AI 101
आरएनएन और एलएसटीएम क्या हैं डीप लर्निंग में?
प्राकृतिक भाषा प्रसंस्करण और एआई चैटबॉट्स में कई सबसे प्रभावशाली प्रगति रिकरेंट न्यूरल नेटवर्क (आरएनएन) और लॉन्ग शॉर्ट-टर्म मेमोरी (एलएसटीएम) नेटवर्क द्वारा संचालित हैं। आरएनएन और एलएसटीएम विशेष न्यूरल नेटवर्क आर्किटेक्चर हैं जो क्रमिक डेटा को संसाधित करने में सक्षम हैं, डेटा जहां कालानुक्रमिक क्रम मायने रखता है। एलएसटीएम मूल रूप से आरएनएन के सुधारित संस्करण हैं, जो डेटा की लंबी क्रमों की व्याख्या करने में सक्षम हैं। आइए देखें कि आरएनएन और एलएसटीएम कैसे संरचित हैं और वे जटिल प्राकृतिक भाषा प्रसंस्करण प्रणालियों के निर्माण को कैसे सक्षम बनाते हैं।
फीड-फॉरवर्ड न्यूरल नेटवर्क क्या हैं?
तो हम लॉन्ग शॉर्ट-टर्म मेमोरी (एलएसटीएम) और कोनवोल्यूशनल न्यूरल नेटवर्क (सीएनएन) के काम करने के तरीके के बारे में बात करने से पहले, हमें एक न्यूरल नेटवर्क के सामान्य प्रारूप पर चर्चा करनी चाहिए।
एक न्यूरल नेटवर्क डेटा की जांच करने और प्रासंगिक पैटर्न सीखने के लिए है, ताकि इन पैटर्न को अन्य डेटा पर लागू किया जा सके और नए डेटा को वर्गीकृत किया जा सके। न्यूरल नेटवर्क तीन खंडों में विभाजित होते हैं: एक इनपुट लेयर, एक हिडन लेयर (या कई हिडन लेयर), और एक आउटपुट लेयर।
इनपुट लेयर वह है जो न्यूरल नेटवर्क में डेटा को लेती है, जबकि हिडन लेयर वे हैं जो डेटा में पैटर्न सीखते हैं। डेटासेट में हिडन लेयर इनपुट और आउटपुट लेयर के साथ “वजन” और “पूर्वाग्रह” द्वारा जुड़ी होती हैं, जो कि डेटा बिंदुओं के बीच संबंधों के बारे में धारणाएं हैं। ये वजन प्रशिक्षण के दौरान समायोजित किए जाते हैं। जैसे ही नेटवर्क प्रशिक्षित होता है, मॉडल के अनुमान (आउटपुट मान) की तुलना वास्तविक प्रशिक्षण लेबल के साथ की जाती है। प्रशिक्षण के दौरान, नेटवर्क को डेटा बिंदुओं के बीच संबंधों का अनुमान लगाने में अधिक सटीक होना चाहिए, ताकि यह नए डेटा बिंदुओं को सटीक रूप से वर्गीकृत कर सके। गहरे न्यूरल नेटवर्क वे नेटवर्क होते हैं जिनमें मध्य में अधिक लेयर (अधिक हिडन लेयर) होती हैं। मॉडल में जितनी अधिक हिडन लेयर और न्यूरॉन/नोड होते हैं, उतनी ही बेहतर मॉडल डेटा में पैटर्न को पहचान सकता है।
नियमित, फीड-फॉरवर्ड न्यूरल नेटवर्क, जैसा कि मैंने ऊपर वर्णित है, को अक्सर “घने न्यूरल नेटवर्क” कहा जाता है। ये घने न्यूरल नेटवर्क विभिन्न नेटवर्क आर्किटेक्चर के साथ जुड़े हुए हैं जो विभिन्न प्रकार के डेटा की व्याख्या में विशेषज्ञ हैं।
आरएनएन (रिकरेंट न्यूरल नेटवर्क) क्या हैं?

रिकरेंट न्यूरल नेटवर्क फीड-फॉरवर्ड न्यूरल नेटवर्क के सामान्य सिद्धांत को लेते हैं और उन्हें क्रमिक डेटा को संसाधित करने में सक्षम बनाने के लिए मॉडल को एक आंतरिक मेमोरी देते हैं। आरएनएन नाम में “रिकरेंट” भाग इस तथ्य से आता है कि इनपुट और आउटपुट लूप होते हैं। एक बार जब नेटवर्क का आउटपुट उत्पन्न हो जाता है, तो आउटपुट को कॉपी किया जाता है और नेटवर्क को इनपुट के रूप में वापस भेजा जाता है। जब निर्णय लिया जाता है, तो केवल वर्तमान इनपुट और आउटपुट का विश्लेषण नहीं किया जाता है, बल्कि पिछला इनपुट भी विचार किया जाता है। दूसरे शब्दों में, यदि नेटवर्क के लिए प्रारंभिक इनपुट X है और आउटपुट H है, तो H और X1 (डेटा अनुक्रम में अगला इनपुट) दोनों को नेटवर्क में अगले सीखने के दौर के लिए भेजा जाता है। इस तरह, डेटा के संदर्भ (पिछले इनपुट) को नेटवर्क के प्रशिक्षण के दौरान संरक्षित किया जाता है।
इस आर्किटेक्चर का परिणाम यह है कि आरएनएन क्रमिक डेटा को संसाधित करने में सक्षम हैं। हालांकि, आरएनएन को कुछ मुद्दों का सामना करना पड़ता है। आरएनएन वनिशिंग ग्रेडिएंट और एक्सप्लोडिंग ग्रेडिएंट समस्याओं से पीड़ित हैं।
आरएनएन द्वारा व्याख्या की जाने वाली अनुक्रमों की लंबाई सीमित है, विशेष रूप से एलएसटीएम की तुलना में।
एलएसटीएम (लॉन्ग शॉर्ट-टर्म मेमोरी नेटवर्क) क्या हैं?
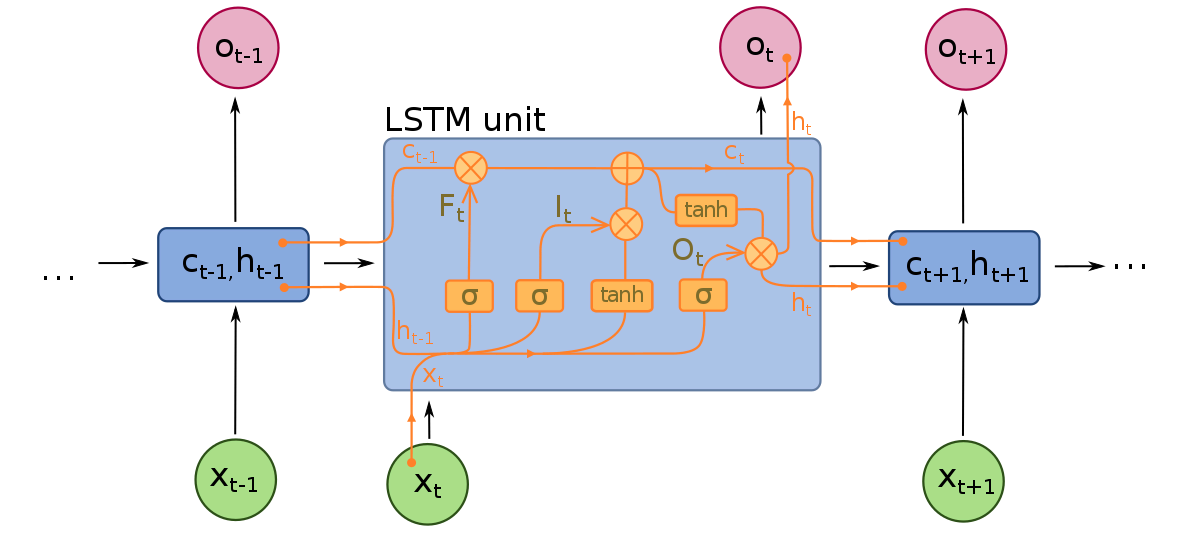
लॉन्ग शॉर्ट-टर्म मेमोरी नेटवर्क को आरएनएन के विस्तार के रूप में माना जा सकता है, जो एक बार फिर से इनपुट के संदर्भ को संरक्षित करने की अवधारणा को लागू करता है। हालांकि, एलएसटीएम को कई महत्वपूर्ण तरीकों से संशोधित किया गया है जो उन्हें अतीत के डेटा की व्याख्या करने के लिए श्रेष्ठ तरीकों से सक्षम बनाते हैं। एलएसटीएम में किए गए संशोधन वनिशिंग ग्रेडिएंट समस्या से निपटते हैं और एलएसटीएम को बहुत लंबे इनपुट अनुक्रमों पर विचार करने में सक्षम बनाते हैं।

एलएसटीएम मॉडल तीन अलग-अलग घटकों या गेट से बने होते हैं। एक इनपुट गेट, एक आउटपुट गेट, और एक भूलने का गेट है। आरएनएन की तरह, एलएसटीएम पिछले समय के चरण से इनपुट को ध्यान में रखते हुए मॉडल की मेमोरी और इनपुट वजन को संशोधित करते समय। इनपुट गेट यह तय करता है कि कौन से मान महत्वपूर्ण हैं और मॉडल के माध्यम से गुजरने चाहिए। इनपुट गेट में एक सिग्मॉइड फंक्शन का उपयोग किया जाता है, जो यह निर्धारित करता है कि कौन से मान पारित किए जाने चाहिए। 0 मान को गिरा देता है, जबकि 1 इसे संरक्षित करता है। एक टैनएच फंक्शन का भी उपयोग किया जाता है, जो यह तय करता है कि इनपुट मान मॉडल के लिए कितने महत्वपूर्ण हैं, -1 से 1 तक।
एक बार जब वर्तमान इनपुट और मेमोरी स्टेट के लिए खाता है, तो आउटपुट गेट यह तय करता है कि कौन से मान अगले समय चरण में धक्का देने चाहिए। आउटपुट गेट में, मानों का विश्लेषण किया जाता है और -1 से 1 तक के महत्व के साथ सौंपा जाता है। यह डेटा को अगले समय चरण की गणना से पहले नियंत्रित करता है। अंत में, भूलने के गेट का काम यह तय करना है कि कौन सी जानकारी मॉडल द्वारा इनपुट मानों की प्रकृति के बारे में निर्णय लेने के लिए अनावश्यक है। भूलने के गेट में एक सिग्मॉइड फंक्शन का उपयोग किया जाता है, जो 0 (भूलना) और 1 (संरक्षित) के बीच संख्या का उत्पादन करता है।
एक एलएसटीएम न्यूरल नेटवर्क विशेष एलएसटीएम लेयर से बना होता है जो क्रमिक शब्द डेटा की व्याख्या कर सकता है और ऊपर वर्णित घने से जुड़े हुए होते हैं। एक बार जब डेटा एलएसटीएम लेयर से गुजरता है, तो यह घने से जुड़े हुए लेयर में जाता है।








