
Umělá inteligence
GOTCHA – CAPTCHA systém pro živé Deepfakes

Nový výzkum z New York University přidává k rostoucím náznakům, že možná brzy budeme muset podstoupit hluboký falešný ekvivalent „opileckého testu“, abychom se mohli ověřit před zahájením citlivého videohovoru – jako je videokonference související s prací nebo jakákoli jiná jiný citlivý scénář, který může přilákat podvodníky k používání deepfake v reálném čase streamovací software.

Některé z aktivních a pasivních výzev aplikovaných na scénáře videohovorů v GOTCHA. Uživatel musí výzvy splnit a projít je, zatímco se používají další „pasivní“ metody (jako je pokus o přetížení potenciálního deepfake systému), na které nemá účastník žádný vliv. Zdroj: http://export.arxiv.org/pdf/2210.06186
Navrhovaný systém je nazván GOTCHA – pocta systémům CAPTCHA, které se za posledních 10–15 let staly stále větší překážkou při procházení webu, kde automatizované systémy vyžadují, aby uživatel prováděl úkoly, ve kterých jsou stroje špatné, jako je identifikace zvířat. nebo dešifrování zkomoleného textu (a ironicky tyto výzvy často obrací uživatele do volného AMT-styl outsourcovaný anotátor).
GOTCHA v podstatě prodlužuje srpen 2022 DF-Captcha papír z Ben-Gurionovy univerzity, který jako první navrhl, aby osoba na druhém konci hovoru proskočila několik vizuálně sémantických obručí, aby prokázala svou pravost.

Dokument ze srpna 2022 od Ben Gurion University nejprve navrhl řadu interaktivních testů pro uživatele, včetně okluze obličeje nebo dokonce deprimování kůže – úkoly, které ani dobře vyškolené živé deepfake systémy nemusely předvídat nebo by se s nimi nebyly schopny fotorealisticky vypořádat. . Zdroj: https://arxiv.org/pdf/2208.08524.pdf
Je pozoruhodné, že GOTCHA přidává „pasivní“ metodologie ke „kaskádě“ navrhovaných testů, včetně automatického překrývání nereálných prvků na tváři uživatele a „přetížení“ snímků procházejících zdrojovým systémem. Bez zvláštních oprávnění pro přístup k místnímu systému uživatele však mohou být vyhodnoceny pouze úlohy reagující na uživatele – což by pravděpodobně přicházelo ve formě místních modulů nebo doplňků k oblíbeným systémům, jako je Skype a Zoom, nebo dokonce v formou specializovaného proprietárního softwaru, který má za úkol vymýtit padělky.
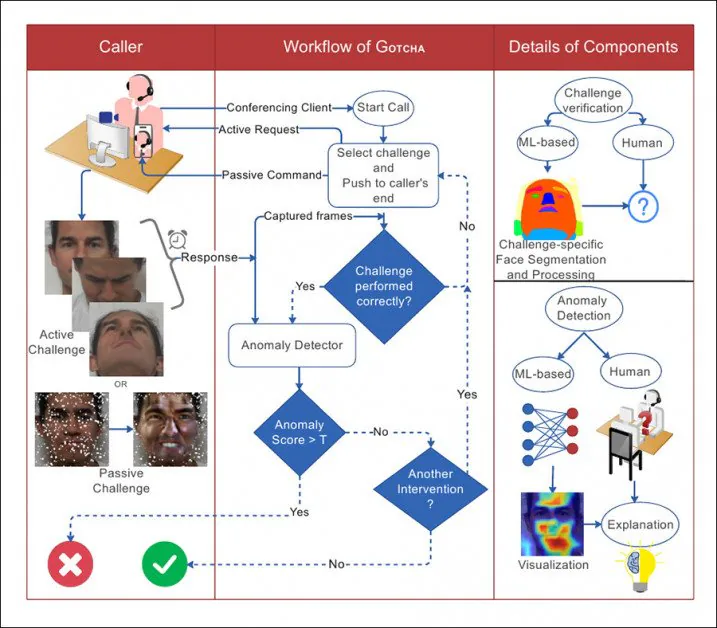
Z papíru, ilustrace interakce mezi volajícím a systémem v GOTCHA, s tečkovanými čarami při rozhodování.
Výzkumníci ověřili systém na novém datovém souboru obsahujícím více než 2.5 m video snímků od 47 účastníků, z nichž každý provedl 13 výzev od GOTCHA. Tvrdí, že rámec navozuje „konzistentní a měřitelné“ snížení kvality hluboce falešného obsahu pro podvodné uživatele a zatěžuje místní systém, dokud zjevné artefakty neujasní klam pouhým lidským okem (ačkoli GOTCHA obsahuje také některé jemnější metody algoritmické analýzy).
Projekt nový papír je s názvem Gotcha: Systém výzvy a odezvy pro detekci hlubokého falšování v reálném čase (název systému je v těle uveden velkými písmeny, nikoli však název publikace, i když to není zkratka).
Řada výzev
Většinou v souladu s dokumentem Ben Gurion jsou skutečné výzvy, kterým čelí uživatel, rozděleny do několika typů úkolů.
Pro okluze, uživatel musí buď zakrýt svůj obličej rukou nebo jinými předměty, nebo prezentovat svůj obličej pod úhlem, u kterého není pravděpodobné, že by byl natrénován do deepfake modelu (obvykle kvůli nedostatku trénovacích dat pro ' liché pozice – viz rozsah obrázků na prvním obrázku výše).
Kromě akcí, které může uživatel provést sám v souladu s pokyny, může GOTCHA překrývat náhodné výřezy obličeje, nálepky a filtry rozšířené reality, aby „narušil“ proud obličeje, který může místní vyškolený deepfake model očekávat, a způsobí jeho selhání. . Jak již bylo naznačeno dříve, ačkoli se jedná o „pasivní“ proces pro uživatele, je rušivý pro software, který musí být schopen zasahovat přímo do proudu koncového korespondenta.
Dále může být po uživateli požadováno, aby nastavil svou tvář do neobvyklých výrazů obličeje, které pravděpodobně buď chybí, nebo jsou nedostatečně zastoupeny v jakékoli trénovací datové sadě, což způsobí snížení kvality hluboce zfalšovaného výstupu (obrázek „b“, druhý sloupec zleva , na prvním obrázku výše).
V rámci tohoto řetězce testů může být uživatel požádán, aby přečetl text nebo zahájil konverzaci, která je navržena tak, aby zpochybnila místní živý systém hlubokého předstírání, který nemusí natrénovat adekvátní rozsah fonémů nebo jiných typů ústních dat na úroveň. kde dokáže rekonstruovat přesný pohyb rtů pod takovým drobnohledem.
Konečně (a zdá se, že tento zpochybňuje herecký talent koncového zpravodaje), v této kategorii může být uživatel požádán, aby provedl mikrovýraz“ – krátký a mimovolný výraz obličeje, který je v rozporu s emocí. O tom píše list „[to] obvykle trvá 0.5–4.0 sekundy a je těžké to předstírat“.
Ačkoli článek nepopisuje, jak extrahovat mikrovýraz, logika naznačuje, že jediným způsobem, jak to udělat, je vytvořit v koncovém uživateli vhodnou emoci, možná s nějakým druhem překvapivého obsahu, který jim bude předložen jako součást rutiny testu. .

Zkreslení obličeje, osvětlení a Nečekaní hosté
Kromě toho, v souladu s návrhy ze srpnového dokumentu, nová práce navrhuje požádat koncového uživatele, aby provedl neobvyklé deformace obličeje a manipulace, jako je vtlačení prstu do tváře, interakce s obličejem a/nebo vlasy a provádění jiných pohyby, které žádný současný živý deepfake systém pravděpodobně nebude schopen dobře zvládnout, protože se jedná o okrajové akce – i kdyby byly přítomny v trénovací datové sadě, jejich reprodukce by pravděpodobně měla nízkou kvalitu, v souladu s jinými „odlehlými“ daty.
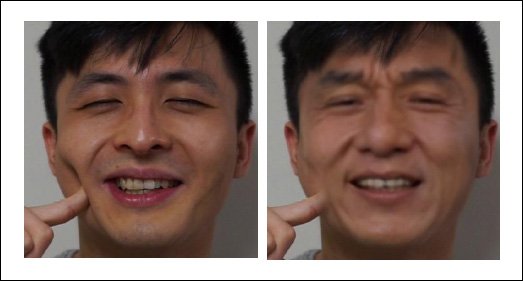
Úsměv, ale tento „depresivní obličej“ není dobře přeložen místním živým deepfake systémem.
Další výzva spočívá ve změně světelných podmínek, ve kterých se koncový uživatel nachází, protože je možné, že trénování deepfake modelu bylo optimalizováno na standardní světelné situace videokonference nebo dokonce na přesné světelné podmínky, ve kterých hovor probíhá. .
Uživatel tak může být požádán, aby si posvítil baterkou na svůj mobilní telefon na obličej nebo nějakým jiným způsobem změnil osvětlení (a stojí za zmínku, že tento způsob je ústředním návrhem další živý detekce deepfake papíru který vyšel letos v létě).

Živé deepfake systémy jsou zpochybněny neočekávaným osvětlením – a dokonce i více lidmi ve streamu, kde bylo očekáváno pouze jediného jednotlivce.
V případě navrhovaného systému, který má schopnost zasahovat do místního uživatelského proudu (který je podezřelý z toho, že ukrývá deepfake prostředníka), přidání neočekávaných vzorů (viz prostřední sloupec na obrázku výše) může ohrozit schopnost deepfake algoritmu udržovat simulaci. .
Navíc, i když je nerozumné očekávat, že korespondent bude mít po ruce další lidi, kteří jim pomohou ověřit jejich pravost, systém může vložit další tváře (obrázek vpravo nahoře) a zjistit, zda nějaký místní hluboce falešný systém neudělá chybu, když přepne pozornost – nebo dokonce se je snaží všechny hluboce zfalšovat (systémy hloubkových falešných kódů s automatickým kódováním nemají žádné schopnosti „rozpoznávání identity“, které by v tomto scénáři mohly udržet pozornost zaměřenou na jednoho jedince).
Steganografie a přetížení
GOTCHA také zahrnuje přístup nejprve navrženo od UC San Diego v dubnu tohoto roku a která používá steganografii k zašifrování zprávy do místního video streamu uživatele. Rutiny Deepfake tuto zprávu zcela zničí, což povede k selhání ověřování.
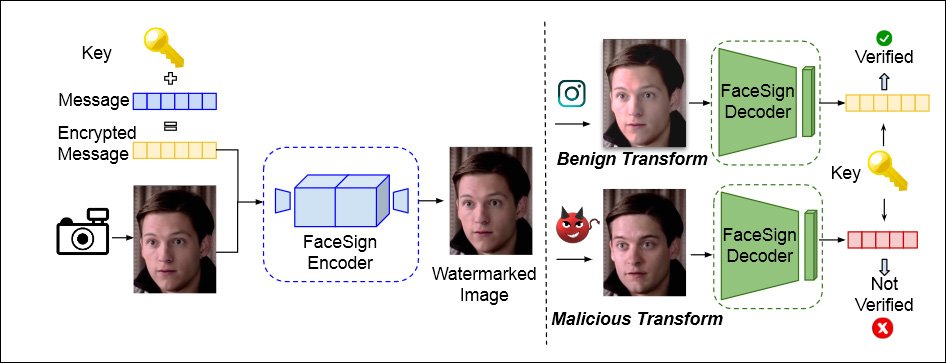
Z dokumentu z dubna 2022 z Kalifornské univerzity v San Diegu a Státní univerzity v San Diegu, metoda určování autentické identity tím, že se zjistí, zda steganografický signál odeslaný do video streamu uživatele přežije místní smyčku nedotčenou – pokud ne, hluboká šikana může být po ruce. Zdroj: https://arxiv.org/pdf/2204.01960.pdf
Kromě toho je GOTCHA schopna přetížit místní systém (s daným přístupem a oprávněním) tím, že duplikuje stream a předloží „nadměrná“ data jakémukoli místnímu systému, což je navrženo tak, aby způsobilo selhání replikace v místním deepfake systému.
Systém obsahuje další testy (podrobnosti viz dokument), včetně výzvy, v případě korespondenta založeného na chytrém telefonu, obrátit svůj telefon vzhůru nohama, což naruší místní deepfake systém:

Opět platí, že tento druh věcí by fungoval pouze s přesvědčivým případem použití, kdy je uživatel nucen udělit místní přístup ke streamu a nelze jej implementovat prostým pasivním vyhodnocením uživatelského videa, na rozdíl od interaktivních testů (např. prstem do obličeje).
Praktičnost
Příspěvek se stručně zmiňuje o tom, do jaké míry mohou testy tohoto charakteru konečného uživatele obtěžovat, nebo je nějakým způsobem obtěžovat – například tím, že uživateli ukládá povinnost mít po ruce řadu předmětů, které mohou být pro testy potřeba, jako jsou sluneční brýle.
Rovněž uznává, že může být obtížné získat výkonné korespondenty, aby vyhověli testovacím postupům. K případu videohovoru s generálním ředitelem autoři uvádějí:
„Použitelnost zde může být klíčová, takže neformální nebo frivolní výzvy (jako jsou deformace obličeje nebo výrazy) nemusí být vhodné. Výzvy využívající externí fyzické předměty nemusí být žádoucí. Kontext je vhodně upraven a GOTCHA tomu přizpůsobí svou sadu výzev.“
Data a testy
GOTCHA byla testována proti čtyřem kmenům místního živého deepfake systému, včetně dvou variací na velmi populární tvůrce deepfakes autoencoderu DeepFaceLab („DFL“ se však překvapivě nezmiňuje DeepFaceLive, která byla, od srpna 2021, „živá“ implementace DeepFaceLab a zdá se nejpravděpodobnější počáteční zdroj pro potenciálního podvodníka).
Čtyři systémy byly DFL trénovány 'lehce' na neslavné osobě účastnící se testů a spárované celebritě; DFL trénoval úplněji, na 2m+ iterací nebo kroků, kde by se dalo očekávat mnohem výkonnější model; Animátor latentního obrazu (LIA); a Generativní adversariální síť pro výměnu obličejů (FSGAN).
Pro data výzkumníci zachytili a upravili výše uvedené videoklipy, které představovaly 47 uživatelů provádějících 13 aktivních výzev, přičemž každý uživatel vytvořil přibližně 5–6 minut videa v rozlišení 1080p při 60 snímcích za sekundu. Autoři také uvádějí, že tato data budou nakonec zveřejněna.
Detekce anomálií může být prováděna buď lidským pozorovatelem, nebo algoritmicky. Pro druhou možnost byl systém trénován na 600 obličejích ze společnosti Datová sada FaceForensics. Funkce ztráty regrese byla výkonná podobnost LPIPS (Learned Perceptual Image Patch Similarity), zatímco k trénování klasifikátoru byla použita binární křížová entropie. Vlastní kamera byl použit k vizualizaci hmotnosti detektoru.
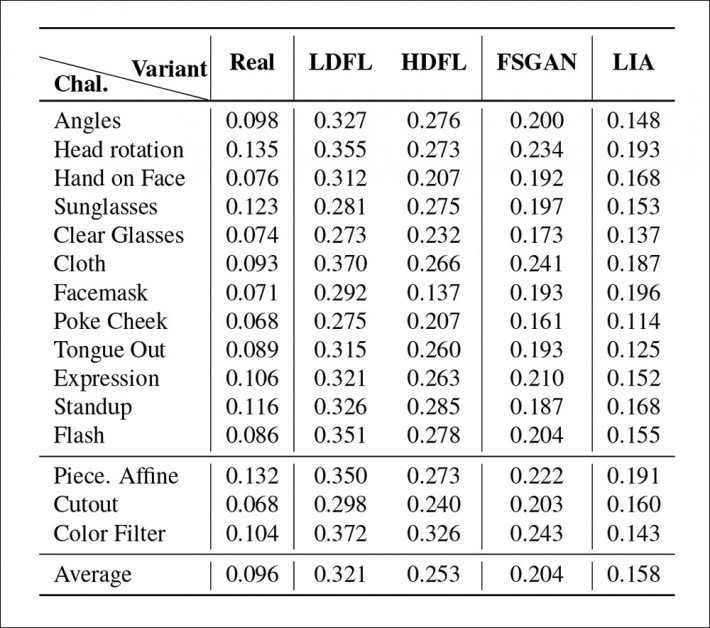
Primární výsledky z testů pro GOTCHA.
Výzkumníci zjistili, že pro celou kaskádu testů napříč čtyřmi systémy byl nejnižší počet a závažnost anomálií (tj. artefaktů, které by odhalily přítomnost deepfake systému) získány pomocí lépe vyškolené distribuce DFL. Méně trénovaná verze se potýkala zejména s obnovou složitých pohybů rtů (které zabírají velmi malou část rámu, ale kterým je věnována velká lidská pozornost), zatímco FSGAN zaujímal střed mezi dvěma verzemi DFL a LIA se ukázalo jako zcela nedostatečné pro tento úkol. , přičemž výzkumníci se domnívají, že LIA by při skutečném nasazení selhala.
Poprvé publikováno 17. října 2022.















