
Künstliche Intelligenz
Entflechtung ist die nächste Deepfake-Revolution

CGI-Datenerweiterung wird in einem neuen Projekt eingesetzt, um eine bessere Kontrolle über Deepfake-Bilder zu erlangen. Obwohl Sie CGI-Köpfe immer noch nicht effektiv nutzen können, um die fehlenden Lücken in Deepfake-Gesichtsdatensätzen zu schließen, bedeutet eine neue Welle von Forschungen zur Trennung von Identität und Kontext, dass Sie dies möglicherweise bald nicht mehr tun müssen.
Die Ersteller einiger der erfolgreichsten viralen Deepfake-Videos der letzten Jahre wählen ihre Quellvideos sehr sorgfältig aus und vermeiden dauerhafte Profilaufnahmen (d. h. die Art von seitlichen Fahndungsfotos, die bei polizeilichen Festnahmeverfahren populär werden), spitze Winkel und ungewöhnliche oder übertriebene Ausdrücke . In zunehmendem Maße handelt es sich bei den von viralen Deepfakern produzierten Demonstrationsvideos um bearbeitete Zusammenstellungen, die die „einfachsten“ Blickwinkel und Ausdrücke zum Deepfaken auswählen.
Tatsächlich ist das geeignetste Zielvideo, in das ein Deepfake eingefügt werden kann, ein Promi, bei dem die ursprüngliche Person (deren Identität durch das Deepfake gelöscht wird) direkt in die Kamera schaut, mit minimalem Gesichtsausdruck.

Die meisten populären Deepfakes der letzten Jahre zeigten Motive, die direkt in die Kamera blickten und entweder nur populäre Ausdrücke (z. B. Lächeln) trugen, die leicht aus Paparazzi-Ausgaben auf dem roten Teppich entnommen werden können, oder (wie bei der Fälschung von Sylvester Stallone aus dem Jahr 2019). (z. B. der Terminator, links abgebildet), idealerweise ohne jeglichen Ausdruck, da neutrale Ausdrücke sehr verbreitet sind und sich daher leicht in Deepfake-Modelle integrieren lassen.
Denn Deepfake-Technologien wie z.B DeepFaceLab machen Gesicht tauschen Wenn wir diese einfacheren Tauschvorgänge sehr gut durchführen, sind wir so beeindruckt von dem, was sie erreichen, dass wir gar nicht merken, wozu sie nicht in der Lage sind, und – oft – versuchen wir es gar nicht erst:

Schnappschüsse aus einem gefeierten Deepfake-Video, in dem Arnold Schwarzenegger in Sylvester Stallone verwandelt wird – es sei denn, die Blickwinkel sind zu knifflig. Profile bleiben bei aktuellen Deepfake-Ansätzen ein anhaltendes Problem, teilweise weil die Open-Source-Software, die zum Definieren von Gesichtsposen in Deepfake-Frameworks verwendet wird, nicht für Seitenansichten optimiert ist, sondern hauptsächlich aufgrund des Mangels an geeignetem Quellmaterial für einen oder beide der erforderlichen Bereiche Datensätze. Quelle: https://www.youtube.com/watch?v=AQvCmQFScMA
Neue Forschung aus Israel schlägt eine neuartige Methode zur Verwendung synthetischer Daten wie CGI-Köpfe vor, um Deepfaking in die 2020er Jahre zu bringen, indem Gesichtsidentitäten (d. h. die wesentlichen Gesichtsmerkmale von „Tom Cruise“ aus allen Blickwinkeln) wirklich von ihrem Kontext (d. h hoch schauen, seitwärts schauen, finster, finster im Dunkeln blickend, Brauen gerunzelt, Augen geschlossen, Etc.).

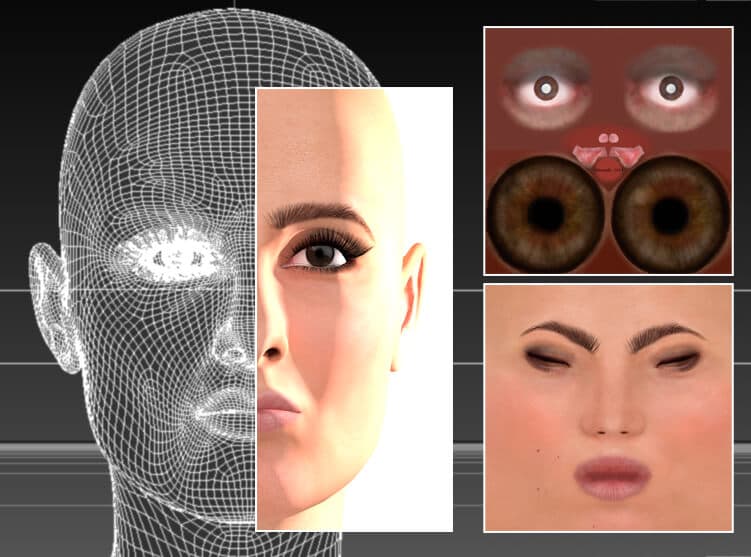
Das neue System trennt Pose und Kontext (z. B. ein Augenzwinkern) diskret von der Identitätskodierung des Individuums und verwendet dazu unabhängige synthetische Gesichtsdaten (Bild links). In der oberen Reihe sehen wir ein „Augenzwinkern“, das auf die Identität von Barack Obama übertragen wird, ausgelöst durch den erlernten nichtlinearen Pfad des latenten Raums eines GAN, dargestellt durch das CGI-Bild links. In der Reihe unten sehen wir die gestreckte Mundwinkelfacette, die auf den ehemaligen Präsidenten übertragen wurde. Unten rechts sehen wir, wie beide Merkmale gleichzeitig angewendet werden. Quelle: https://arxiv.org/pdf/2111.08419.pdf
Das ist nicht bloß Deepfake-Kopfpuppenspiel, eine Technik, die sich besser für Avatare und teilweise Gesichtslippensynchronisierung eignet und nur begrenztes Potenzial für vollständige Deepfake-Videotransformationen bietet.
Vielmehr stellt dies einen Weg nach vorn für eine grundlegende Trennung der Instrumentalität dar (z. B „den Winkel des Kopfes ändern“, „ein Stirnrunzeln erzeugen“) von der Identität und bietet einen Weg zu einem hochrangigen und nicht „abgeleiteten“, auf Bildsynthese basierenden Deepfake-Framework.
Das neue Papier trägt den Titel Delta-GAN-Encoder: Codierung semantischer Änderungen für die explizite Bildbearbeitung unter Verwendung weniger synthetischer Samples, und stammt von Forschern am Technion – Israel Institute of Technology.
Um zu verstehen, was die Arbeit bedeutet, werfen wir einen Blick darauf, wie Deepfakes derzeit überall produziert werden, von Deepfake-Pornoseiten bis hin zu Industrielicht und Magie (da das Open-Source-Repository DeepFaceLab derzeit sowohl beim „Amateur“- als auch beim professionellen Deepfaking dominiert).
Was hält die aktuelle Deepfake-Technologie zurück?
Deepfakes werden derzeit durch Schulungen erstellt Encoder/Decoder Modell für maschinelles Lernen auf zwei Ordnern mit Gesichtsbildern – der Person, die Sie „übermalen“ möchten (im vorherigen Beispiel ist das Arnie) und der Person, die Sie in das Filmmaterial einblenden möchten (Sly).

Beispiele für unterschiedliche Posen und Lichtverhältnisse bei zwei verschiedenen Gesichtssätzen. Beachten Sie den charakteristischen Ausdruck am Ende der dritten Zeile in Spalte A, der im anderen Datensatz wahrscheinlich keine ähnliche Entsprechung hat.
Dann das Encoder-/Decodersystem vergleicht jedes einzelne Bild in jedem Ordner zueinander, wobei dieser Vorgang über Hunderttausende von Iterationen (oft bis zu einer Woche) aufrechterhalten, verbessert und wiederholt wird, bis die wesentlichen Merkmale beider Identitäten gut genug verstanden sind, um sie nach Belieben auszutauschen.
Für jede der beiden Personen, die dabei ausgetauscht werden, erfährt die Deepfake-Architektur Folgendes über die Identität mit dem Kontext verstrickt. Es kann keine Prinzipien über eine generische Pose „für immer und ewig“ erlernen und anwenden, sondern benötigt reichlich Beispiele im Trainingsdatensatz für jede einzelne Identität, die am Gesichtstausch beteiligt sein wird.
Wenn Sie also zwei Identitäten tauschen möchten, die etwas Ungewöhnlicheres tun, als nur zu lächeln oder direkt in die Kamera zu schauen, benötigen Sie Folgendes viele Instanzen dieser bestimmten Pose/Identität über die beiden Gesichtssätze hinweg:

Da Gesichts-ID und Posenmerkmale derzeit stark miteinander verflochten sind, ist eine weitreichende Gleichheit von Ausdruck, Kopfhaltung und (in geringerem Maße) Beleuchtung über zwei Gesichtsdatensätze hinweg erforderlich, um ein effektives Deepfake-Modell auf Systemen wie DeepFaceLab zu trainieren. Je weniger eine bestimmte Konfiguration (z. B. „Seitenansicht/lächelnd/sonnenbeschienen“) in beiden Gesichtssätzen vorkommt, desto ungenauer wird sie bei Bedarf in einem Deepfake-Video wiedergegeben.
Wenn Set A die ungewöhnliche Pose enthält, Set B jedoch nicht, haben Sie ziemlich viel Pech. Unabhängig davon, wie lange Sie das Modell trainieren, wird es nie lernen, diese Pose zwischen den Identitäten gut zu reproduzieren, da es beim Training nur über die Hälfte der erforderlichen Informationen verfügte.
Selbst wenn Sie übereinstimmende Bilder haben, reicht dies möglicherweise nicht aus: Wenn Set A die passende Pose hat, aber mit grellem Seitenlicht im Vergleich zur flach beleuchteten äquivalenten Pose im anderen Gesichtsset, gewinnt die Qualität des Austauschs Das wäre nicht so gut, als ob alle dieselben Beleuchtungseigenschaften hätten.
Warum die Daten knapp sind
Sofern Sie nicht regelmäßig verhaftet werden, haben Sie wahrscheinlich nicht viele Seitenprofilaufnahmen von sich. Alles, was dabei herauskam, haben Sie wahrscheinlich weggeworfen. Da Bildagenturen dies ebenfalls tun, sind Profilfotos von Gesichtern schwer zu bekommen.
Deepfaker fügen häufig mehrere Kopien der begrenzten Seitenansichtsprofildaten, die sie für eine Identität haben, in einen Gesichtssatz ein, nur damit diese Pose mindestens eine erhält wenig Aufmerksamkeit und Zeit während des Trainings, anstatt als abgezinst zu werden Ausreißer.

Aber es gibt viel mehr mögliche Arten von Seitenansichts-Gesichtsbildern, als wahrscheinlich für die Aufnahme in einen Datensatz zur Verfügung stehen – lächelnd, stirnrunzelnd, schreiend, Weinen, dunkel beleuchtet, verächtlich, gelangweilt, fröhlich, blitzbeleuchtet, hoch schauen, herunterschauen, geöffnete Augen, geschlossene Augen…usw. Jede dieser Posen könnte in mehreren Kombinationen in einem Deepfake-Zielvideo erforderlich sein.
Und das sind nur Profile. Wie viele Bilder hast du von dir selbst? geradeaus? Haben Sie genug, um das umfassend darzustellen? 10,000 mögliche Ausdrücke Sie tragen möglicherweise genau diese Pose aus genau diesem Kamerawinkel und verdecken dabei zumindest einen Teil davon eine Million mögliche Beleuchtungsumgebungen?
Die Chancen stehen gut, dass Sie das nicht einmal getan haben dank One Bild von dir, wie du nach oben schaust. Und das sind nur zwei Winkel von hundert oder mehr, die für eine vollständige Abdeckung erforderlich sind.
Selbst wenn es möglich wäre, ein Gesicht aus allen Winkeln und unter verschiedenen Lichtverhältnissen vollständig abzudecken, wäre der resultierende Datensatz viel zu groß zum Trainieren und würde in der Größenordnung von Hunderttausenden Bildern liegen; und selbst wenn es könnte trainiert werden, würde die Art des Trainingsprozesses für aktuelle Deepfake-Frameworks den Großteil dieser zusätzlichen Daten zugunsten einer begrenzten Anzahl abgeleiteter Funktionen verschwenden, da die aktuellen Frameworks reduktionistisch und nicht sehr skalierbar sind.
Synthetische Substitution
Seit den Anfängen von Deepfakes experimentieren Deepfaker mit CGI-ähnlichen Bildern, Köpfen, die in 3D-Anwendungen wie Cinema4D und Maya erstellt wurden, um diese „fehlenden Posen“ zu erzeugen.
Keine KI notwendig; Eine Schauspielerin wird in einem traditionellen CGI-Programm, Cinema 4D, nachgebildet, wobei Netze und Bitmap-Texturen verwendet werden – eine Technologie, die bis in die 1960er Jahre zurückreicht, jedoch erst in den 1990er Jahren weitverbreitete Verwendung fand. Theoretisch könnte dieses Gesichtsmodell verwendet werden, um Deepfake-Quelldaten für ungewöhnliche Posen, Beleuchtungsstile und Gesichtsausdrücke zu generieren. In Wirklichkeit war es beim Deepfaking von begrenztem oder gar keinem Nutzen, da die „Fälschung“ der Renderings in den ausgetauschten Videos tendenziell durchscheint. Quelle: Bild des Autors dieses Artikels unter https://rossdawson.com/futurist/implications-of-ai/comprehensive-guide-ai-artificial-intelligence-visual-effects-vfx/
Diese Methode wird von neuen Deepfake-Anwendern im Allgemeinen frühzeitig aufgegeben, da sie zwar Posen und Ausdrücke liefern kann, die sonst nicht verfügbar wären, das synthetische Erscheinungsbild der CGI-Gesichter jedoch aufgrund der Verflechtung von ID und kontextuellen/semantischen Informationen normalerweise in die Swaps eindringt.
Dies kann zum plötzlichen Aufblitzen von „Uncanny Valley“-Gesichtern in einem ansonsten überzeugenden Deepfake-Video führen, da der Algorithmus beginnt, auf die einzigen Daten zurückzugreifen, die ihm möglicherweise für eine ungewöhnliche Pose oder einen ungewöhnlichen Ausdruck vorliegen – offensichtlich gefälschte Gesichter.

Zu den beliebtesten Motiven für Deepfaker zählt ein 3D-Deepfake-Algorithmus der australischen Schauspielerin Margot Robbie inklusive in der Standardinstallation von DeepFaceLive, einer Version von DeepFaceLab, die Deepfakes in einem Live-Stream, beispielsweise einer Webcam-Sitzung, durchführen kann. Eine CGI-Version, wie oben abgebildet, könnte verwendet werden, um ungewöhnliche „fehlende“ Winkel in Deepfake-Datensätzen zu erhalten. Source: https://sketchfab.com/3d-models/margot-robbie-bust-for-full-color-3d-printing-98d15fe0403b4e64902332be9cfb0ace
CGI-Gesichter als freistehende, konzeptionelle Leitlinien
Stattdessen ist die neue Delta-GAN Encoder (DGE)-Methode der israelischen Forscher effektiver, da die Posen- und Kontextinformationen aus den CGI-Bildern vollständig von den „Identitäts“-Informationen des Ziels getrennt wurden.
Wir können dieses Prinzip im Bild unten in Aktion sehen, wo anhand der CGI-Bilder als Richtlinie verschiedene Kopfausrichtungen ermittelt wurden. Da die Identitätsmerkmale nichts mit den kontextuellen Merkmalen zu tun haben, gibt es weder ein Durchscheinen der künstlich wirkenden synthetischen Erscheinung des CGI-Gesichts noch der darin dargestellten Identität:

Mit der neuen Methode müssen Sie nicht drei separate reale Quellbilder finden, um einen Deepfake aus mehreren Blickwinkeln darzustellen – Sie können einfach den CGI-Kopf drehen, dessen abstrakte Merkmale auf hoher Ebene auf die Identität übertragen werden, ohne dass eine ID preisgegeben wird Information.


Delta-GAN-Encoder. Gruppe oben links: Der Winkel eines Quellbilds kann in einer Sekunde geändert werden, um ein neues Quellbild zu rendern, das sich in der Ausgabe widerspiegelt; Gruppe oben rechts: Auch die Beleuchtung wird von der Identität entkoppelt, was die Überlagerung verschiedener Beleuchtungsstile ermöglicht; Gruppe unten links: Mehrere Gesichtsdetails werden verändert, um einen „traurigen“ Ausdruck zu erzeugen; Gruppe unten rechts: Ein einzelnes Gesichtsausdrucksdetail ist so verändert, dass die Augen schielen.
Diese Trennung von Identität und Kontext wird in der Trainingsphase erreicht. Die Pipeline für die neue Deepfake-Architektur sucht den latenten Vektor in einem vorab trainierten Generative Adversarial Network (GAN), der dem zu transformierenden Bild entspricht – eine Sim2Real-Methodik, die auf einer 2018er-Methode aufbaut Projekt aus der KI-Forschungsabteilung von IBM.
Die Forscher beobachten:
„Mit nur wenigen Stichproben, die sich durch ein bestimmtes Attribut unterscheiden, kann man das entwirrte Verhalten eines vorab trainierten verschränkten generativen Modells lernen.“ Um dieses Ziel zu erreichen, sind keine exakten Proben aus der realen Welt erforderlich, was nicht unbedingt realisierbar ist.
„Durch die Verwendung unrealistischer Datenproben kann das gleiche Ziel erreicht werden, indem die Semantik der codierten latenten Vektoren genutzt wird.“ „Das Anwenden gewünschter Änderungen auf vorhandene Datenproben kann ohne explizite Untersuchung des latenten Raumverhaltens erfolgen.“
Die Forscher gehen davon aus, dass die im Projekt untersuchten Kernprinzipien der Entflechtung auf andere Bereiche übertragen werden könnten, beispielsweise auf Innenarchitektursimulationen, und dass die für den Delta-GAN-Encoder übernommene Sim2Real-Methode letztendlich eine Deepfake-Instrumentalität ermöglichen könnte, die auf bloßen Skizzen basiert Eingabe im CGI-Stil.
Man könnte argumentieren, dass das Ausmaß, in dem das neue israelische System in der Lage sein könnte, Deepfake-Videos zu synthetisieren oder nicht, weitaus weniger bedeutsam ist als der Fortschritt, den die Forschung bei der Entflechtung von Kontext und Identität gemacht hat und dabei mehr Kontrolle über den latenten Raum erlangt eines GAN.
Entwirrung ist ein aktives Forschungsgebiet in der Bildsynthese; im Januar 2021, eine von Amazon durchgeführte Studie Krepppapier demonstrierte eine ähnliche Posenkontrolle und Entwirrung, und im Jahr 2018 a Krepppapier von den Shenzhen Institutes of Advanced Technology an der Chinesischen Akademie der Wissenschaften machten Fortschritte bei der Generierung willkürlicher Standpunkte in einem GAN.















