
Künstliche Intelligenz
Emotionen in Videomaterial mit KI verändern
Forscher aus Griechenland und dem Vereinigten Königreich haben einen neuartigen Deep-Learning-Ansatz entwickelt, um den Gesichtsausdruck und die scheinbare Stimmung von Menschen in Videoaufnahmen zu verändern und gleichzeitig die Wiedergabetreue ihrer Lippenbewegungen zum Originalton auf eine Weise zu bewahren, die bei früheren Versuchen nicht möglich war .

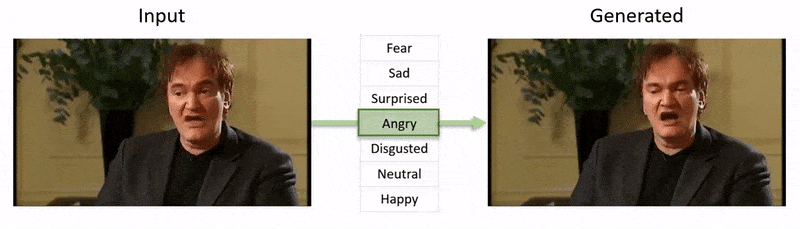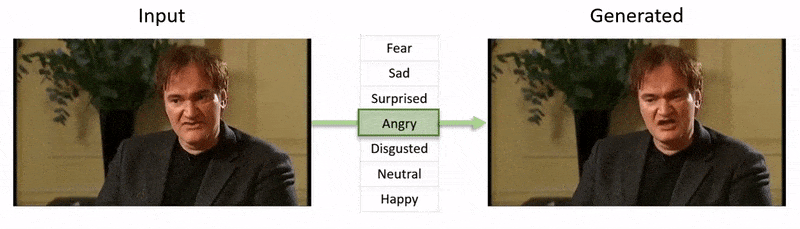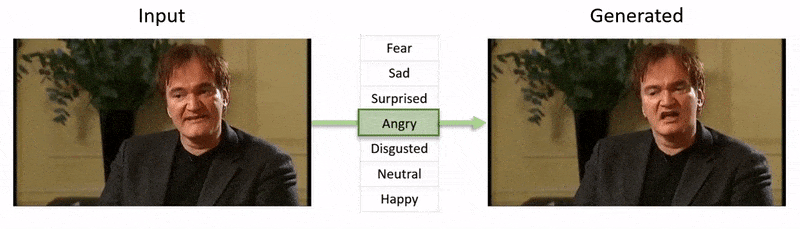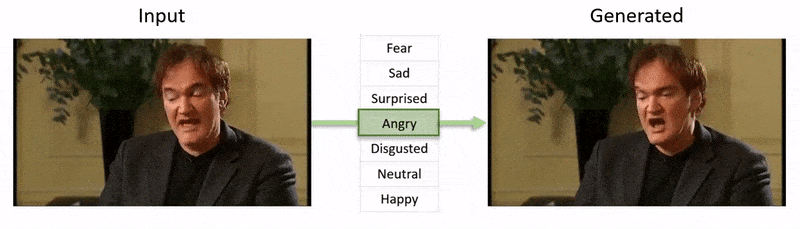
Aus dem dem Artikel beigefügten Video (am Ende dieses Artikels eingebettet) ein kurzer Clip, in dem der Gesichtsausdruck des Schauspielers Al Pacino durch NED subtil verändert wird, basierend auf hochrangigen semantischen Konzepten, die individuelle Gesichtsausdrücke und die damit verbundenen Emotionen definieren. Die „referenzgesteuerte“ Methode auf der rechten Seite nimmt die interpretierten Emotionen eines Quellvideos und wendet sie auf die gesamte Videosequenz an. Quelle: https://www.youtube.com/watch?v=Li6W8pRDMJQ
Dieses spezielle Feld fällt in die wachsende Kategorie von gefälschte Emotionen, wobei die Identität des ursprünglichen Sprechers erhalten bleibt, seine Ausdrücke und Mikroausdrücke jedoch verändert werden. Mit zunehmender Reife dieser speziellen KI-Technologie bietet sie Film- und Fernsehproduktionen die Möglichkeit, subtile Änderungen am Gesichtsausdruck von Schauspielern vorzunehmen – eröffnet aber auch eine ziemlich neue Kategorie von „emotionsveränderten“ Video-Deepfakes.
Changing Faces
Gesichtsausdrücke von Persönlichkeiten des öffentlichen Lebens, wie z. B. Politikern, werden streng kuratiert; Im Jahr 2016 kam die Mimik von Hillary Clinton zum Vorschein unter intensiver Medienbeobachtung wegen ihrer möglichen negativen Auswirkungen auf ihre Wahlaussichten; Gesichtsausdrücke, so stellt sich heraus, sind ebenfalls ein Thema von Interesse an das FBI; und sie sind ein kritischer Indikator in Vorstellungsgesprächen, was die (noch weit entfernte) Aussicht auf einen Live-Filter zur Ausdruckskontrolle zu einer wünschenswerten Entwicklung für Arbeitssuchende macht, die versuchen, eine Vorprüfung bei Zoom zu bestehen.
Eine Studie aus Großbritannien aus dem Jahr 2005 bestätigte dieses Gesichtsaussehen wirkt sich auf Wahlentscheidungen aus, während ein Feature der Washington Post aus dem Jahr 2019 das untersuchte Verwendung von „aus dem Kontext gerissenen“ Videoclip-Sharing, was für Fake-News-Befürworter derzeit am nächsten kommt, wenn es darum geht, tatsächlich das Verhalten, die Reaktionen oder die Gefühle einer Person des öffentlichen Lebens zu verändern.
Auf dem Weg zur Manipulation neuronaler Ausdrücke
Derzeit ist der Stand der Technik bei der Manipulation von Gesichtsauswirkungen recht rudimentär, da es sich dabei um die Bewältigung von Gesichtsausdrücken handelt Entwirrung von übergeordneten Konzepten (z traurig, wütend, glücklich, lächelnd) aus tatsächlichen Videoinhalten. Obwohl traditionelle Deepfake-Architekturen diese Entwirrung offenbar recht gut bewerkstelligen, erfordert die Spiegelung von Emotionen über verschiedene Identitäten hinweg immer noch, dass zwei Trainingsgesichtssätze passende Ausdrücke für jede Identität enthalten.

Typische Beispiele für Gesichtsbilder in Datensätzen, die zum Trainieren von Deepfakes verwendet werden. Derzeit können Sie den Gesichtsausdruck einer Person nur manipulieren, indem Sie ID-spezifische Ausdruckspfade in einem Deepfake-Neuronalen Netzwerk erstellen. Deepfake-Software aus dem Jahr 2017 verfügt über kein intrinsisches, semantisches Verständnis eines „Lächelns“ – sie ordnet lediglich wahrgenommene Veränderungen in der Gesichtsgeometrie der beiden Probanden zu und gleicht sie ab.
Was wünschenswert ist, aber noch nicht perfekt erreicht wurde, ist zu erkennen, wie Subjekt B (zum Beispiel) lächelt, und einfach ein Lächeln zu erzeugen 'lächeln' Wechseln Sie in der Architektur, ohne sie einem äquivalenten Bild des lächelnden Subjekts A zuordnen zu müssen.
Das neues Papier ist betitelt Neural Emotion Director: Spracherhaltende semantische Kontrolle von Gesichtsausdrücken in „In-the-Wild“-Videos, und stammt von Forschern der School of Electrical & Computer Engineering der Nationalen Technischen Universität Athen, des Institute of Computer Science der Foundation for Research and Technology Hellas (FORTH) und des College of Engineering, Mathematics and Physical Sciences der Universität Exeter im Vereinigten Königreich.
Das Team hat ein Framework namens entwickelt Direktor für neuronale Emotionen (NED), das ein 3D-basiertes Emotionsübersetzungsnetzwerk integriert, 3D-basierter Emotionsmanipulator.
NED nimmt eine empfangene Folge von Ausdrucksparametern und übersetzt sie in eine Zieldomäne. Das Training basiert auf unparallelen Daten, was bedeutet, dass es nicht notwendig ist, auf Datensätzen zu trainieren, bei denen jede Identität über entsprechende Gesichtsausdrücke verfügt.
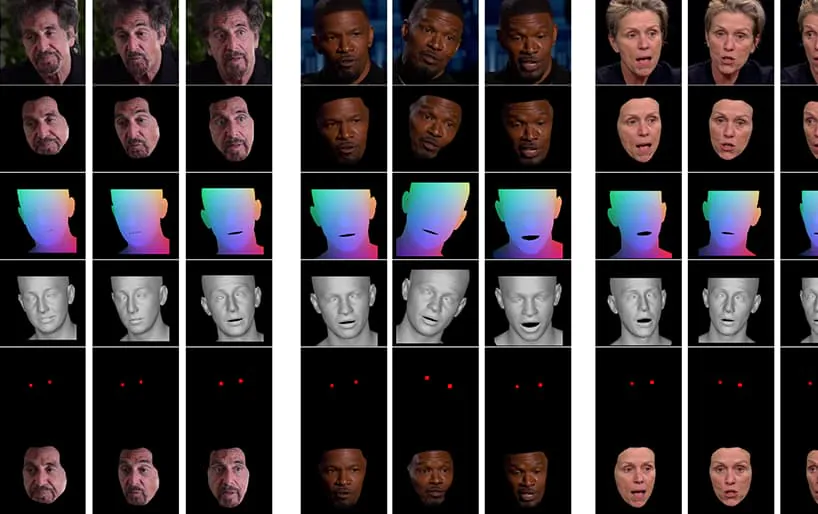
Das am Ende dieses Artikels gezeigte Video durchläuft eine Reihe von Tests, bei denen NED dem Filmmaterial aus dem YouTube-Datensatz einen scheinbaren emotionalen Zustand auferlegt.
Die Autoren behaupten, dass NED die erste videobasierte Methode sei, um Schauspieler in zufälligen und unvorhersehbaren Situationen zu „leiten“, und haben den Code auf NEDs verfügbar gemacht Projekt-Seite.
Methode und Architektur
Das System wird anhand von zwei großen Videodatensätzen trainiert, die mit „Emotions“-Labels versehen wurden.
Die Ausgabe wird durch einen Video-Gesichtsrenderer ermöglicht, der die gewünschte Emotion mithilfe herkömmlicher Gesichtsbildsynthesetechniken, einschließlich Gesichtssegmentierung, Ausrichtung und Überblendung von Gesichtsmarkierungen, in ein Video umwandelt, wobei nur der Gesichtsbereich synthetisiert und dann dem Originalmaterial überlagert wird.

Die Architektur für die Pipeline des Neural Emotion Detector (NED). Quelle: https://arxiv.org/pdf/2112.00585.pdf
Zunächst erhält das System eine 3D-Gesichtswiederherstellung und ordnet den Eingabebildern Gesichtsmarkierungsausrichtungen zu, um den Gesichtsausdruck zu identifizieren. Anschließend werden diese wiederhergestellten Ausdrucksparameter an den 3D-basierten Emotionsmanipulator übergeben und ein Stilvektor mithilfe einer semantischen Bezeichnung (z. B. „glücklich“) oder einer Referenzdatei berechnet.
Eine Referenzdatei ist ein Video, das einen bestimmten erkannten Ausdruck/ein bestimmtes Gefühl darstellt, das dann auf das gesamte Zielvideo überlagert wird und den ursprünglichen Ausdruck ersetzt.

Phasen in der Emotionsübertragungspipeline mit verschiedenen Schauspielern, die aus YouTube-Videos ausgewählt wurden.
Die endgültig generierte 3D-Gesichtsform wird dann mit der normalisierten mittleren Gesichtskoordinate (NMFC) und den Augenbildern (die roten Punkte im Bild oben) verkettet und an den neuronalen Renderer übergeben, der die endgültige Manipulation durchführt.
Die Ergebnisse
Die Forscher führten umfangreiche Studien durch, darunter Benutzer- und Ablationsstudien, um die Wirksamkeit der Methode im Vergleich zu früheren Arbeiten zu bewerten, und stellten fest, dass NED in den meisten Kategorien den aktuellen Stand der Technik in diesem Teilbereich der neuronalen Gesichtsmanipulation übertrifft.

Die Autoren des Papiers gehen davon aus, dass spätere Implementierungen dieser Arbeit und Tools ähnlicher Art vor allem in der Fernseh- und Filmindustrie nützlich sein werden, und erklären:
„Unsere Methode eröffnet eine Fülle neuer Möglichkeiten für nützliche Anwendungen neuronaler Rendering-Technologien, die von der Filmpostproduktion und Videospielen bis hin zu fotorealistischen affektiven Avataren reichen.“
Dies ist eine frühe Arbeit auf diesem Gebiet, aber eine der ersten, die eine Gesichtsnachstellung mit Video statt mit Standbildern versucht. Obwohl es sich bei Videos im Wesentlichen um viele Standbilder handelt, die sehr schnell zusammenlaufen, gibt es zeitliche Überlegungen, die frühere Anwendungen der Emotionsübertragung weniger effektiv machen. Im begleitenden Video und in den Beispielen im Artikel fügen die Autoren visuelle Vergleiche der Ergebnisse von NED mit anderen vergleichbaren neueren Methoden hinzu.

Ausführlichere Vergleiche und viele weitere Beispiele für NED finden Sie im vollständigen Video unten:
![[CVPR 2022] NED: Speech-preserving semantic control of facial expressions in “in-the-wild” videos](https://www.unite.ai/wp-content/plugins/wp-youtube-lyte/lyteCache.php?origThumbUrl=https%3A%2F%2Fi.ytimg.com%2Fvi%2FLi6W8pRDMJQ%2F0.jpg)
3. Dezember 2021, 18:30 GMT+2 – Auf Wunsch eines der Autoren des Papiers wurden Korrekturen an der „Referenzdatei“ vorgenommen, bei der es sich meiner Meinung nach fälschlicherweise um ein Standbild handelte (wobei es sich in Wirklichkeit um einen Videoclip handelt). Außerdem eine Namensänderung des Instituts für Informatik der Stiftung für Forschung und Technologie.
3. Dezember 2021, 20:50 GMT+2 – Eine zweite Anfrage von einem der Autoren des Papiers um eine weitere Änderung des Namens der oben genannten Institution.















