
Най-добър от
10 най-добри алгоритми за машинно обучение
Въпреки че живеем във време на изключителни иновации в GPU-ускореното машинно обучение, най-новите научни статии често (и на видно място) представят алгоритми, които са на десетилетия, в някои случаи на 70 години.
Някои може да твърдят, че много от тези по-стари методи попадат в лагера на „статистическия анализ“, а не на машинното обучение, и предпочитат да датират появата на сектора едва през 1957 г., с изобретението на перцептрона.
Като се има предвид степента, в която тези по-стари алгоритми поддържат и са въвлечени в най-новите тенденции и грабващите заглавия разработки в машинното обучение, това е спорна позиция. Така че нека да разгледаме някои от „класическите“ градивни елементи, които са в основата на най-новите иновации, както и някои по-нови записи, които правят ранна оферта за залата на славата на AI.
1: Трансформърс
През 2017 г. Google Research ръководи изследователско сътрудничество, което завърши с хартия Вниманието е всичко, от което се нуждаете. Работата очертава нова архитектура, която насърчава механизми за внимание от „тръбопроводи“ в енкодер/декодер и повтарящи се мрежови модели до централна трансформационна технология сами по себе си.
Подходът беше дублиран Трансформатор, и оттогава се превърна в революционна методология в обработката на естествен език (NLP), захранвайки, наред с много други примери, авторегресивния езиков модел и AI poster-child GPT-3.
![]()
Трансформаторите елегантно решиха проблема с трансдукция на последователност, наричана още „трансформация“, която е заета с обработката на входни последователности в изходни последователности. Трансформаторът също получава и управлява данни по непрекъснат начин, а не в последователни партиди, което позволява „постоянство на паметта“, което RNN архитектурите не са предназначени да получат. За по-подробен преглед на трансформаторите, разгледайте нашата референтна статия.
За разлика от повтарящите се невронни мрежи (RNN), които бяха започнали да доминират в изследванията на машинното обучение в ерата на CUDA, трансформаторната архитектура също може лесно да бъде паралелизирани, отваряйки пътя за продуктивно адресиране на много по-голям набор от данни от RNN.
Популярна употреба
Трансформърс завладяха въображението на обществеността през 2020 г. с пускането на GPT-3 на OpenAI, който се похвали с рекорден тогава 175 милиарда параметри. Това очевидно зашеметяващо постижение в крайна сметка беше засенчено от по-късни проекти, като 2021 г. освободи на Megatron-Turing NLG 530B на Microsoft, който (както подсказва името) разполага с над 530 милиарда параметри.

График на хипермащабни NLP проекти на Transformer. Източник: Microsoft
Трансформаторната архитектура също е преминала от НЛП към компютърно зрение, захранвайки a нова генерация на рамки за синтез на изображения като OpenAI's CLIP намлява DALL-E, които използват картографиране на домейн текст>изображение, за да завършат непълни изображения и да синтезират нови изображения от обучени домейни, сред нарастващ брой свързани приложения.

DALL-E се опитва да завърши частично изображение на бюст на Платон. Източник: https://openai.com/blog/dall-e/
2: Генеративни състезателни мрежи (GAN)
Въпреки че трансформаторите получиха изключително медийно отразяване чрез пускането и приемането на GPT-3, Генеративна състезателна мрежа (GAN) се превърна в разпознаваема марка сама по себе си и може евентуално да се присъедини deepfake като глагол.
Първо предложено в 2014 и се използва предимно за синтез на изображения, Generative Adversarial Network архитектура е съставен от a Генератор и Дискриминатор. Генераторът преминава през хиляди изображения в набор от данни, като итеративно се опитва да ги реконструира. За всеки опит Дискриминаторът оценява работата на Генератора и го изпраща обратно, за да се справи по-добре, но без никаква представа за начина, по който предишната реконструкция е допуснала грешка.

Източник: https://developers.google.com/machine-learning/gan/gan_structure
Това принуждава Генератора да изследва множество пътища, вместо да следва потенциалните слепи улички, които биха се получили, ако Дискриминаторът му беше казал къде греши (виж #8 по-долу). Докато обучението приключи, Генераторът разполага с подробна и изчерпателна карта на връзките между точките в набора от данни.

От хартията Подобряване на GAN равновесието чрез повишаване на пространствената осведоменост: нова рамка преминава през понякога мистериозното латентно пространство на GAN, осигурявайки отзивчив инструмент за архитектура за синтез на изображения. Източник: https://genforce.github.io/eqgan/
По аналогия, това е разликата между това да научите едно-единствено обикновено пътуване до централен Лондон или старателно придобиване Знанието.
Резултатът е колекция от функции на високо ниво в латентното пространство на обучения модел. Семантичният индикатор за характеристика на високо ниво може да бъде „човек“, докато спускането през специфичност, свързана с характеристиката, може да разкрие други научени характеристики, като „мъжки“ и „женски“. На по-ниски нива подхарактеристиките могат да се разделят на „блондинка“, „кавказка“ и др.
Заплитането е забележителен проблем в латентното пространство на GANs и рамки за енкодер/декодер: дали усмивката на женско лице, генерирано от GAN, е заплетена характеристика на нейната „идентичност“ в латентното пространство, или е паралелен клон?

Генерирани от GAN лица от този човек не съществуват. Източник: https://this-person-does-not-exist.com/en
Последните няколко години донесоха нарастващ брой нови изследователски инициативи в това отношение, може би проправяйки пътя за редактиране в стил Photoshop на ниво функции за латентното пространство на GAN, но в момента много трансформации са ефективно " пакети "всичко или нищо". По-специално, изданието EditGAN на NVIDIA от края на 2021 г. постига a високо ниво на интерпретируемост в латентното пространство чрез използване на маски за семантично сегментиране.
Популярна употреба
Освен тяхното (всъщност доста ограничено) участие в популярни дълбоки фалшиви видеоклипове, GAN, ориентирани към изображения/видео, се разпространиха през последните четири години, увличайки изследователите и обществеността. Поддържането на шеметната скорост и честотата на новите версии е предизвикателство, въпреки че хранилището на GitHub Страхотни GAN приложения има за цел да предостави изчерпателен списък.
Генеративните състезателни мрежи могат на теория да извлекат характеристики от всеки добре оформен домейн, включително текст.
3: SVM
Произхожда в 1963, Поддържаща векторна машина (SVM) е основен алгоритъм, който често се появява в нови изследвания. При SVM векторите картографират относителното разположение на точките от данни в набор от данни, докато подкрепа векторите очертават границите между различни групи, характеристики или черти.
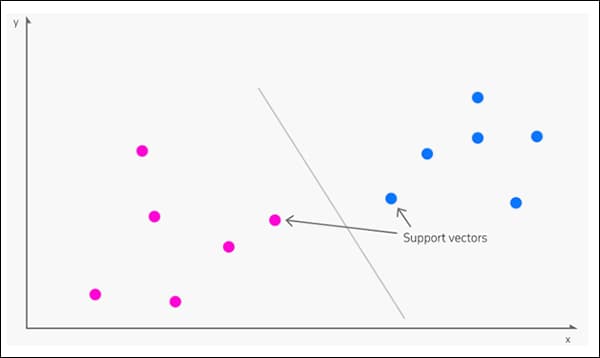
Поддържащите вектори определят границите между групите. Източник: https://www.kdnuggets.com/2016/07/support-vector-machines-simple-explanation.html
Получената граница се нарича a хиперплоскост.
При ниски нива на функции, SVM е двуизмерен (изображение по-горе), но когато има по-голям разпознат брой групи или типове, става триизмерна.

По-дълбокият набор от точки и групи налага триизмерен SVM. Източник: https://cml.rhul.ac.uk/svm.html
Популярна употреба
Тъй като поддържащите векторни машини могат ефективно и агностично да адресират високоразмерни данни от много видове, те се появяват широко в различни сектори на машинно обучение, включително откриване на deepfake, класификация на изображението, класификация на речта на омразата, ДНК анализ намлява прогнозиране на структурата на населението, Както и много други.
4: K-средни клъстери
Клъстерирането като цяло е учене без надзор подход, който се стреми да категоризира точките от данни чрез оценка на плътността, създавайки карта на разпространението на изследваните данни.

K-означава групиране на божествени сегменти, групи и общности в данни. Източник: https://aws.amazon.com/blogs/machine-learning/k-means-clustering-with-amazon-sagemaker/
К-средства групиране се превърна в най-популярното приложение на този подход, като разделя точките от данни в отличителни „K групи“, които могат да показват демографски сектори, онлайн общности или всякакви други възможни тайни агрегации, чакащи да бъдат открити в необработените статистически данни.

Клъстерите се формират в анализа на K-Means. Източник: https://www.geeksforgeeks.org/ml-determine-the-optimal-value-of-k-in-k-means-clustering/
Самата стойност на K е определящият фактор за полезността на процеса и за установяването на оптимална стойност за клъстер. Първоначално стойността K се присвоява на случаен принцип и нейните характеристики и векторни характеристики се сравняват със съседните. Тези съседи, които най-много приличат на точката от данни с произволно присвоената стойност, се присвояват на нейния клъстер итеративно, докато данните не дадат всички групи, които процесът позволява.
Графиката за квадратната грешка или „цената“ на различни стойности сред клъстерите ще разкрие лакътна точка за данните:

„Точката на лакътя“ в клъстерна графика. Източник: https://www.scikit-yb.org/en/latest/api/cluster/elbow.html
Точката на лакътя е подобна по концепция на начина, по който загубата се изравнява до намаляваща възвръщаемост в края на тренировъчната сесия за набор от данни. Той представлява точката, в която няма да станат очевидни допълнителни разграничения между групите, като посочва момента за преминаване към следващите фази в тръбопровода с данни или в противен случай за докладване на констатациите.
Популярна употреба
K-Means Clustering, по очевидни причини, е основна технология в анализа на клиента, тъй като предлага ясна и обяснима методология за преобразуване на големи количества търговски записи в демографски прозрения и „потенциални клиенти“.
Извън това приложение, K-Means Clustering също се използва за прогнозиране на свлачища, сегментиране на медицинско изображение, синтез на изображения с GAN, класификация на документи, и градоустройство, сред много други потенциални и действителни употреби.
5: Случайна гора
Случайна гора е обучение в ансамбъл метод, който усреднява резултата от масив от дървета за вземане на решения за установяване на цялостна прогноза за резултата.

Източник: https://www.tutorialandexample.com/wp-content/uploads/2019/10/Decision-Trees-Root-Node.png
Ако сте го изследвали дори толкова малко, колкото гледането на Завръщане в бъдещето трилогията, самото дърво на решенията е сравнително лесно за концептуализиране: редица пътища лежат пред вас и всеки път се разклонява към нов резултат, който на свой ред съдържа допълнителни възможни пътища.
In укрепване, можете да се оттеглите от даден път и да започнете отново от по-ранна позиция, докато дърветата на решенията се ангажират със своите пътувания.
По този начин алгоритъмът Random Forest е по същество залагане на разпространение за решения. Алгоритъмът се нарича „случаен“, защото прави Ad Hoc селекции и наблюдения, за да разберем медиана сума от резултатите от масива на дървото на решенията.
Тъй като взема предвид множество фактори, подходът на произволна гора може да бъде по-труден за преобразуване в смислени графики, отколкото дърво на решенията, но вероятно ще бъде значително по-продуктивен.
Дърветата на решенията са обект на пренастройване, при което получените резултати са специфични за данните и няма вероятност да се обобщят. Произволната селекция на точки от данни на Random Forest се бори с тази тенденция, достигайки до значими и полезни представителни тенденции в данните.

Регресия на дървото на решенията. Източник: https://scikit-learn.org/stable/auto_examples/tree/plot_tree_regression.html
Популярна употреба
Както при много от алгоритмите в този списък, Random Forest обикновено работи като „ранно“ сортиране и филтриране на данни и като такъв постоянно се появява в нови научни статии. Някои примери за използване на Random Forest включват Синтез на изображение с магнитен резонанс, Прогнозиране на цената на биткойн, сегментиране на преброяването, класификация на текста намлява откриване на измами с кредитни карти.
Тъй като Random Forest е алгоритъм от ниско ниво в архитектурите за машинно обучение, той може също да допринесе за производителността на други методи от ниско ниво, както и алгоритми за визуализация, включително Индуктивно клъстериране, Трансформации на функции, класификация на текстови документи използване на редки функции, и показване на тръбопроводи.
6: Наивен Бейс
В съчетание с оценка на плътността (вж 4, по-горе), a наивен Байес класификаторът е мощен, но сравнително лек алгоритъм, способен да оценява вероятностите въз основа на изчислените характеристики на данните.

Връзки на признаци в наивен класификатор на Бейс. Източник: https://www.sciencedirect.com/topics/computer-science/naive-bayes-model
Терминът „наивен“ се отнася до предположението в Теорема на Бейс че характеристиките не са свързани, известни като условна независимост. Ако възприемете тази гледна точка, ходенето и говоренето като патица не са достатъчни, за да се установи, че си имаме работа с патица, и никакви „очевидни“ предположения не са приети преждевременно.
Това ниво на академична и разследваща строгост би било пресилено, когато е наличен „здрав разум“, но е ценен стандарт при преминаване през многото неясноти и потенциално несвързани корелации, които могат да съществуват в набор от данни за машинно обучение.
В оригинална байесова мрежа характеристиките са обект на точкови функции, включително минимална дължина на описанието и Бейсово точкуване, което може да наложи ограничения върху данните по отношение на приблизителните връзки, открити между точките от данни, и посоката, в която протичат тези връзки.
Наивният класификатор на Бейс, обратно, работи, като приема, че характеристиките на даден обект са независими, като впоследствие използва теоремата на Байс, за да изчисли вероятността за даден обект въз основа на неговите характеристики.
Популярна употреба
Наивните Bayes филтри са добре представени в прогнозиране на заболяването и категоризиране на документи, филтриране на спам, класификация на настроенията, препоръчителни системи, и откриване на измами, наред с други приложения.
7: K- Най-близки съседи (KNN)
Първо предложено от Училището по авиационна медицина на ВВС на САЩ в 1951и трябва да се приспособи към най-съвременния компютърен хардуер от средата на 20-ти век, K-най-близки съседи (KNN) е лесен алгоритъм, който все още е на видно място в академичните статии и изследователските инициативи за машинно обучение в частния сектор.
KNN е наречен „мързеливият обучаем“, тъй като сканира изчерпателно набор от данни, за да оцени връзките между точките от данни, вместо да изисква обучение на пълноценен модел за машинно обучение.

Група KNN. източник: https://scikit-learn.org/stable/modules/neighbors.html
Въпреки че KNN е архитектурно тънък, неговият систематичен подход поставя значително изискване върху операциите за четене/запис и използването му в много големи набори от данни може да бъде проблематично без допълнителни технологии като Анализ на основните компоненти (PCA), които могат да трансформират сложни и масиви от данни с голям обем в представителни групи които KNN може да премине с по-малко усилия.
A Неотдавнашно проучване оцени ефективността и икономичността на редица алгоритми, имащи за задача да предскажат дали даден служител ще напусне компания, установявайки, че седемдесетгодишният KNN остава по-добър от по-модерните конкуренти по отношение на точност и прогнозна ефективност.
Популярна употреба
Въпреки цялата си популярна простота на концепция и изпълнение, KNN не е заседнал в 1950-те години на миналия век – той е адаптиран в по-фокусиран върху DNN подход в предложение от 2018 г. на Пенсилванския държавен университет и остава централен процес на ранен етап (или аналитичен инструмент за последваща обработка) в много много по-сложни рамки за машинно обучение.
В различни конфигурации KNN е използван или за онлайн проверка на подписа, класификация на изображението, извличане на текст, прогнозиране на реколтата, и разпознаване на лица, освен други приложения и включвания.

Базирана на KNN система за лицево разпознаване в обучение. Source: https://pdfs.semanticscholar.org/6f3d/d4c5ffeb3ce74bf57342861686944490f513.pdf
8: Процес на вземане на решение по Марков (MDP)
Математическа рамка, въведена от американския математик Ричард Белман в 1957, Процесът на вземане на решения по Марков (MDP) е един от най-основните блокове на укрепване архитектури. Концептуален алгоритъм сам по себе си, той е адаптиран в голям брой други алгоритми и се повтаря често в текущата култура на AI/ML изследвания.
MDP изследва среда с данни, като използва своята оценка на текущото й състояние (т.е. „къде“ се намира в данните), за да реши кой възел от данните да проучи следващия.

Източник: https://www.sciencedirect.com/science/article/abs/pii/S0888613X18304420
Основният процес на вземане на решения по Марков ще даде приоритет на краткосрочното предимство пред по-желаните дългосрочни цели. Поради тази причина то обикновено е вградено в контекста на по-всеобхватна политическа архитектура в обучението за укрепване и често е обект на ограничаващи фактори като награда с отстъпкаи други модифициращи променливи на околната среда, които ще му попречат да се втурне към непосредствена цел, без да вземе предвид по-широкия желан резултат.
Популярна употреба
Концепцията на ниско ниво на MDP е широко разпространена както в изследванията, така и в активното внедряване на машинно обучение. Предложено е за IoT системи за защита на сигурността, събиране на риба, и прогнозиране на пазара.
Освен неговата очевидна приложимост за шах и други строго последователни игри, MDP също е естествен претендент за процедурно обучение на роботизирани системи, както можем да видим във видеото по-долу.

9: Честота на термина – обратна честота на документа
Честота на термина (TF) разделя броя на появяванията на дума в документ на общия брой думи в този документ. Така думата запечата появяващ се веднъж в статия от хиляда думи има честота на термина 0.001. Сам по себе си TF е до голяма степен безполезен като индикатор за важност на термина, поради факта, че безсмислените статии (като напр. a, намлява, -, и it) преобладават.
За да получи смислена стойност за термин, обратната честота на документа (IDF) изчислява TF на дума в множество документи в набор от данни, присвоявайки ниска оценка на много висока честота стоп думи, като статии. Получените вектори на признаци се нормализират до цели стойности, като на всяка дума се присвоява подходящо тегло.

TF-IDF претегля уместността на термините въз основа на честотата в редица документи, като по-рядкото появяване е индикатор за значимост. Източник: https://moz.com/blog/inverse-document-frequency-and-the-importance-of-uniqueness
Въпреки че този подход предотвратява загубата на семантично важни думи като големите различия в стойностите, обръщането на честотното тегло не означава автоматично, че терминът с ниска честота е такъв не извънредно, защото някои неща са редки намлява безполезен. Следователно термин с ниска честота ще трябва да докаже стойността си в по-широкия архитектурен контекст чрез представяне (дори с ниска честота на документ) в редица документи в набора от данни.
Въпреки своите възраст, TF-IDF е мощен и популярен метод за първоначални пропуски за филтриране в рамки за обработка на естествен език.
Популярна употреба
Тъй като TF-IDF изигра поне известна роля в развитието на до голяма степен окултния алгоритъм на Google PageRank през последните двадесет години, той се превърна много широко възприети като манипулативна SEO тактика, въпреки 2019 г. на Джон Мюлер отричане за значението му за резултатите от търсенето.
Поради секретността около PageRank, няма ясни доказателства, че TF-IDF е такъв не в момента ефективна тактика за издигане в класацията на Google. Запалителен дискусия сред ИТ професионалистите напоследък показва популярно разбиране, правилно или не, че злоупотребата с термина все още може да доведе до подобрено позициониране на SEO (макар и допълнително обвинения в злоупотреба с монопол намлява прекомерна реклама размиват границите на тази теория).
10: Стохастичен градиентен спад
Стохастичен градиентен спускане (SGD) е все по-популярен метод за оптимизиране на обучението на модели за машинно обучение.
Самият Gradient Descent е метод за оптимизиране и последващо количествено определяне на подобрението, което моделът прави по време на обучението.
В този смисъл „градиент“ показва наклон надолу (вместо базирана на цвят градация, вижте изображението по-долу), където най-високата точка на „хълма“, вляво, представлява началото на тренировъчния процес. На този етап моделът все още не е видял цялата информация нито веднъж и не е научил достатъчно за връзките между данните, за да произведе ефективни трансформации.

Градиентно спускане на тренировъчна сесия FaceSwap. Можем да видим, че обучението е на плато за известно време през втората половина, но в крайна сметка се е възстановило надолу по градиента към приемлива конвергенция.
Най-ниската точка, вдясно, представлява конвергенция (точката, в която моделът е толкова ефективен, колкото някога ще попадне под наложените ограничения и настройки).
Градиентът действа като запис и предиктор за несъответствието между степента на грешка (колко точно моделът в момента е картографирал връзките на данните) и теглата (настройките, които влияят на начина, по който моделът ще се учи).
Този запис на напредъка може да се използва за информиране на a график на скоростта на обучение, автоматичен процес, който казва на архитектурата да стане по-подробна и прецизна, тъй като ранните неясни детайли се трансформират в ясни връзки и съпоставки. На практика загубата на градиент предоставя навременна карта за това къде следва да продължи обучението и как трябва да продължи.
Иновацията на Stochastic Gradient Descent е, че актуализира параметрите на модела на всеки пример за обучение на итерация, което обикновено ускорява пътуването до конвергенция. Поради появата на хипермащабни набори от данни през последните години, SGD набра популярност напоследък като един възможен метод за справяне с произтичащите логистични проблеми.
От друга страна, SGD има отрицателни последици за мащабиране на функции и може да изисква повече итерации за постигане на същия резултат, което изисква допълнително планиране и допълнителни параметри, в сравнение с обикновения Gradient Descent.
Популярна употреба
Благодарение на своята конфигурируемост и въпреки недостатъците си, SGD се превърна в най-популярния алгоритъм за оптимизация за напасване на невронни мрежи. Една конфигурация на SGD, която става доминираща в новите изследователски документи за AI/ML, е изборът на Adaptive Moment Estimation (ADAM, въведен в 2015) оптимизатор.
ADAM адаптира скоростта на обучение за всеки параметър динамично („адаптивна скорост на обучение“), както и включва резултатите от предишни актуализации в последващата конфигурация („инерция“). Освен това може да се конфигурира да използва по-късни иновации, като напр Инерция на Нестеров.
Някои обаче твърдят, че използването на импулс може също да ускори ADAM (и подобни алгоритми) до a неоптимално заключение. Както при повечето от кървящия ръб на изследователския сектор за машинно обучение, SGD е в процес на работа.
Първо публикувано на 10 февруари 2022 г. Променено на 10 февруари 20.05 EET – форматиране.















