Kecerdasan buatan
AudioSep : Pisahkan Apa Pun yang Anda Deskripsikan
LASS atau Language-queried Audio Source Separation adalah paradigma baru untuk CASA atau Computational Auditory Scene Analysis yang bertujuan untuk memisahkan suara target dari campuran audio menggunakan kueri bahasa alami yang menyediakan antarmuka yang alami namun scalable untuk tugas dan aplikasi audio digital. Meskipun kerangka kerja LASS telah maju secara signifikan dalam beberapa tahun terakhir dalam hal mencapai kinerja yang diinginkan pada sumber audio tertentu seperti instrumen musik, mereka tidak dapat memisahkan audio target di domain terbuka.
AudioSep, adalah model dasar yang bertujuan untuk memecahkan keterbatasan kerangka kerja LASS saat ini dengan memungkinkan pemisahan audio target menggunakan kueri bahasa alami. Pengembang kerangka kerja AudioSep telah melatih model secara ekstensif pada berbagai dataset multimodal skala besar, dan telah mengevaluasi kinerja kerangka kerja pada berbagai tugas audio termasuk pemisahan instrumen musik, pemisahan peristiwa audio, dan meningkatkan ucapan di antara banyak lainnya. Kinerja awal AudioSep memuaskan benchmark karena menunjukkan kemampuan pembelajaran zero-shot yang mengesankan dan menghasilkan kinerja pemisahan audio yang kuat.
Dalam artikel ini, kita akan melakukan penyelaman lebih dalam pada kerja kerangka kerja AudioSep karena kita akan mengevaluasi arsitektur model, dataset yang digunakan untuk pelatihan dan evaluasi, dan konsep-konsep penting yang terlibat dalam kerja model AudioSep. Jadi mari kita mulai dengan pengenalan dasar tentang kerangka kerja CASA.
CASA, USS, QSS, LASS Frameworks : Dasar untuk AudioSep
CASA atau Computational Auditory Scene Analysis framework adalah kerangka kerja yang digunakan oleh pengembang untuk merancang sistem pendengaran mesin yang memiliki kemampuan untuk memahami lingkungan suara yang kompleks dengan cara yang sama seperti manusia memahami suara menggunakan sistem auditori mereka. Pemisahan suara, dengan fokus khusus pada pemisahan suara target, adalah area penelitian fundamental dalam kerangka kerja CASA, dan bertujuan untuk memecahkan “masalah pesta koki” atau memisahkan rekaman audio dunia nyata dari rekaman sumber audio individu atau file. Pentingnya pemisahan suara dapat dikaitkan terutama dengan aplikasi yang luas termasuk pemisahan sumber musik, pemisahan sumber audio, peningkatan ucapan, identifikasi suara target, dan banyak lagi.
Sebagian besar pekerjaan pada pemisahan suara yang dilakukan di masa lalu berputar terutama autour pemisahan satu atau lebih sumber audio seperti pemisahan musik atau pemisahan ucapan. Sebuah model baru dengan nama USS atau Universal Sound Separation bertujuan untuk memisahkan suara arbitrer dalam rekaman audio dunia nyata. Namun, ini adalah tugas yang menantang dan terbatas untuk memisahkan setiap sumber suara dari campuran audio terutama karena berbagai sumber suara yang ada di dunia yang merupakan alasan utama mengapa metode USS tidak layak untuk aplikasi dunia nyata yang bekerja dalam waktu nyata.
Alternatif yang layak untuk metode USS adalah QSS atau Query-based Sound Separation method yang bertujuan untuk memisahkan sumber suara target individu dari campuran audio berdasarkan pada set kueri tertentu. Berkat ini, kerangka kerja QSS memungkinkan pengembang dan pengguna untuk mengekstrak sumber audio yang diinginkan dari campuran berdasarkan kebutuhan mereka yang membuat metode QSS menjadi solusi yang lebih praktis untuk aplikasi digital dunia nyata seperti pengeditan konten multimedia atau pengeditan audio.
Selanjutnya, pengembang telah mengusulkan ekstensi dari kerangka kerja QSS, yaitu LASS framework atau Language-queried Audio Source Separation framework yang bertujuan untuk memisahkan sumber suara arbitrer dari campuran audio dengan menggunakan deskripsi bahasa alami dari sumber suara target. Karena kerangka kerja LASS memungkinkan pengguna untuk mengekstrak sumber suara target menggunakan himpunan instruksi bahasa alami, ini mungkin menjadi alat yang kuat dengan aplikasi yang luas dalam aplikasi audio digital. Ketika dibandingkan dengan metode kueri audio atau kueri visi tradisional, menggunakan instruksi bahasa alami untuk pemisahan audio menawarkan derajat keunggulan yang lebih besar karena menambahkan fleksibilitas, dan membuat akuisisi informasi kueri lebih mudah dan nyaman. Selain itu, ketika dibandingkan dengan kerangka kerja pemisahan audio berbasis label kueri yang menggunakan himpunan instruksi atau kueri yang telah ditentukan sebelumnya, kerangka kerja LASS tidak membatasi jumlah kueri input, dan memiliki fleksibilitas untuk digeneralisasi ke domain terbuka dengan mulus.
Awalnya, kerangka kerja LASS bergantung pada pembelajaran terawasi di mana model dilatih pada himpunan data audio-teks yang dilabeli. Namun, masalah utama dengan pendekatan ini adalah ketersediaan terbatas dari data audio-teks yang dilabeli dan dianotasi. Untuk mengurangi ketergantungan kerangka kerja LASS pada data audio-teks yang dilabeli, model-model dilatih menggunakan pendekatan pembelajaran supervisi multimodal. Tujuan utama di balik menggunakan pendekatan supervisi multimodal adalah untuk menggunakan model pra-pelatihan kontras multimodal seperti model CLIP atau Contrastive Language Image Pre Training sebagai pengkode kueri untuk kerangka kerja. Karena kerangka kerja CLIP memiliki kemampuan untuk menyelaraskan penyematan teks dengan modalitas lain seperti audio atau visi, ini memungkinkan pengembang untuk melatih model LASS menggunakan data kaya modalitas, dan memungkinkan interferensi dengan data teks dalam pengaturan zero-shot. Kerangka kerja LASS saat ini menggunakan dataset skala kecil untuk pelatihan, dan aplikasi kerangka kerja LASS di ratusan domain potensial belum dieksplorasi.
Untuk memecahkan keterbatasan kerangka kerja LASS saat ini, pengembang telah memperkenalkan AudioSep, model dasar yang bertujuan untuk memisahkan suara dari campuran audio menggunakan deskripsi bahasa alami. Fokus saat ini untuk AudioSep adalah untuk mengembangkan model pemisahan suara pra-pelatihan yang memanfaatkan dataset multimodal skala besar yang ada untuk memungkinkan generalisasi model LASS dalam aplikasi domain terbuka. Untuk merangkum, model AudioSep adalah : “Model dasar untuk pemisahan suara universal di domain terbuka menggunakan kueri bahasa alami atau deskripsi yang dilatih pada dataset audio dan multimodal skala besar”.
AudioSep : Komponen Kunci & Arsitektur
Arsitektur kerangka kerja AudioSep terdiri dari dua komponen kunci: pengkode teks, dan model pemisahan.
Pengkode Teks
Kerangka kerja AudioSep menggunakan pengkode teks dari model CLIP atau Contrastive Language Image Pre Training atau model CLAP atau Contrastive Language Audio Pre Training untuk mengekstrak penyematan teks dalam kueri bahasa alami. Kueri teks input terdiri dari urutan “N” token yang kemudian diproses oleh pengkode teks untuk mengekstrak penyematan teks untuk kueri bahasa input. Pengkode teks menggunakan tumpukan blok transformer untuk mengkodekan token teks input, dan representasi output diagregasi setelah mereka melewati lapisan transformer yang menghasilkan pengembangan representasi vektor dengan panjang tetap di mana D sesuai dengan dimensi model CLAP atau CLIP sementara pengkode teks dibekukan selama periode pelatihan.
Model CLIP dipra-pelatih pada dataset skala besar dari data pasangan gambar-teks menggunakan pembelajaran kontras yang merupakan alasan utama mengapa pengkode teksnya belajar memetakan deskripsi teks pada ruang semantik yang juga dibagikan oleh representasi visual. Keuntungan yang diperoleh AudioSep dengan menggunakan pengkode teks CLIP adalah bahwa sekarang dapat diskalakan atau dilatih model LASS dari data audio-visual yang tidak dilabeli menggunakan penyematan visual sebagai alternatif, sehingga memungkinkan pelatihan model LASS tanpa kebutuhan data audio-teks yang dilabeli.
Model CLAP bekerja serupa dengan model CLIP dan menggunakan tujuan pembelajaran kontras serta menggunakan pengkode teks dan pengkode audio untuk menghubungkan audio dan bahasa, sehingga membawa deskripsi teks dan audio ke ruang laten audio-teks yang digabungkan.
Model Pemisahan
Kerangka kerja AudioSep menggunakan model ResUNet domain-frekuensi yang diberi campuran klip audio sebagai tulang punggung pemisahan untuk kerangka kerja. Kerangka kerja bekerja dengan menerapkan STFT atau Short-Time Fourier Transform pada sinyal gelombang untuk mengekstrak spektrogram kompleks, spektrogram magnitudo, dan Fase X. Model kemudian mengikuti pengaturan yang sama dan membangun jaringan pengkode-dekode untuk memproses spektrogram magnitudo.
Jaringan pengkode-dekode ResUNet terdiri dari 6 blok residu, 6 blok dekoder, dan 4 blok leher botol. Spektrogram di setiap blok pengkode menggunakan 4 blok konvolusi residu untuk mensampling ke dalam fitur leher botol sementara blok dekoder menggunakan 4 blok dekonvolusi residu untuk mendapatkan komponen pemisahan dengan mensampling fitur. Setelah itu, setiap blok pengkode dan blok dekoder yang sesuai membentuk koneksi skip yang beroperasi pada tingkat upsampling atau downsampling yang sama. Blok residu kerangka kerja terdiri dari 2 lapisan aktivasi Leaky-ReLU, 2 lapisan normalisasi batch, dan 2 lapisan CNN, dan lebih lanjut, kerangka kerja juga memperkenalkan jalan pintas residu tambahan yang menghubungkan input dan output setiap blok residu individu. Model ResUNet mengambil spektrogram kompleks X sebagai input, dan menghasilkan masker magnitudo M sebagai output dengan residu fase yang dikondisikan pada penyematan teks yang mengontrol magnitudo skala dan rotasi sudut spektrogram. Spektrogram kompleks yang dipisahkan dapat kemudian diekstrak dengan mengalikan masker magnitudo yang diprediksi dan residu fase dengan STFT (Short-Time Fourier Transform) dari campuran.

Dalam kerangka kerjanya, AudioSep menggunakan lapisan FiLm atau Feature-wise Linearly modulated untuk menghubungkan model pemisahan dan pengkode teks setelah penerapan blok konvolusi dalam ResUNet.
Pelatihan dan Kerugian
Selama pelatihan model AudioSep, pengembang menggunakan metode augmentasi kekerasan, dan melatih kerangka kerja AudioSep dari ujung ke ujung dengan menggunakan fungsi kerugian L1 antara gelombang yang sebenarnya dan yang diprediksi.
Dataset dan Benchmark
Seperti disebutkan dalam bagian sebelumnya, AudioSep adalah model dasar yang bertujuan untuk memecahkan ketergantungan model LASS saat ini pada dataset audio-teks yang dilabeli. Model AudioSep dilatih pada berbagai dataset untuk memberinya kemampuan pembelajaran multimodal, dan berikut adalah deskripsi rinci tentang dataset dan benchmark yang digunakan oleh pengembang untuk melatih kerangka kerja AudioSep.
AudioSet
AudioSet adalah dataset audio skala besar yang lemah yang terdiri dari lebih dari 2 juta potongan audio 10 detik yang diekstrak langsung dari YouTube. Setiap potongan audio dalam dataset AudioSet dikategorikan oleh kehadiran atau ketidakhadiran kelas suara tanpa detail waktu khusus dari peristiwa suara. Dataset AudioSet memiliki lebih dari 500 kelas suara yang berbeda termasuk suara alami, suara manusia, suara kendaraan, dan banyak lagi.
VGGSound
Dataset VGGSound adalah dataset visual-audio skala besar yang seperti AudioSet telah diambil langsung dari YouTube, dan berisi lebih dari 200.000 klip video, masing-masing dengan panjang 10 detik. Dataset VGGSound dikategorikan ke dalam lebih dari 300 kelas suara termasuk suara manusia, suara alami, suara burung, dan banyak lagi. Penggunaan dataset VGGSound memastikan bahwa objek yang bertanggung jawab untuk menghasilkan suara target juga dapat digambarkan dalam klip visual yang sesuai.
AudioCaps
AudioCaps adalah dataset penjelasan audio terbesar yang tersedia secara publik, dan terdiri dari lebih dari 50.000 klip audio 10 detik yang diekstrak dari dataset AudioSet. Data dalam AudioCaps dibagi menjadi tiga kategori: data pelatihan, data pengujian, dan data validasi, dan klip audio dianotasi dengan deskripsi bahasa alami menggunakan platform Amazon Mechanical Turk. Perlu diingat bahwa setiap klip audio dalam dataset pelatihan memiliki satu kapsul, sedangkan data dalam set pengujian dan validasi masing-masing memiliki 5 kapsul yang sebenarnya.
ClothoV2
ClothoV2 adalah dataset penjelasan audio yang terdiri dari klip yang diambil dari platform FreeSound, dan seperti AudioCaps, setiap klip audio dianotasi dengan deskripsi bahasa alami menggunakan platform Amazon Mechanical Turk.
WavCaps
Seperti AudioSet, WavCaps adalah dataset audio skala besar yang lemah yang terdiri dari lebih dari 400.000 klip audio dengan kapsul, dan waktu runtime total yang mendekati 7568 jam data pelatihan. Klip audio dalam dataset WavCaps diambil dari berbagai sumber audio termasuk BBC Sound Effects, AudioSet, FreeSound, SoundBible, dan banyak lagi.

Detail Pelatihan
Selama fase pelatihan, model AudioSep secara acak memilih dua segmen audio dari dua klip audio yang berbeda dari dataset pelatihan, dan kemudian mencampurkannya untuk membuat campuran pelatihan di mana panjang setiap segmen audio sekitar 5 detik. Model kemudian mengekstrak spektrogram kompleks dari sinyal gelombang menggunakan jendela Hann dengan ukuran 1024 dengan ukuran hop 320.
Model kemudian menggunakan pengkode teks dari model CLIP/CLAP untuk mengekstrak penyematan teks dengan pengawasan teks sebagai konfigurasi default untuk AudioSep. Untuk model pemisahan, kerangka kerja AudioSep menggunakan lapisan ResUNet yang terdiri dari 30 lapisan, 6 blok pengkode, dan 6 blok dekoder yang menyerupai arsitektur yang diikuti dalam pemisahan suara universal. Selain itu, setiap blok pengkode memiliki dua lapisan konvolusi dengan ukuran kernel 3×3 dengan jumlah peta fitur output blok pengkode menjadi 32, 64, 128, 256, 512, dan 1024 secara berturut-turut. Blok dekoder berbagi simetri dengan blok pengkode, dan pengembang menerapkan optimizer Adam untuk melatih model AudioSep dengan ukuran batch 96.
Hasil Evaluasi
Pada Dataset yang Terlihat
Gambar berikut membandingkan kinerja kerangka kerja AudioSep pada dataset yang terlihat selama fase pelatihan termasuk dataset pelatihan. Gambar berikut mewakili hasil evaluasi benchmark dari kerangka kerja AudioSep ketika dibandingkan dengan sistem baseline termasuk model Peningkatan Ucapan, LASS, dan CLIP. Model AudioSep dengan pengkode teks CLIP ditandai sebagai AudioSep-CLIP, sedangkan model AudioSep dengan pengkode teks CLAP ditandai sebagai AudioSep-CLAP.

Seperti yang dapat dilihat dalam gambar, kerangka kerja AudioSep bekerja dengan baik ketika menggunakan kapsul audio atau label teks sebagai kueri input, dan hasilnya menunjukkan kinerja unggul dari kerangka kerja AudioSep ketika dibandingkan dengan model pemisahan suara LASS dan audio-kueri sebelumnya.
Pada Dataset yang Tidak Terlihat
Untuk menilai kinerja AudioSep dalam pengaturan zero-shot, pengembang terus mengevaluasi kinerja pada dataset yang tidak terlihat, dan kerangka kerja AudioSep menghasilkan kinerja pemisahan yang mengesankan dalam pengaturan zero-shot, dan hasilnya ditampilkan dalam gambar berikut.

Selanjutnya, gambar berikut menunjukkan hasil evaluasi model AudioSep melawan peningkatan ucapan Voicebank-Demand.

Evaluasi kerangka kerja AudioSep menunjukkan kinerja yang kuat dan diinginkan pada dataset yang tidak terlihat dalam pengaturan zero-shot, dan sehingga membuka jalan untuk melakukan tugas operasi suara pada distribusi data baru.
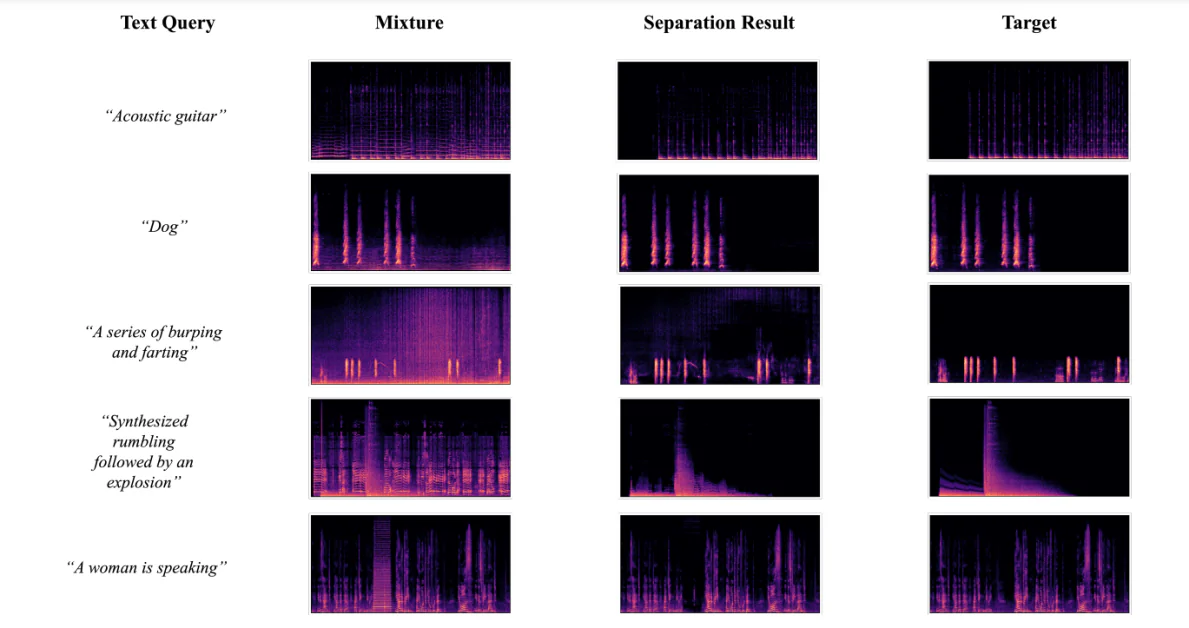
Visualisasi Hasil Pemisahan
Gambar berikut menunjukkan hasil yang diperoleh ketika pengembang menggunakan kerangka kerja AudioSep-CLAP untuk melakukan visualisasi spektrogram untuk sumber suara target sebenarnya, campuran audio, dan sumber audio yang dipisahkan menggunakan kueri teks dari berbagai audio atau suara. Hasilnya memungkinkan pengembang untuk mengamati bahwa pola sumber spektrogram yang dipisahkan dekat dengan sumber sebenarnya yang lebih lanjut mendukung hasil objektif yang diperoleh selama eksperimen.
Perbandingan Kueri Teks
Pengembang mengevaluasi kinerja AudioSep-CLAP dan AudioSep-CLIP pada AudioCaps Mini, dan pengembang menggunakan label acara AudioSet, kapsul AudioCaps, dan deskripsi bahasa alami yang dianotasi ulang untuk mengeksaminasi efek dari kueri yang berbeda, dan gambar berikut menunjukkan contoh AudioCaps Mini dalam aksi.

Kesimpulan
AudioSep adalah model dasar yang dikembangkan dengan tujuan menjadi kerangka kerja pemisahan suara universal domain terbuka yang menggunakan deskripsi bahasa alami untuk pemisahan audio. Seperti yang diamati selama evaluasi, kerangka kerja AudioSep dapat melakukan pembelajaran zero-shot dan tidak terawasi dengan mulus dengan menggunakan kapsul audio atau label teks sebagai kueri. Hasil dan kinerja evaluasi AudioSep menunjukkan kinerja yang kuat yang mengungguli kerangka kerja pemisahan suara saat ini seperti LASS, dan mungkin dapat memecahkan keterbatasan kerangka kerja pemisahan suara yang populer.












