AI 101
Mikä on ylioppiminen?
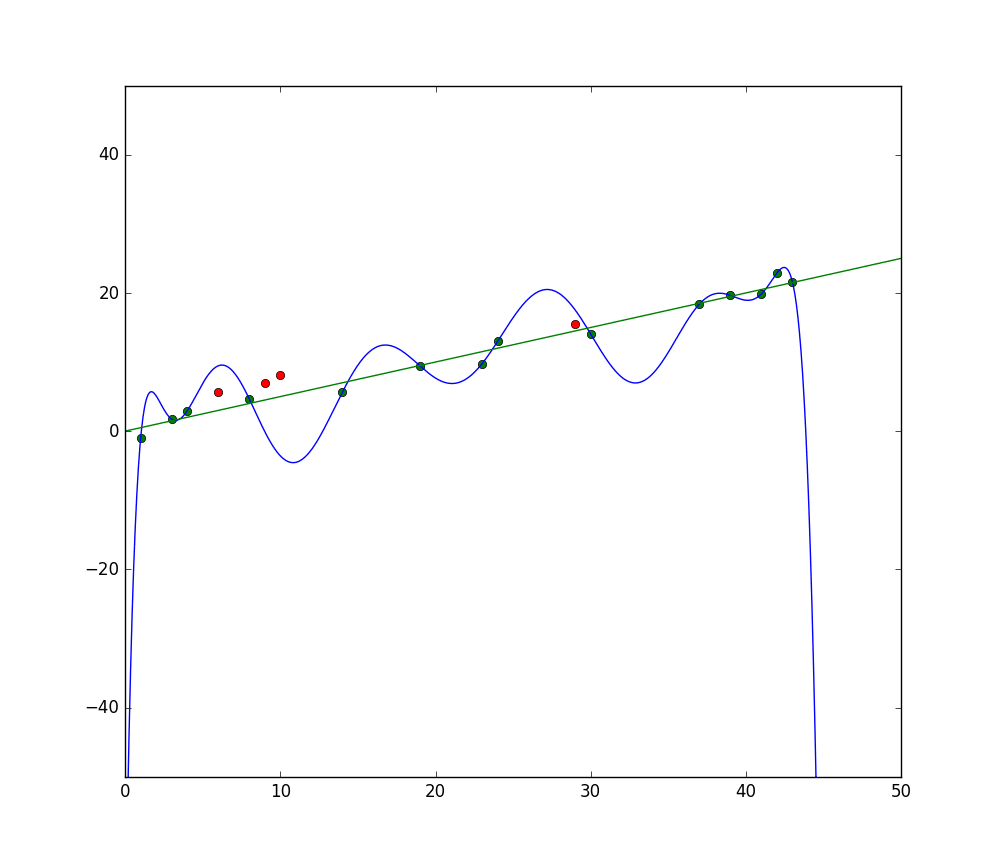
Mikä on ylioppiminen?
Kun koulutat neuroverkkoa, sinun on vältettävä ylioppimista. Ylioppiminen on ongelma koneoppimisessa ja tilastotieteessä, jossa malli oppii koulutusaineiston kuviot liian hyvin, selittäen koulutusaineiston täydellisesti, mutta epäonnistuen yleistämään ennustusvoimaansa muihin aineistoihin.
Toisin sanoen, ylioppimisen tapauksessa malli usein näyttää erittäin korkeaa tarkkuutta koulutusaineistossa, mutta matalaa tarkkuutta tulevaisuuden aineistoissa, jotka suoritetaan mallissa. Tämä on nopea määritelmä ylioppimiselle, mutta tarkastellaan ylioppimisen käsitettä tarkemmin. Tarkastellaan, miten ylioppiminen tapahtuu ja miten sitä voidaan välttää.
Ymmärtäminen “sopeutumisesta” ja aliopeutumisesta
On hyödyllistä tarkastella aliopeutumisen ja “sopeutumisen” käsitettä yleensä, kun keskustellaan ylioppimisesta. Kun koulutamme mallia, yritämme kehittää kehyksen, joka pystyy ennustamaan kohteiden luonteen tai luokan aineistossa, aineistossa kuvattujen ominaisuuksien perusteella. Mallin on kyettävä selittämään aineiston sisältämä kuviointi ja ennustamaan tulevaisuuden data-pisteiden luokat tämän kuvioiden perusteella. Mitä paremmin malli selittää koulutusaineiston ominaisuuksien välisen suhteen, sitä “sopeutuneempi” mallimme on.

Sininen viiva edustaa mallin ennusteita, jotka ovat aliopeutuneita, kun taas vihreä viiva edustaa paremmin sopeutunutta mallia. Kuva: Pep Roca via Wikimedia Commons, CC BY SA 3.0, (https://commons.wikimedia.org/wiki/File:Reg_ls_curvil%C3%ADnia.svg)
Malli, joka selittää huonosti koulutusaineiston ominaisuuksien välisen suhteen ja siten epäonnistuu ennustamaan tulevaisuuden data-esimerkit, on aliopeutunut. Jos piirtäisit mallin ennustaman suhteen graafina, ennusteet poikkeaisivat merkittävästi. Jos olisimme graafi, jossa olisi koulutusaineiston todelliset arvot, aliopeutunut malli olisi selvästi väärä. Paremmalla sopeutumisella varustettu malli voisi kulkea data-pisteiden läpi, jokainen data-piste olisi ennustetun arvon lähellä.
Aliopeutuminen voi usein tapahtua, kun aineistoa ei ole tarpeeksi luotettavan mallin luomiseksi, tai kun yritetään suunnitella lineaarista mallia epälineaariselle aineistolle. Lisää koulutusaineistoa tai ominaisuuksia usein auttaa vähentämään aliopeutumista.
Miksi emme siis luoda mallia, joka selittää jokaisen koulutusaineiston pisteen täydellisesti? Onko täydellinen tarkkuus toivottavaa? Luomalla mallin, joka on oppinut koulutusaineiston kuviot liian hyvin, aiheutamme ylioppimisen. Koulutusaineisto ja muut, tulevaisuudessa suoritettavat aineistot eivät ole täysin samanlaisia. Ne ovat todennäköisesti hyvin samanlaisia monilla tavoin, mutta ne myös poikkeavat tärkeissä suhteissa. Siksi mallin suunnittelussa, joka selittää koulutusaineiston täydellisesti, päädytään teoriaan, joka ei yleisty hyvin muihin aineistoihin.
Ymmärtäminen ylioppimisesta
Ylioppiminen tapahtuu, kun malli oppii koulutusaineiston yksityiskohtia liian hyvin, aiheuttaen mallille ongelmia, kun tehdään ennusteita ulkoisista aineistoista. Tämä voi tapahtua, kun malli oppii koulutusaineiston ominaisuuksien lisäksi myös satunnaisia muutoksia tai “mätä” aineistossa, antaen näille satunnaisille/asiallisille ilmiöille liian suuren merkityksen.
Ylioppiminen on todennäköisempää, kun ei-parametrinen koneoppimisalgoritmi käytetään, koska ne ovat joustavampia koulutusaineiston ominaisuuksien oppimisessa. Ei-parametrisissa koneoppimisalgoritmeissa on usein erilaisia parametreja ja tekniikoita, joita voidaan soveltaa rajoittamaan mallin herkkyyttä aineistoon ja siten vähentämään ylioppimista. Esimerkiksi päätöspuumallit ovat erittäin herkkä ylioppimiselle, mutta tekniikkaa, jossa poistetaan satunnaisesti osa yksityiskohtia, joita malli on oppinut, voidaan käyttää.
Jos piirtäisit mallin ennusteita x- ja y-akseleilla, sinulla olisi ennusteiden viiva, joka loikkaa edestakaisin, mikä heijastaa sitä, että malli on yrittänyt liian kovasti sovittaa kaikki koulutusaineiston pisteet selitykseensä.
Ylioppimisen hallitseminen
Kun koulutamme mallia, haluamme, että malli tekee mahdollisimman vähän virheitä. Kun mallin suorituskyky lähestyy oikein tehtyjä ennusteita koulutusaineiston kaikissa data-pisteissä, mallin sopeutuminen paranee. Hyvin sopeutunut malli pystyy selittämään lähes koko koulutusaineiston ilman ylioppimista.
Mallin suorituskyky paranee koulutuksen aikana. Mallin virheen määrä vähenee koulutuksen edetessä, mutta se laskee vain tiettyyn pisteeseen. Piste, jossa mallin suorituskyky testiaineistossa alkaa heiketä, on yleensä se piste, jossa ylioppiminen alkaa. Saadakseen parhaan sopeutumisen malliin, haluamme lopettaa mallin koulutuksen pisteessä, jossa koulutusaineistossa tapahtuu vähiten virheitä, ennen kuin virheen määrä alkaa kasvaa uudelleen. Optimaalinen lopetuspiste voidaan määrittää piirtämällä mallin suorituskyky koulutuksen aikana ja lopettamalla koulutus, kun virheen määrä on alin. On kuitenkin yksi riski tässä ylioppimisen hallitsemistavassa: testidatan käyttäminen koulutuksen päättymispisteen määrittämiseen tarkoittaa, että testidata ei ole enää täysin “koskematon” data.
On useita tapoja, joilla voidaan vähentää ylioppimista. Yksi tapa vähentää ylioppimista on käyttää uudelleenmallinnusstrategiaa, joka toimii arvioimalla mallin tarkkuutta. Voit myös käyttää validointiaineistoa testiaineiston lisäksi ja piirtää koulutusaineiston tarkkuuden validointiaineiston sijaan testiaineistoa vasten. Tällä tavoin testiaineisto säilyy näkemättömänä. Yksi suosittu uudelleenmallinnusmenetelmä on K-kertaisen ristinvalidoinnin tekniikka. Tämä tekniikka mahdollistaa aineiston jakamisen osiin, joilla malli koulutetaan, ja sitten mallin suorituskyky näissä osissa analyysoidaan arvioimaan, miten malli toimii ulkoisilla aineistoilla.
Uudelleenmallinnuksen käyttäminen on yksi parhaista tavoista arvioida mallin tarkkuutta näkemättömälle aineistolle, ja yhdistettynä validointiaineistoon ylioppiminen voidaan usein pitää vähäisimmillään.








