AI 101
Hvad er Bayes’ Teorem?
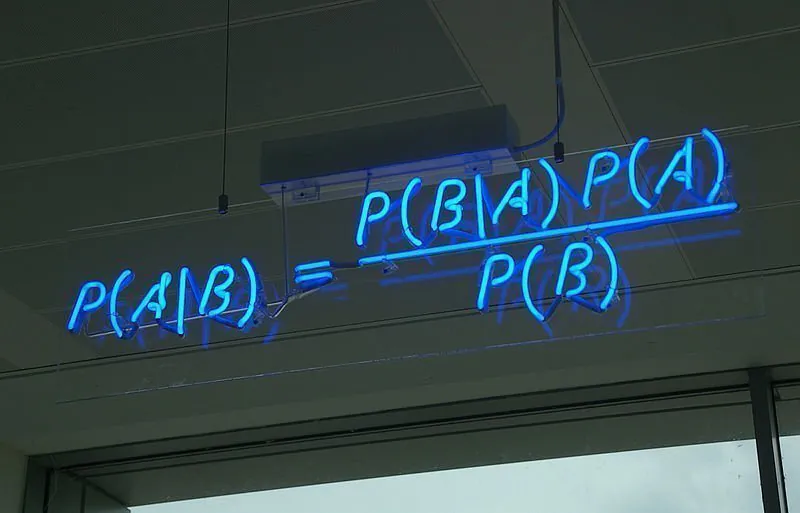
Hvis du har lært om datavidenskab eller maskinlæring, er der en god chance, du har hørt udtrykket “Bayes’ Teorem” før, eller en “Bayes-klassifikator”. Disse begreber kan være lidt forvirrende, især hvis du ikke er vant til at tænke på sandsynlighed fra et traditionelt, frekventistisk statistikperspektiv. Denne artikel vil forsøge at forklare principperne bag Bayes’ Teorem og hvordan det bruges i maskinlæring.
Hvad er Bayes’ Teorem?
Bayes’ Teorem er en metode til at beregne betinget sandsynlighed. Den traditionelle metode til at beregne betinget sandsynlighed (sandsynligheden for, at et begivenhed indtræffer, givet, at en anden begivenhed indtræffer) er at bruge betinget sandsynlighedsformlen, ved at beregne den samlede sandsynlighed for begivenhed én og begivenhed to, og derefter dividere det med sandsynligheden for begivenhed to. Men betinget sandsynlighed kan også beregnes på en lidt anden måde ved hjælp af Bayes’ Teorem.
Når du beregner betinget sandsynlighed med Bayes’ teorem, følger du disse trin:
- Bestem sandsynligheden for, at betingelse B er sand, givet, at betingelse A er sand.
- Bestem sandsynligheden for, at begivenhed A er sand.
- Gang de to sandsynligheder sammen.
- Dividér med sandsynligheden for, at begivenhed B indtræffer.
Dette betyder, at formlen for Bayes’ Teorem kan udtrykkes således:
P(A|B) = P(B|A)*P(A) / P(B)
At beregne betinget sandsynlighed på denne måde er især nyttigt, når den omvendte betingede sandsynlighed kan beregnes let, eller når beregning af den samlede sandsynlighed ville være for udfordrende.
Eksempel på Bayes’ Teorem
Dette kan være lettere at forstå, hvis vi bruger lidt tid på at se på et eksempel på, hvordan man kan anvende bayesisk tankegang og Bayes’ Teorem. Lad os antage, du spiller et simpelt spil, hvor flere deltagere fortæller dig en historie, og du skal bestemme, hvem af deltagerne, der lyver for dig. Lad os udfylde ligningen for Bayes’ Teorem med variablerne i dette hypotetiske scenarie.
Vi prøver at forudsige, om hver enkelt person i spillet lyver eller siger sandheden, så hvis der er tre spillere ud over dig, kan de kategoriske variabler udtrykkes som A1, A2 og A3. Beviset for deres løgne/sandheden er deres adfærd. Ligesom når du spiller poker, ville du lede efter visse “tegn” på, at en person lyver, og bruge disse oplysninger til at informere din gæt. Eller hvis du var tilladt at stille dem spørgsmål, ville det være enhver bevis for, at deres historie ikke stemmer overens. Vi kan repræsentere beviset for, at en person lyver, som B.
For at gøre det klart, prøver vi at forudsige Sandsynligheden for, at A lyver/siger sandheden|givet beviset for deres adfærd. For at gøre dette ville vi gerne vide sandsynligheden for B givet A, eller sandsynligheden for, at deres adfærd ville optræde, givet, at personen virkelig lyver eller siger sandheden. Du prøver at bestemme under hvilke betingelser, den adfærd du ser, ville have mest mening. Hvis der er tre adfærdsformer, du observerer, ville du udføre beregningen for hver adfærd. For eksempel P(B1, B2, B3 * A). Du ville så gøre dette for hver forekomst af A/for hver person i spillet ud over dig selv. Det er denne del af ligningen ovenfor:
P(B1, B2, B3,|A) * P|A
Til sidst dividerer vi bare med sandsynligheden for B.
Hvis vi modtog nogen oplysninger om de faktiske sandsynligheder i denne ligning, ville vi genskabe vores sandsynlighedsmodel, ved at tage den nye information i betragtning. Dette kaldes opdatering af vores a priori, da vi opdaterer vores antagelser om den a priori sandsynlighed for de observerede begivenheders forekomst.
Maskinlæringsapplikationer for Bayes’ Teorem
Den mest almindelige brug af Bayes’ Teorem i forbindelse med maskinlæring er i form af Naive Bayes-algoritmen.
Naive Bayes bruges til klassificering af både binære og multi-klassedatasets, Naive Bayes får sit navn, fordi de værdier, der tildèles vidnernes bevis/attributter – Bs i P(B1, B2, B3 * A) – antages at være uafhængige af hinanden. Det antages, at disse attributter ikke påvirker hinanden for at simplificere modellen og gøre beregninger mulige, i stedet for at forsøge at beregne relationerne mellem hvert af attributterne. Trods denne simplificerede model, tenderer Naive Bayes til at fungere ret godt som en klassificeringsalgoritme, selv når denne antagelse sandsynligvis ikke er sand (hvad det er mest af tiden).
Der er også almindeligt brugte varianter af Naive Bayes-klassifikatoren, såsom Multinomial Naive Bayes, Bernoulli Naive Bayes og Gaussian Naive Bayes.
Multinomial Naive Bayes-algoritmer bruges ofte til at klassificere dokumenter, da det er effektivt til at fortolke hyppigheden af ord inden for et dokument.
Bernoulli Naive Bayes fungerer på samme måde som Multinomial Naive Bayes, men forudsigelserne, der genereres af algoritmen, er booleske. Dette betyder, at når du forudsiger en klasse, vil værdierne være binære, nej eller ja. I tekstklassificeringens domæne ville en Bernoulli Naive Bayes-algoritme tildele parametrene et ja eller nej, afhængigt af, om et ord er fundet i tekstdokumentet eller ej.
Hvis værdien af forudsagningsvariablerne ikke er diskrete, men i stedet kontinuerte, kan Gaussian Naive Bayes bruges. Det antages, at værdierne af de kontinuerte funktioner er samplet fra en gaussisk distribution.












