IA 101
Qu’est-ce que la rétropropagation ?
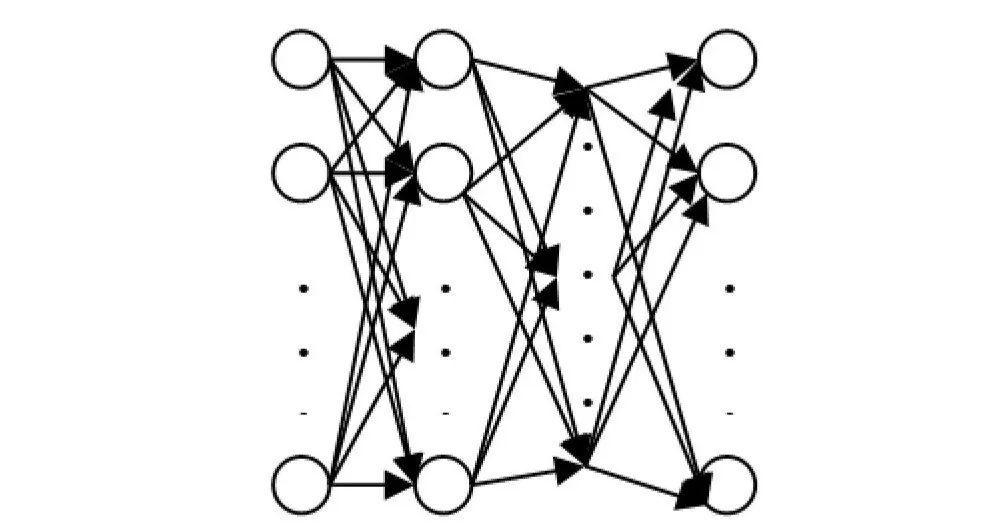
Qu’est-ce que la rétropropagation ?
Les systèmes d’apprentissage profond sont capables d’apprendre des modèles extrêmement complexes, et ils accomplissent cela en ajustant leurs poids. Comment les poids d’un réseau neuronal profond sont-ils ajustés exactement ? Ils sont ajustés grâce à un processus appelé rétropropagation. Sans rétropropagation, les réseaux neuronaux profonds ne seraient pas en mesure de réaliser des tâches telles que la reconnaissance d’images et l’interprétation du langage naturel. Comprendre comment la rétropropagation fonctionne est essentiel pour comprendre les réseaux neuronaux profonds en général, nous allons donc discuter de la rétropropagation et voir comment le processus est utilisé pour ajuster les poids d’un réseau.
La rétropropagation peut être difficile à comprendre, et les calculs utilisés pour effectuer la rétropropagation peuvent être assez complexes. Cet article tentera de vous donner une compréhension intuitive de la rétropropagation, en utilisant peu de mathématiques complexes. Cependant, une certaine discussion des mathématiques derrière la rétropropagation est nécessaire.
L’objectif de la rétropropagation
Commençons par définir l’objectif de la rétropropagation. Les poids d’un réseau neuronal profond sont la force des connexions entre les unités d’un réseau neuronal. Lorsque le réseau neuronal est établi, des hypothèses sont faites sur la façon dont les unités d’une couche sont connectées aux couches jointes. Lorsque les données traversent le réseau neuronal, les poids sont calculés et des hypothèses sont faites. Lorsque les données atteignent la dernière couche du réseau, une prédiction est faite sur la façon dont les fonctionnalités sont liées aux classes du jeu de données. La différence entre les valeurs prédites et les valeurs réelles est la perte/erreur, et l’objectif de la rétropropagation est de réduire la perte. Cela est réalisé en ajustant les poids du réseau, en rendant les hypothèses plus proches des véritables relations entre les fonctionnalités d’entrée.
Entraînement d’un réseau neuronal profond
Avant que la rétropropagation puisse être effectuée sur un réseau neuronal, le passage d’entraînement régulier/vers l’avant d’un réseau neuronal doit être effectué. Lorsqu’un réseau neuronal est créé, un ensemble de poids est initialisé. La valeur des poids sera modifiée au fur et à mesure que le réseau est entraîné. Le passage d’entraînement vers l’avant d’un réseau neuronal peut être conçu comme trois étapes distinctes : activation du neurone, transfert du neurone et propagation vers l’avant.
Lors de l’entraînement d’un réseau neuronal profond, nous devons utiliser plusieurs fonctions mathématiques. Les neurones d’un réseau neuronal profond sont composés des données entrantes et d’une fonction d’activation, qui détermine la valeur nécessaire pour activer le nœud. La valeur d’activation d’un neurone est calculée avec plusieurs composants, étant une somme pondérée des entrées. Les poids et les valeurs d’entrée dépendent de l’index des nœuds utilisés pour calculer l’activation. Un autre nombre doit être pris en compte lors du calcul de la valeur d’activation, une valeur de biais. Les valeurs de biais ne fluctuent pas, elles ne sont donc pas multipliées avec le poids et les entrées, elles sont simplement ajoutées. Tout cela signifie que l’équation suivante pourrait être utilisée pour calculer la valeur d’activation :
Activation = somme(poids * entrée) + biais
Une fois que le neurone est activé, une fonction d’activation est utilisée pour déterminer ce que sera la sortie réelle du neurone. Différentes fonctions d’activation sont optimales pour différentes tâches d’apprentissage, mais les fonctions d’activation couramment utilisées incluent la fonction sigmoïde, la fonction Tanh et la fonction ReLU.
Une fois que les sorties du neurone sont calculées en faisant passer la valeur d’activation à travers la fonction d’activation souhaitée, la propagation vers l’avant est effectuée. La propagation vers l’avant consiste simplement à prendre les sorties d’une couche et à les faire entrer dans la couche suivante. Les nouvelles entrées sont ensuite utilisées pour calculer les nouvelles fonctions d’activation, et la sortie de cette opération est transmise à la couche suivante. Ce processus se poursuit jusqu’à la fin du réseau neuronal.
Rétropropagation dans le réseau
Le processus de rétropropagation prend en compte les décisions finales d’un passage d’entraînement d’un modèle, puis il détermine les erreurs dans ces décisions. Les erreurs sont calculées en comparant les sorties/décisions du réseau et les sorties/décisions attendues du réseau.
Une fois que les erreurs dans les décisions du réseau ont été calculées, ces informations sont rétropropagées à travers le réseau et les paramètres du réseau sont modifiés en cours de route. La méthode utilisée pour mettre à jour les poids du réseau est basée sur le calcul, en particulier, il est basé sur la règle de la chaîne. Cependant, une compréhension du calcul n’est pas nécessaire pour comprendre l’idée derrière la rétropropagation. Il suffit de savoir qu’à chaque fois qu’une valeur de sortie est fournie par un neurone, la pente de la valeur de sortie est calculée à l’aide d’une fonction de transfert, produisant une sortie dérivée. Lors de la rétropropagation, l’erreur pour un neurone spécifique est calculée selon la formule :
erreur = (sortie_attendue – sortie_réelle) * pente de la valeur de sortie du neurone
Lorsque l’on opère sur les neurones de la couche de sortie, la valeur de classe est utilisée comme valeur attendue. Une fois que l’erreur a été calculée, l’erreur est utilisée comme entrée pour les neurones de la couche cachée, ce qui signifie que l’erreur pour cette couche cachée est l’erreur pondérée des neurones trouvés dans la couche de sortie. Les calculs d’erreur se propagent à rebours à travers le réseau le long des poids du réseau.
Une fois que les erreurs pour le réseau ont été calculées, les poids dans le réseau doivent être mis à jour. Comme mentionné, le calcul de l’erreur implique la détermination de la pente de la valeur de sortie. Une fois que la pente a été calculée, un processus appelé descente de gradient peut être utilisé pour ajuster les poids du réseau. Un gradient est une pente, dont l’angle/inclinaison peut être mesuré. La pente est calculée en tracé « y sur » ou la « montée » sur la « course ». Dans le cas du réseau neuronal et du taux d’erreur, le « y » est l’erreur calculée, tandis que le « x » est les paramètres du réseau. Les paramètres du réseau ont une relation avec les valeurs d’erreur calculées, et à mesure que les poids du réseau sont ajustés, l’erreur augmente ou diminue.
La « descente de gradient » est le processus de mise à jour des poids afin que le taux d’erreur diminue. La rétropropagation est utilisée pour prédire la relation entre les paramètres du réseau neuronal et le taux d’erreur, ce qui prépare le réseau pour la descente de gradient. L’entraînement d’un réseau avec la descente de gradient implique le calcul des poids à l’aide de la propagation vers l’avant, la rétropropagation de l’erreur, puis la mise à jour des poids du réseau.








