
AI 101
Hvad er et beslutningstræ?
Hvad er et beslutningstræ?
A beslutning træ er en nyttig maskinlæringsalgoritme, der bruges til både regressions- og klassifikationsopgaver. Navnet "beslutningstræ" kommer af, at algoritmen bliver ved med at dele datasættet ned i mindre og mindre portioner, indtil dataene er blevet opdelt i enkelte instanser, som derefter klassificeres. Hvis du skulle visualisere resultaterne af algoritmen, ville den måde, kategorierne er opdelt på, ligne et træ og mange blade.
Det er en hurtig definition af et beslutningstræ, men lad os tage et dybt dyk ned i, hvordan beslutningstræer fungerer. At have en bedre forståelse af, hvordan beslutningstræer fungerer, såvel som deres anvendelsessager, vil hjælpe dig med at vide, hvornår du skal bruge dem under dine maskinlæringsprojekter.
Format af et beslutningstræ
Et beslutningstræ er meget som et flowchart. For at bruge et flowchart starter du ved startpunktet, eller roden, af diagrammet og derefter, baseret på hvordan du besvarer filtreringskriterierne for den startknude, flytter du til en af de næste mulige noder. Denne proces gentages, indtil en afslutning er nået.
Beslutningstræer fungerer i det væsentlige på samme måde, hvor hver interne knude i træet er en slags test-/filtreringskriterier. Noderne på ydersiden, træets endepunkter, er etiketterne for det pågældende datapunkt, og de kaldes "blade". De grene, der fører fra de interne knudepunkter til den næste knude, er træk eller konjunktioner af træk. Reglerne, der bruges til at klassificere datapunkterne, er stierne, der løber fra roden til bladene.
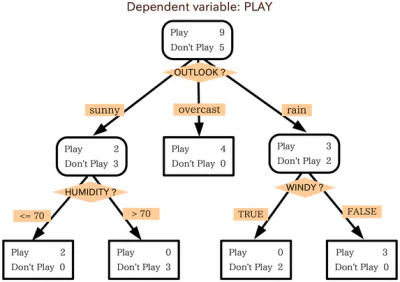
Algoritmer til beslutningstræer
Beslutningstræer opererer efter en algoritmisk tilgang, som opdeler datasættet i individuelle datapunkter baseret på forskellige kriterier. Disse opdelinger udføres med forskellige variabler eller de forskellige funktioner i datasættet. For eksempel, hvis målet er at bestemme, om en hund eller kat bliver beskrevet af inputfunktionerne, kan variabler, som dataene er opdelt på, være ting som "kløer" og "gøen".
Så hvilke algoritmer bruges til faktisk at opdele dataene i grene og blade? Der er forskellige metoder, der kan bruges til at flække et træ op, men den mest almindelige metode til at flække er nok en teknik, der omtales som "rekursiv binær opdeling”. Når du udfører denne opdelingsmetode, starter processen ved roden, og antallet af funktioner i datasættet repræsenterer det mulige antal mulige opdelinger. En funktion bruges til at bestemme, hvor meget nøjagtighed hver mulig opdeling vil koste, og opdelingen foretages ved at bruge de kriterier, der ofrer den mindste nøjagtighed. Denne proces udføres rekursivt, og undergrupper dannes efter den samme generelle strategi.
For at bestemme omkostningerne ved opdelingen, bruges en omkostningsfunktion. En anden omkostningsfunktion bruges til regressionsopgaver og klassifikationsopgaver. Målet med begge omkostningsfunktioner er at bestemme, hvilke grene der har de mest ens svarværdier eller de mest homogene grene. Overvej, at du ønsker, at testdata fra en bestemt klasse skal følge bestemte stier, og det giver intuitiv mening.
Med hensyn til regressionsomkostningsfunktionen for rekursiv binær opdeling er algoritmen, der bruges til at beregne omkostningerne, som følger:
sum(y – forudsigelse)^2
Forudsigelsen for en bestemt gruppe af datapunkter er gennemsnittet af svarene fra træningsdataene for den gruppe. Alle datapunkter køres gennem omkostningsfunktionen for at bestemme omkostningerne for alle de mulige opdelinger, og opdelingen med den laveste pris vælges.
Med hensyn til omkostningsfunktionen til klassificering er funktionen som følger:
G = sum(pk * (1 – pk))
Dette er Gini-scoren, og det er et mål for effektiviteten af en opdeling, baseret på hvor mange forekomster af forskellige klasser, der er i grupperne, der er resultatet af opdelingen. Det kvantificerer med andre ord, hvor blandede grupperne er efter opdelingen. En optimal opdeling er, når alle grupperne, der er et resultat af opdelingen, kun består af input fra én klasse. Hvis en optimal opdeling er blevet oprettet, vil "pk"-værdien være enten 0 eller 1, og G vil være lig nul. Du kan måske gætte, at den værst tænkelige opdeling er en, hvor der er en 50-50 repræsentation af klasserne i opdelingen, i tilfælde af binær klassifikation. I dette tilfælde ville "pk"-værdien være 0.5 og G ville også være 0.5.
Opsplitningsprocessen afsluttes, når alle datapunkter er blevet omdannet til blade og klassificeret. Det kan dog være en god idé at stoppe træets vækst tidligt. Store komplekse træer er tilbøjelige til at overmontere, men flere forskellige metoder kan bruges til at bekæmpe dette. En metode til at reducere overfitting er at angive et minimumsantal af datapunkter, der skal bruges til at skabe et blad. En anden metode til at kontrollere for overfitting er at begrænse træet til en vis maksimal dybde, som styrer, hvor længe en sti kan strække sig fra roden til et blad.
En anden proces involveret i oprettelsen af beslutningstræer er beskæring. Beskæring kan hjælpe med at øge ydeevnen af et beslutningstræ ved at fjerne grene, der indeholder funktioner, der har ringe forudsigelseskraft/lille betydning for modellen. På denne måde reduceres træets kompleksitet, det bliver mindre tilbøjeligt til at overfitte, og modellens prædiktive anvendelighed øges.
Ved beskæring kan processen starte enten i toppen af træet eller i bunden af træet. Den nemmeste metode til beskæring er dog at starte med bladene og forsøge at droppe den node, der indeholder den mest almindelige klasse i det blad. Hvis modellens nøjagtighed ikke forringes, når dette er gjort, bevares ændringen. Der er andre teknikker, der bruges til at udføre beskæring, men metoden beskrevet ovenfor – reduceret fejlbeskæring – er nok den mest almindelige metode til beslutningstræbeskæring.
Overvejelser ved brug af beslutningstræer
Beslutning træer er ofte nyttige når klassificering skal udføres, men beregningstiden er en stor begrænsning. Beslutningstræer kan gøre det klart, hvilke funktioner i de valgte datasæt, der har den mest forudsigelige kraft. Desuden, i modsætning til mange maskinlæringsalgoritmer, hvor reglerne, der bruges til at klassificere dataene, kan være svære at fortolke, kan beslutningstræer gengive fortolkbare regler. Beslutningstræer er også i stand til at gøre brug af både kategoriske og kontinuerte variable, hvilket betyder, at der kræves mindre forbehandling, sammenlignet med algoritmer, der kun kan håndtere en af disse variabeltyper.
Beslutningstræer har en tendens til ikke at fungere særlig godt, når de bruges til at bestemme værdierne af kontinuerlige attributter. En anden begrænsning af beslutningstræer er, at når der udføres klassificering, hvis der er få træningseksempler, men mange klasser, har beslutningstræet en tendens til at være unøjagtigt.










