Künstliche Intelligenz
‘Kreatives’ Gesichtsverifizierung mit Generative Adversarial Networks

Ein neues Papier der Stanford University hat eine nascente Methode zur Täuschung von Gesichtsauthentifizierungssystemen auf Plattformen wie Dating-Apps vorgeschlagen, indem es ein Generative Adversarial Network (GAN) verwendet, um alternative Gesichtsbilder zu erstellen, die die gleichen wesentlichen ID-Informationen wie ein echtes Gesicht enthalten.
Die Methode hat erfolgreich die Gesichtsverifizierungsprozesse in den Dating-Apps Tinder und Bumble umgangen, in einem Fall sogar ein geschlechtsspezifisches (männliches) Gesicht als authentisch für die Quellenidentität (weiblich) ausgewiesen.

Verschiedene generierte Identitäten, die die spezifische Kodierung des Autors des Papiers (in der ersten Abbildung oben) aufweisen. Quelle: https://arxiv.org/pdf/2203.15068.pdf
Laut dem Autor stellt die Arbeit den ersten Versuch dar, die Gesichtsverifizierung mit generierten Bildern zu umgehen, die mit spezifischen Identitätsmerkmalen ausgestattet sind, aber versuchen, eine alternative oder wesentlich veränderte Identität darzustellen.
Die Technik wurde auf einem benutzerdefinierten lokalen Gesichtsverifizierungssystem getestet und hat sich in Black-Box-Tests gegen zwei Dating-Apps, die Gesichtsverifizierung auf benutzerhochgeladenen Bildern durchführen, bewährt.
Das neue Papier trägt den Titel Gesichtsverifizierungsumgehung und stammt von Sanjana Sarda, einer Forscherin am Department of Electrical Engineering der Stanford University.
Steuerung des Gesichtsraums
Obwohl das “Einfügen” von ID-spezifischen Merkmalen (z. B. von Gesichtern, Verkehrsschildern usw.) in handgefertigte Bilder ein Standardverfahren bei adversarialen Angriffen ist, legt die neue Studie etwas anderes nahe: dass die wachsende Fähigkeit des Forschungssektors, den latenten Raum von GANs zu steuern, letztendlich die Entwicklung von Architekturen ermöglichen wird, die konsistente alternative Identitäten zu denen eines Benutzers erstellen können – und effektiv die Extraktion von Identitätsmerkmalen aus im Internet verfügbaren Bildern eines unwissenden Benutzers ermöglichen, um sie in eine “Schatten”-Identität zu integrieren.
Konsistenz und Navigierbarkeit sind die primären Herausforderungen im Zusammenhang mit dem latenten Raum von GANs, seit der Einführung von Generative Adversarial Networks. Ein GAN, das erfolgreich eine Sammlung von Trainingsbildern in seinen latenten Raum integriert hat, bietet keine einfache Karte, um Merkmale von einer Klasse zu einer anderen zu “schieben”.
Während Techniken und Tools wie Gradient-weighted Class Activation Mapping (Grad-CAM) helfen können, latente Richtungen zwischen den etablierten Klassen zu etablieren und Transformationen zu ermöglichen (siehe Bild unten), stellt die weitere Herausforderung der Verflechtung in der Regel eine “approximative” Reise dar, mit begrenzter Feinsteuerung des Übergangs.
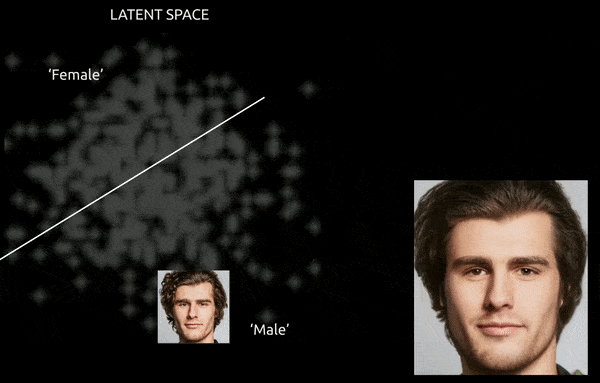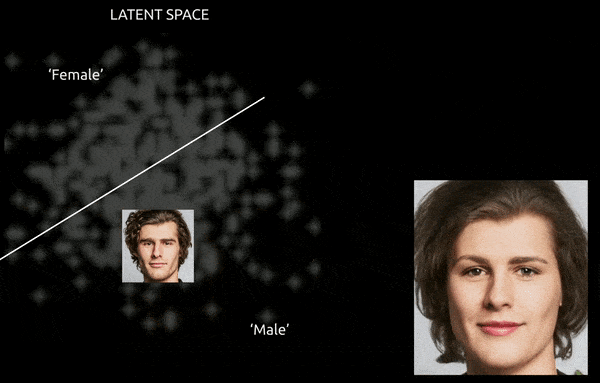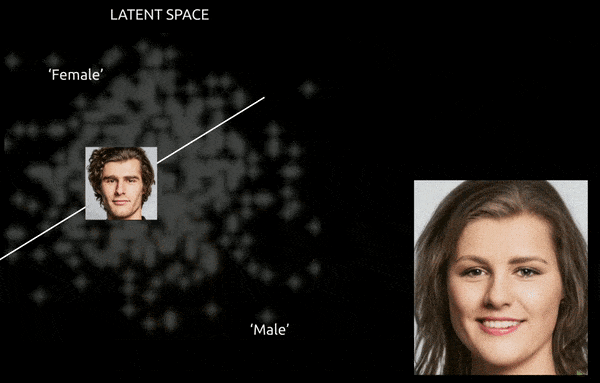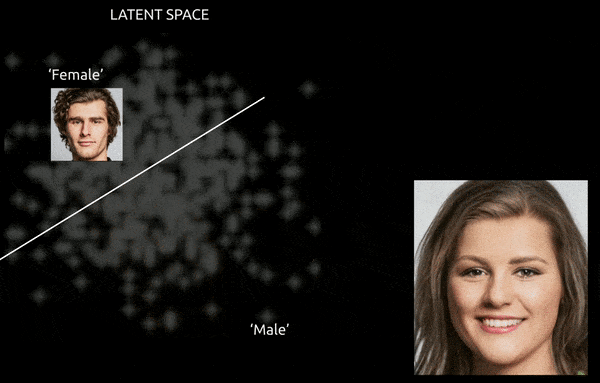
Eine grobe Reise zwischen kodierten Vektoren im latenten Raum eines GAN, bei der eine Daten-abgeleitete männliche Identität in die “weiblichen” Kodierungen auf der anderen Seite einer der vielen linearen Hyperflächen im komplexen und arkane latenten Raum geschoben wird. Bild abgeleitet von Material bei https://www.youtube.com/watch?v=dCKbRCUyop8
Die Fähigkeit, ID-spezifische Merkmale zu “einfrieren” und zu schützen, während sie in transformative Kodierungen an anderer Stelle im latenten Raum bewegt werden, macht es möglicherweise möglich, eine konsistente (und sogar animierbare) Person zu erstellen, deren Identität von Maschinensystemen als jemand anderes gelesen wird.
Methode
Der Autor verwendete zwei Datensätze als Grundlage für die Experimente: ein Human User Dataset, das 310 Bilder seines Gesichts über einen Zeitraum von vier Jahren umfasst, mit verschiedenen Beleuchtungen, Alter und Blickwinkeln), mit extrahierten Gesichtern über Caffe; und das rassisch ausgewogene Dataset FairFace mit 108.501 Bildern, ähnlich extrahiert und beschnitten.
Das lokale Gesichtsverifizierungsmodell wurde von einer Basisimplementierung von FaceNet und DeepFace abgeleitet, das auf ConvNet Inception vortrainiert wurde, wobei jedes Bild durch einen 128-dimensionalen Vektor dargestellt wurde.
Der Ansatz verwendet Gesichtsbilder aus einem trainierten Teil des FairFace-Datensatzes. Um die Gesichtsverifizierung zu bestehen, wird die berechnete Distanz, die durch die Frobenius-Norm eines Bildes verursacht wird, gegen die Zielbenutzerin in der Datenbank ausgeglichen. Jedes Bild unter der Schwelle von 0,7 entspricht der gleichen Identität, andernfalls gilt die Verifizierung als fehlgeschlagen.
Ein StyleGAN-Modell wurde auf dem persönlichen Datensatz des Autors feinjustiert, um ein Modell zu erstellen, das erkennbare Variationen seiner Identität generieren würde, obwohl keine der generierten Bilder identisch mit den Trainingsdaten waren. Dies wurde erreicht, indem die ersten vier Schichten im Diskriminator eingefroren wurden, um ein Überanpassen der Daten zu vermeiden und variierte Ausgaben zu produzieren.
Obwohl mit dem Basis-StyleGAN-Modell diverse Bilder erhalten wurden, führte die geringe Auflösung und Fidelität zu einem zweiten Versuch mit StarGAN V2, das das Training von Seed-Bildern auf ein Zielgesicht ermöglicht.
Das StarGAN V2-Modell wurde über etwa 10 Stunden mit dem FairFace-Validierungsdatensatz trainiert, mit einer Batch-Größe von vier und einer Validierungsgröße von 8. Im erfolgreichsten Ansatz wurde der persönliche Datensatz des Autors als Quelle mit Trainingsdaten als Referenz verwendet.
Verifizierungsexperimente
Ein Gesichtsverifizierungsmodell wurde auf der Grundlage eines Teils von 1000 Bildern konstruiert, mit dem Ziel, ein willkürliches Bild aus dem Satz zu verifizieren. Bilder, die die Verifizierung erfolgreich bestanden, wurden anschließend gegen die eigene ID des Autors getestet.

Links, der Autor des Papiers, ein echtes Foto; Mitte, ein willkürliches Bild, das die Verifizierung nicht bestanden hat; rechts, ein unabhängiges Bild aus dem Datensatz, das die Verifizierung als Autor bestanden hat.
Das Ziel der Experimente bestand darin, eine so große Lücke wie möglich zwischen der wahrgenommenen visuellen Identität zu schaffen, während die definierenden Merkmale der Zielidentität beibehalten werden. Dies wurde mit der Mahalanobis-Distanz bewertet, einem in der Bildverarbeitung für Muster- und Vorlagensuche verwendeten Maß.
Für das Basismodell des generativen Modells zeigen die Ergebnisse mit niedriger Auflösung begrenzte Vielfalt, obwohl sie die lokale Gesichtsverifizierung bestanden. StarGAN V2 erwies sich als fähiger, diverse Bilder zu erstellen, die in der Lage waren, sich zu authentifizieren.

Alle abgebildeten Bilder haben die lokale Gesichtsverifizierung bestanden. Oben sind die Bildgenerierungen mit niedriger Auflösung des StyleGAN-Basismodells, unten die Bildgenerierungen mit höherer Auflösung und höherer Qualität von StarGAN V2.
Die letzten drei Bilder oben verwendeten den persönlichen Datensatz des Autors als Quelle und Referenz, während die vorherigen Bilder Trainingsdaten als Referenz und den Datensatz des Autors als Quelle verwendeten.
Die resultierenden generierten Bilder wurden gegen die Gesichtsverifizierungssysteme der Dating-Apps Bumble und Tinder getestet, wobei die Identität des Autors als Basis diente, und haben die Verifizierung bestanden. Eine “männliche” Generation des Gesichts des Autors hat auch die Verifizierung von Bumble bestanden, obwohl die Beleuchtung im generierten Bild vorher angepasst werden musste. Tinder hat die männliche Version nicht akzeptiert.

‘Männliche’ Versionen der (weiblichen) Identität des Autors.
Schlussfolgerung
Diese sind seminale Experimente in der Identitätsprojektion im Kontext der Manipulation des latenten Raums von GANs, was nach wie vor eine außergewöhnliche Herausforderung in der Bildsynthese und der Deepfake-Forschung darstellt. Dennoch öffnet die Arbeit das Konzept der Einbettung hochspezifischer Merkmale konsistent über diverse Identitäten und der Erstellung von “alternativen” Identitäten, die von Maschinensystemen als jemand anderes gelesen werden.
Erstveröffentlicht am 30. März 2022.












