
AI 101
Mikä on päätöspuu?
Mikä on päätöspuu?
A päätöspuu on hyödyllinen koneoppimisalgoritmi, jota käytetään sekä regressio- että luokitustehtävissä. Nimi "päätöspuu" tulee siitä, että algoritmi jakaa tietojoukon yhä pienempiin osiin, kunnes tiedot on jaettu yksittäisiin esiintymiin, jotka sitten luokitellaan. Jos visualisoit algoritmin tulokset, kategorioiden jakautumistapa muistuttaisi puuta ja monia lehtiä.
Tämä on päätöspuun nopea määritelmä, mutta sukeltakaamme syvällisesti päätöspuun toimintaan. Päätöspuiden toiminnan ja niiden käyttötapausten parempi ymmärtäminen auttaa sinua tietämään, milloin niitä kannattaa hyödyntää koneoppimisprojektien aikana.
Päätöspuun muoto
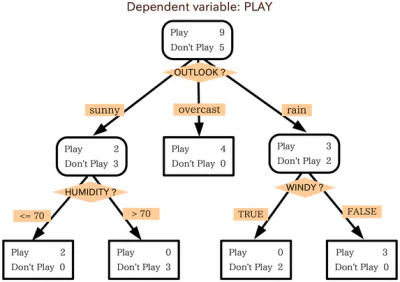
Päätöspuu on paljon kuin vuokaavio. Vuokaavion käyttämiseksi aloitat kaavion aloituspisteestä tai juurista ja siirryt sitten johonkin seuraavista mahdollisista solmuista sen perusteella, kuinka vastaat kyseisen aloitussolmun suodatusehtoihin. Tätä prosessia toistetaan, kunnes saavutetaan loppu.
Päätöspuut toimivat olennaisesti samalla tavalla, ja jokainen puun sisäinen solmu on jonkinlainen testi/suodatuskriteeri. Ulkopuolella olevat solmut, puun päätepisteet, ovat kyseisen tietopisteen nimiä ja niitä kutsutaan "lehdiksi". Haarat, jotka johtavat sisäisistä solmuista seuraavaan solmuun, ovat ominaisuuksia tai ominaisuuksien konjunktioita. Tietopisteiden luokittelemiseen käytetyt säännöt ovat polkuja, jotka kulkevat juuresta lehtiin.
Algoritmit päätöspuille
Päätöspuut toimivat algoritmisella lähestymistavalla, joka jakaa tietojoukon yksittäisiin tietopisteisiin eri kriteerien perusteella. Nämä jaot tehdään eri muuttujilla tai tietojoukon eri ominaisuuksilla. Jos tavoitteena on esimerkiksi määrittää, kuvataanko syöteominaisuuksien avulla koiraa tai kissaa, muuttujat, joiden perusteella tiedot jaetaan, voivat olla esimerkiksi "kynnet" ja "haukkuu".
Mitä algoritmeja sitten käytetään tietojen jakamiseen oksiin ja lehtiin? On olemassa useita menetelmiä, joita voidaan käyttää puun halkaisuun, mutta yleisin halkaisumenetelmä on luultavasti tekniikka, jota kutsutaan nimellä "rekursiivinen binäärijako”. Tätä jakamistapaa suoritettaessa prosessi alkaa juuresta ja tietojoukon ominaisuuksien määrä edustaa mahdollista mahdollisten jakojen määrää. Funktiota käytetään määrittämään, kuinka paljon tarkkuutta jokainen mahdollinen jako maksaa, ja jako tehdään käyttämällä kriteerejä, jotka uhraavat vähiten tarkkuutta. Tämä prosessi suoritetaan rekursiivisesti ja alaryhmiä muodostetaan käyttäen samaa yleistä strategiaa.
Jotta määrittää jaon kustannukset, käytetään kustannusfunktiota. Regressiotehtävissä ja luokitustehtävissä käytetään eri kustannusfunktiota. Molempien kustannusfunktioiden tavoitteena on määrittää, millä haaroilla on samankaltaisimmat vastearvot tai homogeenisimmat haarat. Ajattele, että haluat tietyn luokan testidatan kulkevan tiettyjä polkuja, ja tämä on intuitiivista järkeä.
Mitä tulee rekursiivisen binäärijaon regressiokustannusfunktioon, kustannusten laskemiseen käytetty algoritmi on seuraava:
summa(y – ennuste)^2
Tietyn datapisteryhmän ennuste on kyseisen ryhmän koulutusdatan vastausten keskiarvo. Kaikki datapisteet ajetaan kustannusfunktion läpi kaikkien mahdollisten splittien kustannusten määrittämiseksi, ja valitaan halvimmilla kustannuksilla oleva jako.
Mitä tulee luokittelun kustannusfunktioon, funktio on seuraava:
G = summa(pk * (1 – pk))
Tämä on Gini-pistemäärä, ja se mittaa jaon tehokkuutta sen perusteella, kuinka monta eri luokkaa on jaon tuloksena syntyneissä ryhmissä. Toisin sanoen se kvantifioi kuinka sekalaisia ryhmät ovat jakautumisen jälkeen. Optimaalinen jako on, kun kaikki jaosta syntyvät ryhmät koostuvat vain yhden luokan syötteistä. Jos optimaalinen jako on luotu, "pk"-arvo on joko 0 tai 1 ja G on yhtä suuri kuin nolla. Saatat pystyä arvaamaan, että pahimman tapauksen jako on sellainen, jossa jaon luokat on 50-50 binääriluokituksen tapauksessa. Tässä tapauksessa pk-arvo olisi 0.5 ja G olisi myös 0.5.
Jakoprosessi päättyy, kun kaikki datapisteet on muutettu lehdeiksi ja luokiteltu. Voit kuitenkin haluta pysäyttää puun kasvun aikaisin. Suuret monimutkaiset puut ovat alttiita ylisovitukselle, mutta tätä vastaan voidaan käyttää useita erilaisia menetelmiä. Yksi tapa vähentää ylisovitusta on määrittää vähimmäismäärä tietopisteitä, joita käytetään lehden luomiseen. Toinen tapa hallita ylisovitusta on puun rajoittaminen tiettyyn enimmäissyvyyteen, mikä ohjaa kuinka pitkä polku voi ulottua juuresta lehteen.
Toinen päätöspuiden luomiseen liittyvä prosessi on karsimista. Karsiminen voi auttaa parantamaan päätöspuun suorituskykyä poistamalla oksia, jotka sisältävät ominaisuuksia, joilla on vähän ennustavaa tehoa / vähän merkitystä mallille. Tällä tavalla puun monimutkaisuus vähenee, sen ylisovitus vähenee ja mallin ennakoiva hyödyllisyys lisääntyy.
Karsimista suoritettaessa prosessi voi alkaa joko puun yläosasta tai alaosasta. Helpoin tapa leikata on kuitenkin aloittaa lehdistä ja yrittää pudottaa solmu, joka sisältää yleisimmän luokan kyseisessä lehdessä. Jos mallin tarkkuus ei heikkene tätä tehtäessä, muutos säilyy. Karsimiseen käytetään muitakin tekniikoita, mutta edellä kuvattu menetelmä – vähennetty virheleikkaus – on luultavasti yleisin päätöspuun karsimistapa.
Päätöspuiden käyttöä koskevia huomioita
Päättävät puut ovat usein hyödyllisiä kun luokitus on suoritettava, mutta laskenta-aika on suuri rajoitus. Päätöspuut voivat tehdä selväksi, millä valituissa tietojoukoissa olevilla ominaisuuksilla on eniten ennustusvoimaa. Lisäksi toisin kuin monet koneoppimisalgoritmit, joissa tietojen luokittelemiseen käytettyjä sääntöjä voi olla vaikea tulkita, päätöspuut voivat tuottaa tulkittavia sääntöjä. Päätöspuut pystyvät myös hyödyntämään sekä kategorisia että jatkuvia muuttujia, mikä tarkoittaa, että tarvitaan vähemmän esikäsittelyä verrattuna algoritmeihin, jotka pystyvät käsittelemään vain yhtä näistä muuttujatyypeistä.
Päätöspuut eivät yleensä toimi kovin hyvin, kun niitä käytetään jatkuvien attribuuttien arvojen määrittämiseen. Toinen päätöspuiden rajoitus on, että luokittelua tehtäessä päätöspuu on epätarkka, jos harjoitusesimerkkejä on vähän, mutta luokkia useita.










