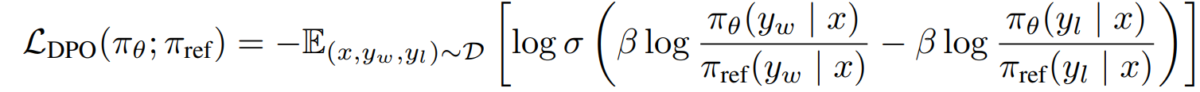
- πθ adalah kebijakan (model bahasa) yang kami optimalkan
- r(x,y) adalah fungsi imbalan
- πref adalah kebijakan referensi (biasanya model SFT awal)
- β mengontrol kekuatan batasan divergensi KL
b) Bentuk Kebijakan Optimal: Dapat ditunjukkan bahwa kebijakan optimal untuk tujuan tersebut berbentuk:
π_r(y|x) = 1/Z(x) * πref(y|x) * exp(1/β * r(x,y))Dimana Z(x) adalah konstanta normalisasi.
c) Dualitas Kebijakan-Imbalan: Wawasan utama DPO adalah untuk mengekspresikan fungsi penghargaan dalam bentuk kebijakan yang optimal:
r(x,y) = β * log(π_r(y|x) / πref(y|x)) + β * log(Z(x))d) Model Preferensi Dengan asumsi preferensi mengikuti model Bradley-Terry, kita dapat menyatakan probabilitas memilih y1 daripada y2 sebagai:
p*(y1 ≻ y2 | x) = σ(r*(x,y1) - r*(x,y2))Dimana σ adalah fungsi logistik.
e) Tujuan DPO Dengan mengganti dualitas kebijakan imbalan ke dalam model preferensi, kita sampai pada tujuan DPO:
L_DPO(πθ; πref) = -E_(x,y_w,y_l)~D [log σ(β * log(πθ(y_w|x) / πref(y_w|x)) - β * log(πθ(y_l|x) / πref(y_l|x)))]Tujuan ini dapat dioptimalkan menggunakan teknik penurunan gradien standar, tanpa memerlukan algoritma RL.
Pelaksana DPO
Sekarang setelah kita memahami teori di balik DPO, mari kita lihat bagaimana menerapkannya dalam praktik. Kami akan menggunakan Ular sanca dan PyTorch untuk contoh ini:
import torch
import torch.nn.functional as F
class DPOTrainer:
def __init__(self, model, ref_model, beta=0.1, lr=1e-5):
self.model = model
self.ref_model = ref_model
self.beta = beta
self.optimizer = torch.optim.AdamW(self.model.parameters(), lr=lr)
def compute_loss(self, pi_logps, ref_logps, yw_idxs, yl_idxs):
"""
pi_logps: policy logprobs, shape (B,)
ref_logps: reference model logprobs, shape (B,)
yw_idxs: preferred completion indices in [0, B-1], shape (T,)
yl_idxs: dispreferred completion indices in [0, B-1], shape (T,)
beta: temperature controlling strength of KL penalty
Each pair of (yw_idxs[i], yl_idxs[i]) represents the indices of a single preference pair.
"""
# Extract log probabilities for the preferred and dispreferred completions
pi_yw_logps, pi_yl_logps = pi_logps[yw_idxs], pi_logps[yl_idxs]
ref_yw_logps, ref_yl_logps = ref_logps[yw_idxs], ref_logps[yl_idxs]
# Calculate log-ratios
pi_logratios = pi_yw_logps - pi_yl_logps
ref_logratios = ref_yw_logps - ref_yl_logps
# Compute DPO loss
losses = -F.logsigmoid(self.beta * (pi_logratios - ref_logratios))
rewards = self.beta * (pi_logps - ref_logps).detach()
return losses.mean(), rewards
def train_step(self, batch):
x, yw_idxs, yl_idxs = batch
self.optimizer.zero_grad()
# Compute log probabilities for the model and the reference model
pi_logps = self.model(x).log_softmax(-1)
ref_logps = self.ref_model(x).log_softmax(-1)
# Compute the loss
loss, _ = self.compute_loss(pi_logps, ref_logps, yw_idxs, yl_idxs)
loss.backward()
self.optimizer.step()
return loss.item()
# Usage
model = YourLanguageModel() # Initialize your model
ref_model = YourLanguageModel() # Load pre-trained reference model
trainer = DPOTrainer(model, ref_model)
for batch in dataloader:
loss = trainer.train_step(batch)
print(f"Loss: {loss}")
Tantangan dan Arah Masa Depan
Meskipun DPO menawarkan keuntungan yang signifikan dibandingkan pendekatan RLHF tradisional, masih terdapat tantangan dan area yang perlu dilakukan penelitian lebih lanjut:
a) Skalabilitas ke Model yang Lebih Besar:
Seiring dengan bertambahnya ukuran model bahasa, penerapan DPO secara efisien pada model dengan ratusan miliar parameter tetap menjadi tantangan terbuka. Para peneliti sedang mengeksplorasi teknik seperti:
- Metode penyesuaian yang efisien (misalnya, LoRA, penyetelan awalan)
- Optimalisasi pelatihan terdistribusi
- Pos pemeriksaan gradien dan pelatihan presisi campuran
Contoh penggunaan LoRA dengan DPO:
from peft import LoraConfig, get_peft_model
class DPOTrainerWithLoRA(DPOTrainer):
def __init__(self, model, ref_model, beta=0.1, lr=1e-5, lora_rank=8):
lora_config = LoraConfig(
r=lora_rank,
lora_alpha=32,
target_modules=["q_proj", "v_proj"],
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM"
)
self.model = get_peft_model(model, lora_config)
self.ref_model = ref_model
self.beta = beta
self.optimizer = torch.optim.AdamW(self.model.parameters(), lr=lr)
# Usage
base_model = YourLargeLanguageModel()
dpo_trainer = DPOTrainerWithLoRA(base_model, ref_model)
b) Adaptasi Multi-Tugas dan Sedikit Pemotretan:
Mengembangkan teknik DPO yang dapat beradaptasi secara efisien terhadap tugas atau domain baru dengan data preferensi terbatas merupakan bidang penelitian yang aktif. Pendekatan yang sedang dieksplorasi meliputi:
- Kerangka kerja meta-learning untuk adaptasi cepat
- Penyempurnaan berbasis cepat untuk DPO
- Transfer pembelajaran dari model preferensi umum ke domain tertentu
c) Menangani Preferensi yang Ambigu atau Bertentangan:
Data preferensi dunia nyata sering kali mengandung ambiguitas atau konflik. Meningkatkan ketahanan DPO terhadap data tersebut sangatlah penting. Solusi potensial meliputi:
- Pemodelan preferensi probabilistik
- Pembelajaran aktif untuk menyelesaikan ambiguitas
- Agregasi preferensi multi-agen
Contoh pemodelan preferensi probabilistik:
class ProbabilisticDPOTrainer(DPOTrainer):
def compute_loss(self, pi_logps, ref_logps, yw_idxs, yl_idxs, preference_prob):
# Compute log ratios
pi_yw_logps, pi_yl_logps = pi_logps[yw_idxs], pi_logps[yl_idxs]
ref_yw_logps, ref_yl_logps = ref_logps[yw_idxs], ref_logps[yl_idxs]
log_ratio_diff = pi_yw_logps.sum(-1) - pi_yl_logps.sum(-1)
loss = -(preference_prob * F.logsigmoid(self.beta * log_ratio_diff) +
(1 - preference_prob) * F.logsigmoid(-self.beta * log_ratio_diff))
return loss.mean()
# Usage
trainer = ProbabilisticDPOTrainer(model, ref_model)
loss = trainer.compute_loss(pi_logps, ref_logps, yw_idxs, yl_idxs, preference_prob=0.8) # 80% confidence in preference
d) Menggabungkan DPO dengan Teknik Alignment Lainnya:
Mengintegrasikan DPO dengan pendekatan penyelarasan lainnya dapat menghasilkan sistem yang lebih kuat dan mampu:
- Prinsip AI konstitusional untuk kepuasan batasan eksplisit
- Perdebatan dan pemodelan penghargaan rekursif untuk perolehan preferensi yang kompleks
- Pembelajaran penguatan terbalik untuk menyimpulkan fungsi penghargaan yang mendasarinya
Contoh penggabungan DPO dengan AI konstitusional:
class ConstitutionalDPOTrainer(DPOTrainer):
def __init__(self, model, ref_model, beta=0.1, lr=1e-5, constraints=None):
super().__init__(model, ref_model, beta, lr)
self.constraints = constraints or []
def compute_loss(self, pi_logps, ref_logps, yw_idxs, yl_idxs):
base_loss = super().compute_loss(pi_logps, ref_logps, yw_idxs, yl_idxs)
constraint_loss = 0
for constraint in self.constraints:
constraint_loss += constraint(self.model, pi_logps, ref_logps, yw_idxs, yl_idxs)
return base_loss + constraint_loss
# Usage
def safety_constraint(model, pi_logps, ref_logps, yw_idxs, yl_idxs):
# Implement safety checking logic
unsafe_score = compute_unsafe_score(model, pi_logps, ref_logps)
return torch.relu(unsafe_score - 0.5) # Penalize if unsafe score > 0.5
constraints = [safety_constraint]
trainer = ConstitutionalDPOTrainer(model, ref_model, constraints=constraints)
Pertimbangan Praktis dan Praktik Terbaik
Saat menerapkan DPO untuk aplikasi dunia nyata, pertimbangkan tips berikut:
a) Kualitas Data: Kualitas data preferensi Anda sangat penting. Pastikan kumpulan data Anda:
- Mencakup beragam masukan dan perilaku yang diinginkan
- Memiliki anotasi preferensi yang konsisten dan andal
- Menyeimbangkan berbagai jenis preferensi (misalnya, faktualitas, keamanan, gaya)
b) Penyesuaian Hyperparameter: Meskipun DPO memiliki hyperparameter lebih sedikit dibandingkan RLHF, penyetelan tetap penting:
- β (beta): Mengontrol trade-off antara kepuasan preferensi dan perbedaan dari model referensi. Mulailah dengan nilai-nilai di sekitar 0.1-0.5.
- Kecepatan pembelajaran: Gunakan kecepatan pembelajaran yang lebih rendah daripada penyesuaian standar, biasanya dalam kisaran 1e-6 hingga 1e-5.
- Ukuran batch: Ukuran batch lebih besar (32-128) sering kali berfungsi dengan baik untuk pembelajaran preferensi.
c) Penyempurnaan Iteratif: DPO dapat diterapkan secara iteratif:
- Latih model awal menggunakan DPO
- Hasilkan respons baru menggunakan model terlatih
- Kumpulkan data preferensi baru mengenai tanggapan ini
- Latih kembali menggunakan kumpulan data yang diperluas

Kinerja Optimasi Preferensi Langsung
Gambar ini menunjukkan kinerja LLM seperti GPT-4 dibandingkan dengan penilaian manusia di berbagai teknik pelatihan, termasuk Direct Preference Optimization (DPO), Supervised Fine-Tuning (SFT), dan Proximal Policy Optimization (PPO). Tabel tersebut mengungkapkan bahwa keluaran GPT-4 semakin selaras dengan preferensi manusia, terutama dalam tugas-tugas ringkasan. Tingkat kesesuaian antara GPT-4 dan pengulas manusia menunjukkan kemampuan model untuk menghasilkan konten yang sesuai dengan evaluator manusia, hampir sedekat konten yang dihasilkan manusia.
Studi Kasus dan Aplikasi
Untuk mengilustrasikan efektivitas DPO, mari kita lihat beberapa aplikasi dunia nyata dan beberapa variannya:
- DPO berulang: Dikembangkan oleh Snorkel (2023), varian ini menggabungkan pengambilan sampel penolakan dengan DPO, memungkinkan proses seleksi yang lebih baik untuk data pelatihan. Dengan melakukan iterasi pada beberapa putaran pengambilan sampel preferensi, model akan lebih mampu menggeneralisasi dan menghindari penyesuaian yang berlebihan terhadap preferensi yang berisik atau bias.
- penawaran umum perdana (Optimasi Preferensi Iteratif): Diperkenalkan oleh Azar dkk. (2023), IPO menambahkan istilah regularisasi untuk mencegah overfitting, yang merupakan masalah umum dalam optimasi berbasis preferensi. Ekstensi ini memungkinkan model menjaga keseimbangan antara mengikuti preferensi dan mempertahankan kemampuan generalisasi.
- KTO (Optimasi Transfer Pengetahuan): Varian yang lebih baru dari Ethayarajh dkk. (2023), KTO meniadakan preferensi biner sama sekali. Sebaliknya, pendekatan ini berfokus pada transfer pengetahuan dari model referensi ke model kebijakan, mengoptimalkan keselarasan dengan nilai-nilai kemanusiaan yang lebih lancar dan konsisten.
- DPO Multi-Modal untuk Pembelajaran Lintas Domain oleh Xu dkk. (2024): Suatu pendekatan yang menerapkan DPO di berbagai modalitas—teks, gambar, dan audio—yang menunjukkan keserbagunaannya dalam menyelaraskan model dengan preferensi manusia di berbagai jenis data. Penelitian ini menyoroti potensi DPO dalam menciptakan sistem AI yang lebih komprehensif yang mampu menangani tugas-tugas multimodal yang kompleks.











