
Umělá inteligence
Editace objektů za pomoci umělé inteligence pomocí Google Imagic a Runway 'Erase and Replace'

Tento týden dva nové, ale kontrastní grafické algoritmy řízené umělou inteligencí nabízejí koncovým uživatelům nové způsoby, jak provádět vysoce podrobné a efektivní změny objektů na fotografiích.
První je Imagické, z Google Research, ve spolupráci s Izraelským technologickým institutem a Weizmannovým vědeckým institutem. Imagic nabízí textově podmíněné, jemnozrnné úpravy objektů prostřednictvím jemného ladění modelů difúze.

Změňte, co se vám líbí, a zbytek nechte – Imagic slibuje podrobné úpravy pouze těch částí, které chcete změnit. Zdroj: https://arxiv.org/pdf/2210.09276.pdf
Každý, kdo se někdy pokusil změnit pouze jeden prvek v re-renderu Stable Diffusion, bude až příliš dobře vědět, že při každé úspěšné úpravě systém změní pět věcí, které se vám líbily tak, jak byly. Je to nedostatek, kvůli kterému v současnosti mnoho nejtalentovanějších SD nadšenců neustále přehazuje mezi Stable Diffusion a Photoshopem, aby napravili tento druh „vedlejšího poškození“. Už jen z tohoto hlediska se zdají úspěchy Imagic pozoruhodné.
V době psaní tohoto článku Imagic ještě postrádá propagační video a vzhledem k Google obezřetný postoj k vydání neomezených nástrojů pro syntézu obrazu, není jisté, do jaké míry, pokud vůbec, dostaneme šanci systém otestovat.
Druhá nabídka je spíše přístupnější Runway ML Vymazat a nahradit zařízení, a nová vlastnost v sekci 'AI Magic Tools' exkluzivně online sady nástrojů vizuálních efektů založených na strojovém učení.
Funkce Runway ML Erase and Replace, již je vidět v náhledu systému pro úpravu textu na video. Zdroj: https://www.youtube.com/watch?v=41Qb58ZPO60
Pojďme se nejprve podívat na výlet na Runway.
Vymazat a nahradit
Stejně jako Imagic, Erase and Replace se zabývá výhradně statickými obrázky, ačkoli Runway ano zobrazilo stejná funkce v řešení pro úpravu textu na video, které ještě nebylo vydáno:

Ačkoli každý může vyzkoušet nové Vymazat a nahradit na obrázcích, verze videa zatím není veřejně dostupná. Zdroj: https://twitter.com/runwayml/status/1568220303808991232
Přestože Runway ML nezveřejnila podrobnosti o technologiích za Erase and Replace, rychlost, s jakou můžete nahradit pokojovou rostlinu přiměřeně přesvědčivou bustou Ronalda Reagana, naznačuje, že difúzní model, jako je Stable Diffusion (nebo mnohem méně pravděpodobné, licencovaný DALL-E 2) je engine, který znovuobjevuje objekt dle vašeho výběru v Erase and Replace.

Nahradit pokojovou rostlinu bustou Gippera není tak rychlé jako toto, ale je to docela rychlé. Zdroj: https://app.runwayml.com/
Systém má určitá omezení typu DALL-E 2 – obrázky nebo text, které označují filtry Erase a Replace, spustí varování o možném pozastavení účtu v případě dalších porušení – prakticky standardní klon probíhajícího OpenAI. zásady pro DALL-E 2 .
Mnoho výsledků postrádá typické drsné hrany Stable Diffusion. Runway ML jsou investoři a výzkumnými partnery v SD a je možné, že vytrénovali proprietární model, který je lepší než váhy kontrolních bodů s otevřeným zdrojovým kódem 1.4, se kterými my ostatní v současné době zápasíme (jako mnoho dalších vývojářských skupin, nadšenců i profesionálů, v současné době trénuje nebo dolaďuje Stabilní difúzní modely).
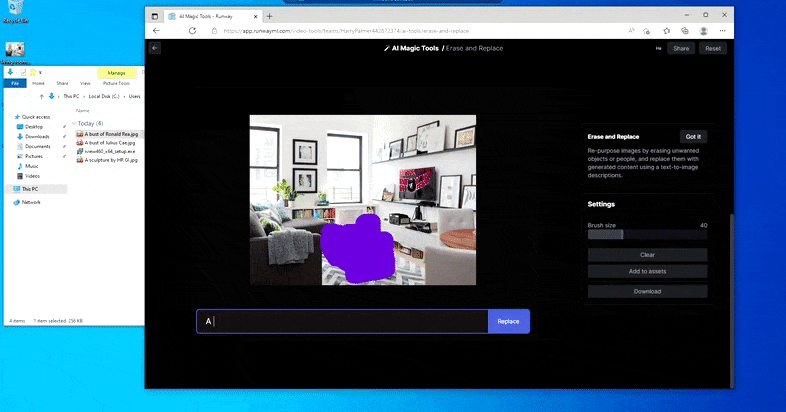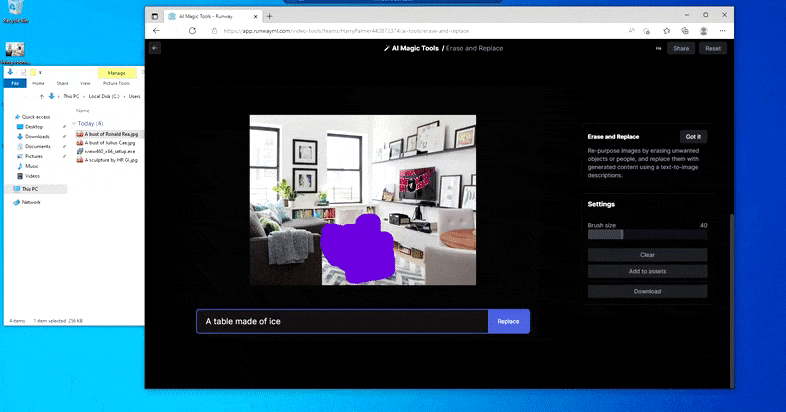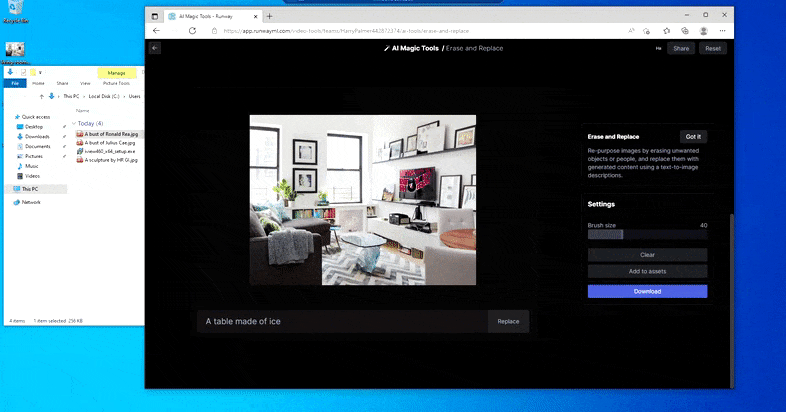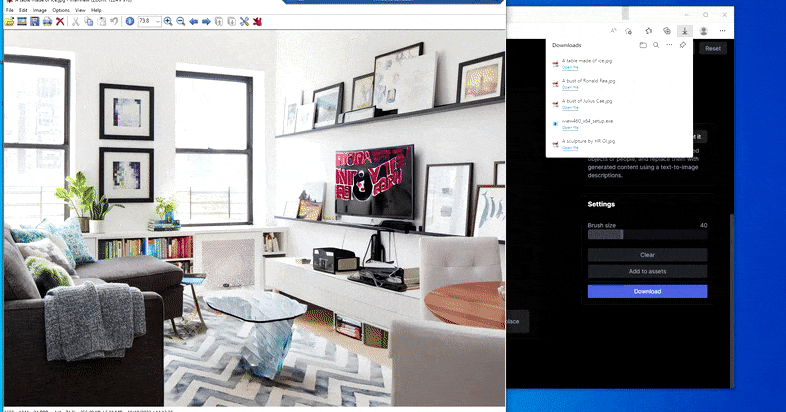
Nahrazení domácího stolu za „stůl vyrobený z ledu“ v Runway ML's Erase and Replace.
Stejně jako u Imagic (viz níže) je Erase and Replace „objektově orientovaný“ – nemůžete jen vymazat „prázdnou“ část obrázku a vymalovat ji výsledkem vaší textové výzvy; v tomto scénáři bude systém jednoduše sledovat nejbližší zdánlivý objekt podél linie viditelnosti masky (jako je zeď nebo televize) a aplikovat transformaci tam.
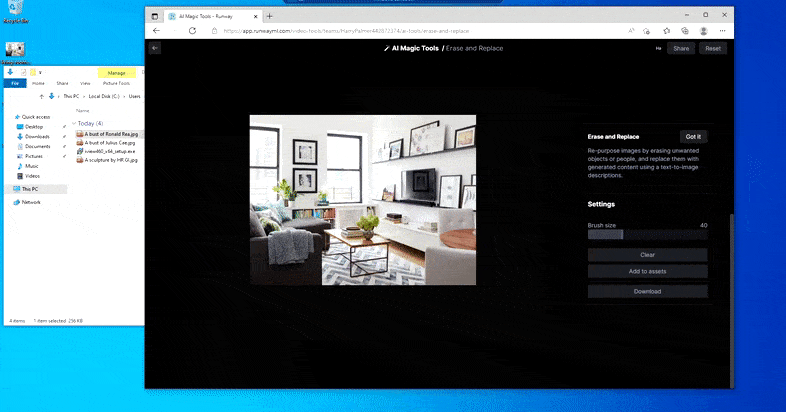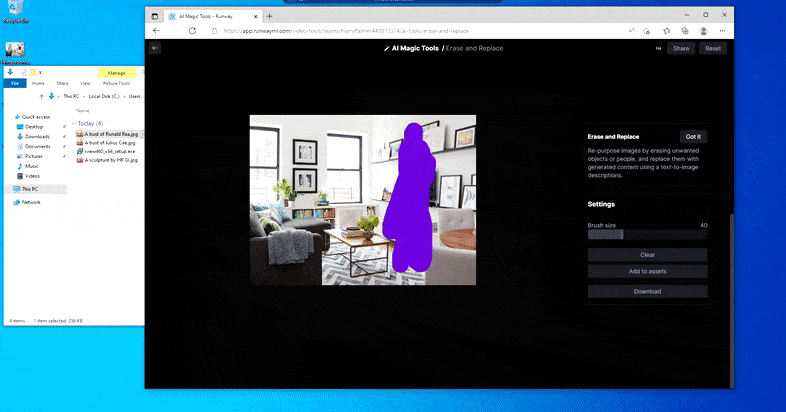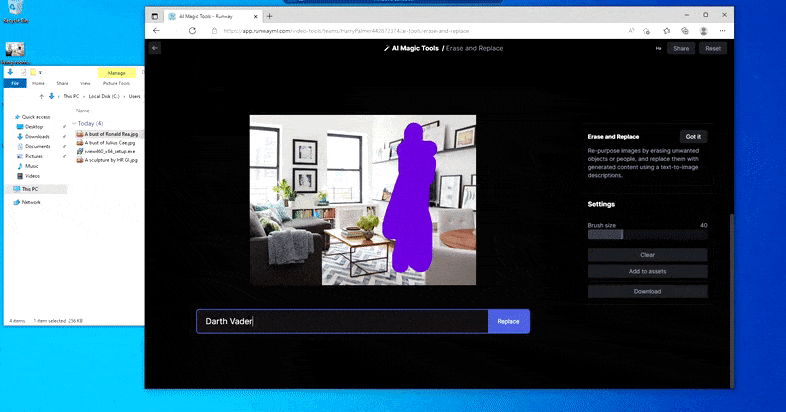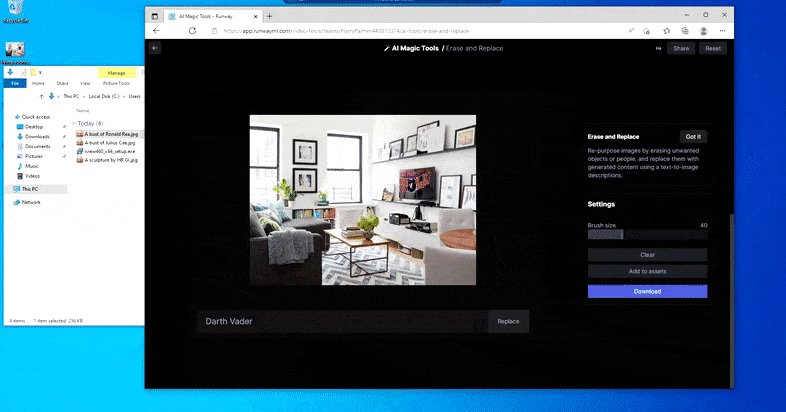
Jak název napovídá, nemůžete vložit objekty do prázdného prostoru v Erase and Replace. Zde snaha vyvolat nejslavnějšího ze Sithských lordů vyústí v podivnou nástěnnou malbu související s Vaderem v televizi, zhruba tam, kde byla nakreslena oblast „nahradit“.
Je těžké říci, zda Erase and Replace je vyhýbavý, pokud jde o použití obrázků chráněných autorským právem (které jsou v DALL-E 2 stále z velké části blokovány, i když s různým úspěchem), nebo zda model používaný v backendovém renderovacím enginu. prostě není optimalizován pro takové věci.

Mírně NSFW 'Mural of Nicole Kidman' naznačuje, že (pravděpodobně) model založený na šíření postrádá dřívější systematické odmítání DALL-E 2 vykreslování realistických tváří nebo obsahu pro dospělé, zatímco výsledky pokusů prokázat díla chráněná autorským právem se pohybují od nejednoznačných ('xenomorf') do absurdna ('železný trůn'). Vložit vpravo dole, zdrojový obrázek.
Bylo by zajímavé vědět, jaké metody Erase and Replace používá k izolaci objektů, které je schopen nahradit. Pravděpodobně obraz prochází nějakým odvozením CLIPs diskrétními položkami individualizovanými rozpoznáním objektů a následnou sémantickou segmentací. Žádná z těchto operací nefunguje tak dobře v běžné nebo zahradní instalaci Stable Diffusion.
Ale nic není dokonalé – někdy se zdá, že systém vymaže a nenahradí, i když (jak jsme viděli na obrázku výše), základní vykreslovací mechanismus rozhodně ví, co textová výzva znamená. V tomto případě se ukazuje nemožné proměnit konferenční stolek v xenomorfa – stolek spíše zmizí.
Děsivější opakování 'Where's Waldo', protože Erase and Replace nedokáže vytvořit mimozemšťana.
Erase and Replace se zdá být účinným systémem nahrazování objektů s vynikajícím malováním. Nemůže však upravovat existující vnímané objekty, ale pouze je nahradit. Skutečně změnit stávající obrazový obsah, aniž by došlo k ohrožení okolního materiálu, je pravděpodobně mnohem těžší úkol, který souvisí s dlouhodobým bojem sektoru výzkumu počítačového vidění. rozpletení v různých latentních prostorech populárních rámců.
Imagické
Je to úkol, který Imagic řeší. The nový papír nabízí četné příklady úprav, které úspěšně upravují jednotlivé aspekty fotografie, zatímco zbytek obrazu zůstává nedotčen.

V Imagic upravené obrazy netrpí charakteristickým roztahováním, zkreslením a „hádáním okluze“ charakteristickým pro loutkové divadlo, které využívá omezené priority odvozené z jednoho obrazu.
Systém využívá třífázový proces – optimalizace vkládání textu; jemné doladění modelu; a konečně generování upraveného obrázku.

Imagic zakóduje výzvu cílového textu, aby načetl počáteční vložení textu, a poté optimalizuje výsledek, aby získal vstupní obrázek. Poté je generativní model jemně doladěn na zdrojový obraz, přidáním řady parametrů, než je podroben požadované interpolaci.
Není překvapením, že framework je založen na Google Obraz architektura text-to-video, ačkoli výzkumníci uvádějí, že principy systému jsou široce použitelné na modely latentní difúze.
Imagen používá spíše třívrstvou architekturu než sedmivrstvé pole používané pro novější iterace textu na video softwaru. Tyto tři odlišné moduly zahrnují generativní difúzní model pracující v rozlišení 64x64px; model v super rozlišení, který tento výstup převzorkuje na 256x256px; a další model s vysokým rozlišením pro výstup až do rozlišení 1024×1024.
Imagic zasahuje v nejranější fázi tohoto procesu a optimalizuje požadované vkládání textu ve fázi 64px na optimalizátoru Adam při statické rychlosti učení 0.0001.

Mistrovská třída v rozuzlení: ti koncoví uživatelé, kteří se pokusili změnit něco tak jednoduchého, jako je barva vykresleného objektu v difúzi, GAN nebo NeRF modelu, budou vědět, jak důležité je, že Imagic může provádět takové transformace, aniž by se „roztrhal“. ' konzistenci zbytku obrázku.
Jemné ladění pak probíhá na základním modelu Imagen, pro 1500 kroků na vstupní obraz, podmíněné revidovaným vložením. Současně je na podmíněném obrázku paralelně optimalizována sekundární vrstva 64px>256px. Výzkumníci poznamenávají, že podobná optimalizace pro finální vrstvu 256px>1024px má „malý až žádný vliv“ na konečné výsledky, a proto ji neimplementovali.
Článek uvádí, že proces optimalizace trvá přibližně osm minut pro každý snímek na dvojčeti TPUV4 bramborové hranolky. Finální render se odehrává v core Imagen pod Schéma vzorkování DDIM.
Stejně jako podobné procesy jemného ladění pro Google stánek snů, výsledné vložení lze navíc použít k podpoře stylizace, stejně jako fotorealistických úprav, které obsahují informace čerpané z širší podkladové databáze napájející Imagen (protože, jak ukazuje první sloupec níže, zdrojové obrázky nemají žádný obsah nezbytný k tomu, aby provádět tyto transformace).

Flexibilní fotoreálný pohyb a úpravy lze vyvolat pomocí Imagic, zatímco odvozené a rozpletené kódy získané v procesu lze stejně snadno použít pro stylizovaný výstup.
Vědci porovnávali Imagic s předchozími pracemi SDEdit, přístup založený na GAN od roku 2021, spolupráce mezi Stanfordskou univerzitou a Carnegie Mellon University; a Text2Live, spolupráce, od dubna 2022, mezi Weizmann Institute of Science a NVIDIA.

Vizuální srovnání mezi Imagic, SDEdit a Text2Live.
Je jasné, že předchozí přístupy se potýkají s problémy, ale ve spodní řadě, která zahrnuje masivní změnu pozice, se stávajícím držitelům úplně nedaří přetvořit zdrojový materiál ve srovnání s pozoruhodným úspěchem od Imagic.
Požadavky společnosti Imagic na zdroje a čas na zaškolení na jeden obrázek, ačkoli jsou podle standardů podobných činností krátké, z něj činí nepravděpodobné začlenění do místní aplikace pro úpravu obrázků na osobních počítačích – a není jasné, do jaké míry by mohl být proces jemného ladění zmenšena na spotřebitelskou úroveň.
V současné době je Imagic působivou nabídkou, která je vhodnější pro API – prostředí Google Research, které je kritizováno v souvislosti s usnadněním deepfakingu, může být v každém případě nejpohodlnější.
Poprvé publikováno 18. října 2022.















