Ciberseguridad
Por qué los ataques de imagen adversarios no son una broma
Atacar los sistemas de reconocimiento de imágenes con imágenes antagónicas cuidadosamente elaboradas se ha considerado una prueba de concepto divertida pero trivial durante los últimos cinco años. Sin embargo, una nueva investigación de Australia sugiere que el uso casual de conjuntos de datos de imágenes muy populares para proyectos comerciales de IA podría crear un nuevo problema de seguridad duradero.
Desde hace un par de años, un grupo de académicos de la Universidad de Adelaida intenta explicar algo realmente importante sobre el futuro de los sistemas de reconocimiento de imágenes basados en IA.
Es algo que sería difícil (y muy costoso) de arreglar. ahora, y que sería excesivamente costoso remediar una vez que las tendencias actuales en investigación de reconocimiento de imágenes se hayan desarrollado completamente en implementaciones comercializadas e industrializadas en 5 a 10 años.
Antes de profundizar en el tema, echemos un vistazo a una flor que está clasificada como presidente Barack Obama, de uno de los seis vídeos que el equipo ha publicado en el sitio. página del proyecto:
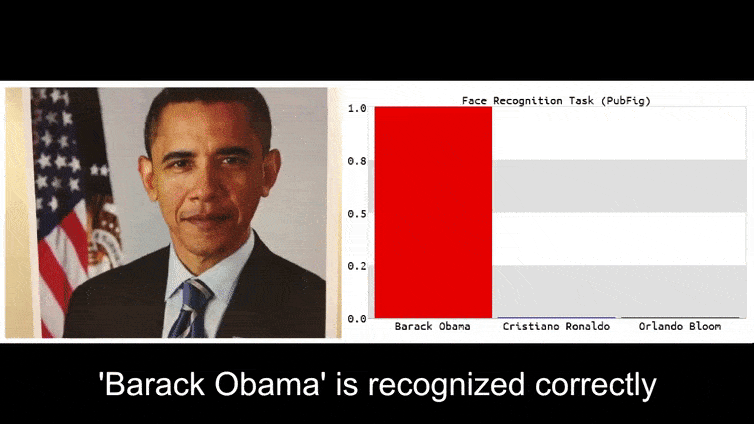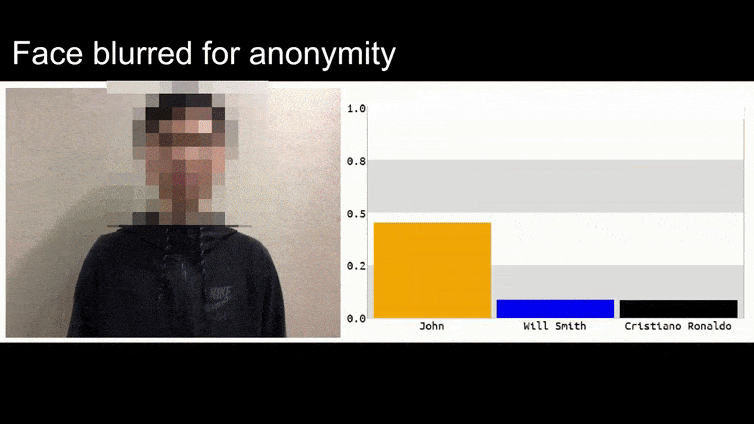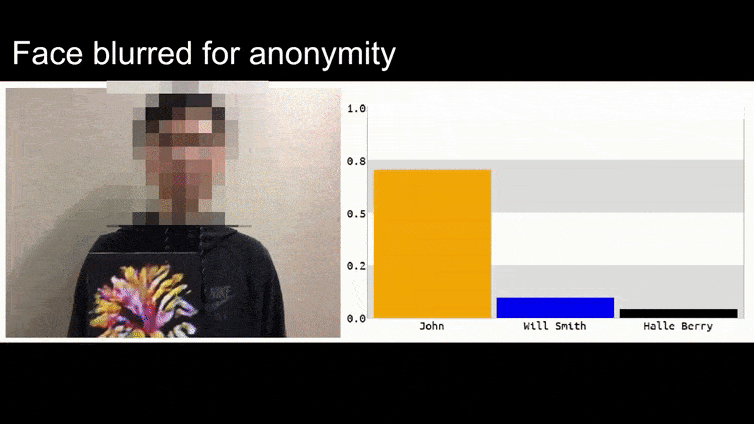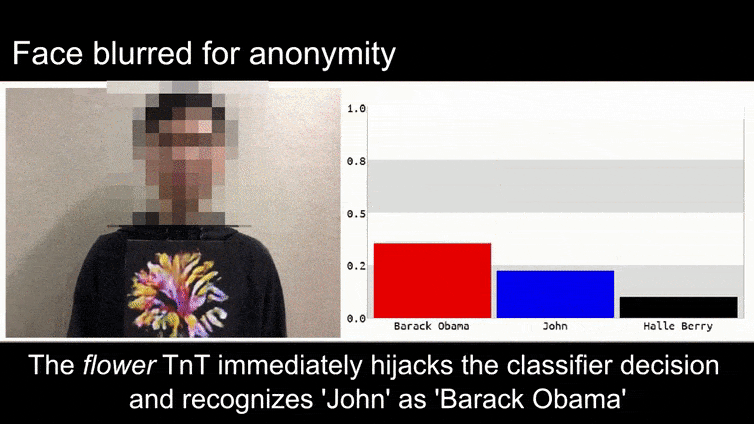
Fuente: https://www.youtube.com/watch?v=Klepca1Ny3c
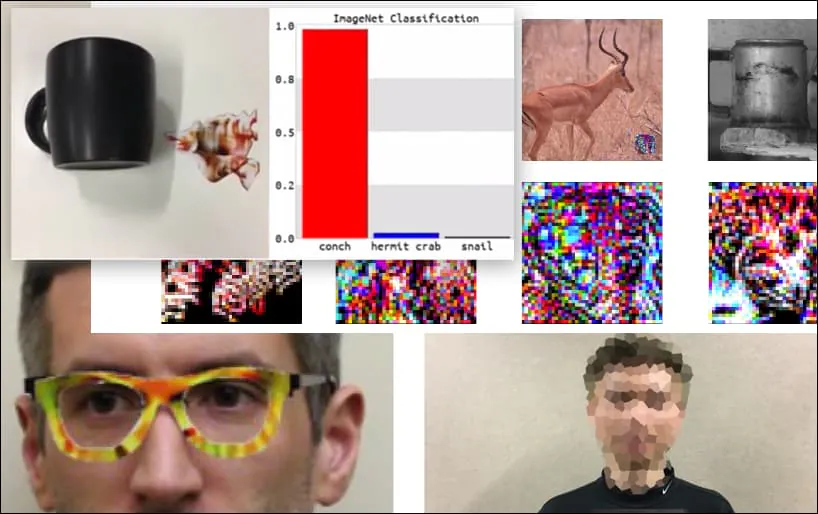
En la imagen de arriba, un sistema de reconocimiento facial que claramente reconoce a Barack Obama es engañado con un 80% de certeza al creer que un hombre anónimo que sostiene una imagen impresa y manipulada de una flor también es Barack Obama. Al sistema ni siquiera le importa que la "cara falsa" esté en el pecho del sujeto, en lugar de en sus hombros.
Aunque es impresionante que los investigadores hayan podido lograr este tipo de captura de identidad generando una imagen coherente (una flor) en lugar del habitual ruido aleatorio, parece que hazañas tontas como esta surgen con bastante regularidad en las investigaciones de seguridad sobre visión por computadora. . Por ejemplo, esas gafas con diseños extraños que podían engañar al reconocimiento facial de nuevo en 2016, o imágenes antagónicas especialmente diseñadas que intento de reescribir las señales de tráfico.
Si está interesado, el modelo de red neuronal convolucional (CNN) que se ataca en el ejemplo anterior es VGGFace (VGG-16), entrenados con el conjunto de datos PubFig de la Universidad de Columbia. Otros ejemplos de ataques desarrollados por los investigadores utilizaron diferentes recursos en distintas combinaciones.

Un teclado se reclasifica como una concha, en un modelo WideResNet50 en ImageNet. Los investigadores también se han asegurado de que el modelo no tenga sesgos hacia las caracolas. Vea el video completo para demostraciones extendidas y adicionales en https://www.youtube.com/watch?v=dhTTjjrxIcU
Reconocimiento de imágenes como vector de ataque emergente
Los numerosos ataques impresionantes que los investigadores describen e ilustran no son críticas a conjuntos de datos individuales ni a las arquitecturas específicas de aprendizaje automático que los utilizan. Tampoco se pueden defender fácilmente modificando conjuntos de datos o modelos, reentrenando modelos ni con ninguna de las otras soluciones "simples" que hacen que los profesionales del aprendizaje automático se burlen de las demostraciones esporádicas de este tipo de engaños.
Más bien, las hazañas del equipo de Adelaida ejemplifican una debilidad central en toda la arquitectura actual de desarrollo de IA de reconocimiento de imágenes; una debilidad que podría configurarse para exponer muchos sistemas futuros de reconocimiento de imágenes a una fácil manipulación por parte de los atacantes, y para poner cualquier medida defensiva posterior en el pie trasero.
Imagine que las últimas imágenes de ataques adversarios (como la flor de arriba) se agregan como "exploits de día cero" a los sistemas de seguridad del futuro, tal como los marcos antimalware y antivirus actuales actualizan sus definiciones de virus todos los días.
El potencial de nuevos ataques de imágenes adversarias sería inagotable, porque la arquitectura de base del sistema no anticipó problemas posteriores, como ocurrió. con internet, Error del milenio y el torre inclinada de Pisa.
¿De qué manera, entonces, estamos preparando el escenario para esto?
Obtener los datos para un ataque
Las imágenes adversarias, como la del ejemplo de la "flor" anterior, se generan al tener acceso a los conjuntos de datos de imágenes que entrenaron los modelos informáticos. No se necesita acceso privilegiado a los datos de entrenamiento (ni a las arquitecturas de los modelos), ya que los conjuntos de datos más populares (y muchos modelos entrenados) están ampliamente disponibles en un entorno torrent robusto y en constante actualización.
Por ejemplo, el venerable Goliat de los conjuntos de datos de Computer Vision, ImageNet, es disponible para torrent en todas sus muchas iteraciones, pasando por alto su habitual restricciones, y poner a disposición elementos secundarios cruciales, como conjuntos de validación.

Fuente: https://academiatorrents.com
Si tienes los datos, puedes (como observan los investigadores de Adelaida) realizar ingeniería inversa de manera efectiva en cualquier conjunto de datos popular, como paisajes urbanos o CIFAR.
En el caso de PubFig, el conjunto de datos que permitió la 'Flor de Obama' en el ejemplo anterior, la Universidad de Columbia ha abordado una tendencia creciente en cuestiones de derechos de autor en torno a la redistribución de conjuntos de datos de imágenes al instruir a los investigadores sobre cómo reproducir el conjunto de datos a través de enlaces seleccionados, en lugar de hacer que la compilación esté disponible directamente, observando «Esta parece ser la forma en que otras grandes bases de datos basadas en la web parecen estar evolucionando».
En la mayoría de los casos, eso no es necesario: Kaggle estima que los diez conjuntos de datos de imágenes más populares en visión artificial son: CIFAR-10 y CIFAR-100 (ambos directamente descargable); CALTECH-101 y 256 (ambos disponibles y actualmente disponibles como torrents); MNIST (oficialmente disponible, también en torrents); ImageNet (ver arriba); Pascal COV (estará disponible, también en torrents); MS COCO (estará disponible, y en torrents); Deportes-1M (estará disponible); y YouTube-8M (estará disponible).
Esta disponibilidad también es representativa de la gama más amplia de conjuntos de datos de imágenes de visión por computadora disponibles, ya que la oscuridad es la muerte en una cultura de desarrollo de código abierto de "publicar o perecer".
En cualquier caso, la escasez de manejable nuevos conjuntos de datos, el alto costo del desarrollo de conjuntos de imágenes, la dependencia de los "viejos favoritos" y la tendencia a simplemente adapte conjuntos de datos más antiguos todos exacerban el problema descrito en el nuevo documento de Adelaida.
Críticas típicas de los métodos de ataque de imágenes adversarias
La crítica más frecuente y persistente de los ingenieros de aprendizaje automático contra la efectividad de la última técnica de ataque de imagen adversaria es que el ataque es específico para un conjunto de datos en particular, un modelo en particular, o ambos; que no es “generalizable” a otros sistemas y, en consecuencia, sólo representa una amenaza trivial.
La segunda queja más frecuente es que el ataque de imagen adversario es 'caja blanca', lo que significa que necesitaría acceso directo al entorno de entrenamiento o a los datos. De hecho, este es un escenario poco probable, en la mayoría de los casos, por ejemplo, si desea explotar el proceso de capacitación para los sistemas de reconocimiento facial. de la Policía Metropolitana de LondresTendrías que abrirte paso a machetazos. NEC, ya sea con una consola o un hacha.
El ADN a largo plazo de los conjuntos de datos de visión artificial más populares
Con respecto a la primera crítica, debemos considerar no solo que un puñado de conjuntos de datos de visión por computadora dominan la industria por sector año tras año (es decir, ImageNet para múltiples tipos de objetos, CityScapes para escenas de conducción y FFHQ para reconocimiento facial); pero también que, como simples datos de imágenes anotadas, son “agnósticos de la plataforma” y altamente transferibles.
Dependiendo de sus capacidades, cualquier arquitectura de entrenamiento de visión artificial encontrará some características de objetos y clases en el conjunto de datos de ImageNet. Algunas arquitecturas pueden encontrar más características que otras, o hacer conexiones más útiles que otras, pero todas debe encontrar al menos las características de más alto nivel:

Datos de ImageNet, con el número mínimo viable de identificaciones correctas: características de "alto nivel".
Son esas características "de alto nivel" las que distinguen y "huellan" un conjunto de datos, y que son los "ganchos" confiables en los que colgar una metodología de ataque de imágenes adversarias a largo plazo que puede abarcar diferentes sistemas y crecer en tándem con el "viejo" conjunto de datos a medida que este último se perpetúa en nuevas investigaciones y productos.
Una arquitectura más sofisticada producirá identificaciones, características y clases más precisas y granulares:

Sin embargo, cuanto más se base un generador de ataques adversarios en estos lower características (es decir, 'varón caucásico joven' en lugar de 'rostro'), menos eficaz será en arquitecturas cruzadas o posteriores que utilicen diferentes versiones del conjunto de datos original, como un subconjunto o un conjunto filtrado, donde muchas de las imágenes originales del conjunto de datos completo no están presentes:

Ataques adversarios a modelos preentrenados y puestos a cero
¿Qué pasa con los casos en los que simplemente descarga un modelo previamente entrenado que se entrenó originalmente en un conjunto de datos muy popular y le proporciona datos completamente nuevos?
El modelo ya ha sido entrenado en (por ejemplo) ImageNet, y todo lo que falta son los pesos, que puede haber tomado semanas o meses para entrenar, y ahora están listos para ayudarlo a identificar objetos similares a los que existían en los datos originales (ahora ausentes).

Con los datos originales eliminados de la arquitectura de entrenamiento, lo que queda es la "predisposición" del modelo a clasificar objetos de la forma en que aprendió a hacerlo originalmente, lo que esencialmente provocará que muchas de las "firmas" originales se reformen y se vuelvan vulnerables una vez más a los mismos viejos métodos de ataque de imágenes adversarias.
Esos pesos son valiosos. sin los datos or Con los pesos, básicamente se obtiene una arquitectura vacía sin datos. Tendrá que entrenarla desde cero, con un gran gasto de tiempo y recursos computacionales, tal como lo hicieron los autores originales (probablemente con hardware más potente y con un presupuesto mayor del disponible).
El problema es que los pesos ya están bastante bien formados y son resistentes. Aunque se adaptarán un poco durante el entrenamiento, se comportarán de forma similar en los nuevos datos a como lo hicieron en los datos originales, generando características distintivas que un sistema de ataque adversario puede identificar.
A largo plazo, esto también preserva el 'ADN' de los conjuntos de datos de visión por computadora que son doce años o más, y puede haber pasado por una evolución notable desde los esfuerzos de código abierto hasta las implementaciones comercializadas, incluso cuando los datos de capacitación originales se desecharon por completo al comienzo del proyecto. Es posible que algunos de estos despliegues comerciales no ocurran hasta dentro de unos años.
No se necesita caja blanca
Con respecto a la segunda crítica común de los sistemas de ataque de imágenes adversarios, los autores del nuevo artículo descubrieron que su capacidad para engañar a los sistemas de reconocimiento con imágenes de flores diseñadas es altamente transferible a través de varias arquitecturas.
Si bien observan que su método 'Universal NaTuralistic adversarial paTches' (TnT) es el primero en utilizar imágenes reconocibles (en lugar de ruido de perturbación aleatorio) para engañar a los sistemas de reconocimiento de imágenes, los autores también afirman:
'[TnTs] son efectivos contra múltiples clasificadores de última generación que van desde ampliamente utilizados WideResNet50 en la tarea de reconocimiento visual a gran escala de ImagenNet conjunto de datos a modelos VGG-face en la tarea de reconocimiento facial de PubFig. conjunto de datos en ambos afectados y no dirigido ataques.
'TnTs puede poseer: i) el naturalismo alcanzable [con] activadores utilizados en los métodos de ataque troyanos; y ii) la generalización y transferibilidad de ejemplos adversos a otras redes.
'Esto genera preocupaciones de seguridad con respecto a las DNN ya implementadas, así como a las implementaciones futuras de DNN, en las que los atacantes pueden usar parches de objetos de aspecto natural y discretos para desviar la atención de los sistemas de redes neuronales sin alterar el modelo y correr el riesgo de ser descubiertos'.
Los autores sugieren que las contramedidas convencionales, como la degradación de Clean Acc. de una red, teóricamente podría proporcionar alguna defensa contra los parches TnT, pero eso 'Los TnT aún pueden eludir con éxito estos métodos de defensa demostrables de SOTA, y la mayoría de los sistemas de defensa logran una robustez del 0 %'.
Otras posibles soluciones incluyen aprendizaje federado, donde se protege la procedencia de las imágenes contribuyentes, y nuevos enfoques que podrían "encriptar" directamente los datos en el momento del entrenamiento, como uno sugerido recientemente por la Universidad de Aeronáutica y Astronáutica de Nanjing.
Incluso en esos casos, sería importante entrenar en genuinamente vehículo datos de imágenes: hoy en día, las imágenes y las anotaciones asociadas en el pequeño grupo de los conjuntos de datos de CV más populares están tan integradas en los ciclos de desarrollo en todo el mundo que se parecen más al software que a los datos; un software que a menudo no se ha actualizado notablemente en años.
Conclusión
Los ataques de imágenes adversarios son posibles no solo gracias a prácticas de aprendizaje automático de código abierto, sino también gracias a una cultura de desarrollo de IA corporativa que está motivada a reutilizar conjuntos de datos de visión artificial bien establecidos por varias razones: ya han demostrado ser efectivos, son mucho más baratos que "empezar desde cero" y son mantenidos y actualizados por mentes y organizaciones de vanguardia en el ámbito académico y la industria, con niveles de financiación y personal que serían difíciles de replicar para una sola empresa.
Además, en muchos casos donde los datos no son originales (a diferencia de CityScapes), las imágenes se recopilaron antes de las controversias recientes sobre la privacidad y las prácticas de recopilación de datos, dejando estos conjuntos de datos más antiguos en una especie de purgatorio semilegal que puede parecer un "puerto seguro" desde el punto de vista de una empresa.
¡Ataques TnT! Parches antagónicos naturalistas universales contra sistemas de redes neuronales profundas está escrito en coautoría por Bao Gia Doan, Minhui Xue, Ehsan Abbasnejad, Damith C. Ranasinghe de la Universidad de Adelaide, junto con Shiqing Ma del Departamento de Ciencias de la Computación de la Universidad de Rutgers.
Actualizado el 1 de diciembre de 2021, 7:06 a. m. GMT+2: error tipográfico corregido.












