الذكاء الاصطناعي
طريقة جديدة لتحويل الوجه العميق تحل مشكلة ‘مضيف الوجه’

على الرغم من السنوات العديدة من المبالغة الإعلامية حول إمكانية صور الوجه العميق لتجاهل الثقة الطويلة الأمد في صحة الفيديو ، تعتمد جميع الطرق الشائعة الحالية على العثور على ‘مضيفي الوجه’ الذين يشبهون بشكل عام الشكل المستهدف للوجه.
حيث يتميز الفيديو الأصلي بوجود وجه واسع ، ولكن موضوع الهدف له وجه ضيق ، فإن النتائج دائمًا ما تكون مشكلة ، لأن مثل هذا النقل يتضمن قطع جزء من الوجه الأصلي وإعادة بناء الخلفية المعرضة الآن. يمكن لحزمة مثل DeepFaceLab و FaceSwap إنتاج نتائج محدودة عند عكس التكوين (ضيق > واسع) ، ولكنها لا تملك أي وسيلة لمواجهة هذا السيناريو بشكل مقنع.
الآن ، قام تعاون بين Tencent وجامعة شيامن في الصين بتطوير نهج جديد ، بعنوان HifiFace ، مصمم لتصحيح هذا النقص.

صورتان ل HifiFace ، الأولى لآن هاثاواي ، حيث يتم الحصول على شبه جيدة على الرغم من عدم توافق شكل الوجه المضيف. HifiFace يعمل أيضًا بشكل جيد على الأهداف التي تتميز بنظارات ، وهو ما يعتبر عائقًا تقليديًا في الوجه العميق. مصدر: https://arxiv.org/pdf/2106.09965.pdf
إعادة تشكيل الوجه العميق
النهج السابقة ، مثل تبادل الوجه وتجسيد الموضوع غير المتأثر (FSGAN) في عام 2019 ، اعتمدت على 3DMM fitting (3D Morphable Models) أو منهجيات أخرى تستند إلى التعرف على معالم الوجه أو التحويل ، حيث تحدد معالم الوجه التي سيتم “كتابةها” بشكل جيد حدود التبادل:

كشف معالم الوجه 3DMM. مصدر: https://github.com/Yinghao-Li/3DMM-fitting
على الرغم من أن الأساليب التنافسية قد استخدمت ميزات مشتقة من شبكات التعرف على الوجه ، إلا أنها تهدف في الغالب إلى إعادة بناء النسيج بدلاً من الهيكل ، وتنتج أيضًا تأثيرًا “مasks-like” في الحالات التي لا يتوافق فيها الوجه المضيف تمامًا (أي حدود و forme الشعر ، والفك ، والخدين).
للمواجهة هذه القضايا ، قام الباحثون الصينيون ، الذين يقعون في مختبر تحليل و計算 الوسائط في قسم الذكاء الاصطناعي في الجامعة ، بتطوير شبكة نهاية إلى نهاية تتناقص معاملات الوجه المستهدف والوجه المصدر باستخدام نموذج إعادة بناء ثلاثي الأبعاد ، والذي يتم إعادة دمجه كبيانات هيكلية ، وتركيبه مع معلومات متجه الهوية من شبكة التعرف على الوجه.
ثم يتم إدخال هذه البيانات الجغرافية المكانية إلى نموذج التشفير-فك التشفير كبيانات هيكلية ، وخلطها مع تعبير الوجه المستهدف وموقفه ، والتي يتم استخدامها كمساعدات إضافية لنقل دقيق.

دمج الوجه الدلالي
بالإضافة إلى ذلك ، يحتوي HifiFace على مكون دمج الوجه الدلالي (SFF) ، والذي يستخدم ميزة منخفضة المستوى في التشفير للحفاظ على المعلومات المكانية والنسيجية ، دون التضحية بهوية الصورة المستهدفة. يتم دمج الميزات من التشفير والفك التشفير في قناع تعلمي ، وتمزج المعلومات الخلفية في الإخراج بواسطة قناع الوجه المكتسب.

HifiFace في العمل. مصدر: https://johann.wang/HifiFace/
بهذه الطريقة ، يختلف HifiFace عن استخدام حدود الوجه الأصلي كحد أقصى صلب ، من خلال استخدام تقطيع الوجه الدلالي الممدود ، حيث يمكن للنموذج أداء اندماج أفضل على حدود حافة الوجه.
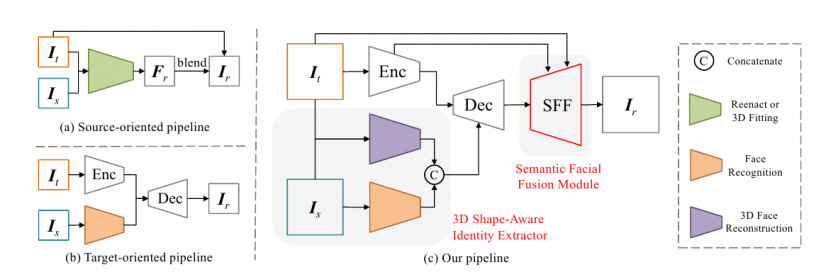
نهجين سابقين (أعلى ويسار) ، وهندسة HifiFace الجديدة ، التي تتكون من تشفير ، فك تشفير ، مستخرج هويتي ثلاثي الأبعاد ، ووحدة SFF.

في مقارنة بالأساليب السابقة FSGAN ، SimSwap و FaceShifter ، يظهر HifiFace بناء أفضل لشكل الوجه ، لأنه لا يقوم بتقليد عناصر “ال幽霊” حيث تسبب حدود الوجه في ارتباك الخريطة الهوية > الهوية ، ولكن إعادة بناءها بشكل قاطع.

اختبار
نفذ الباحثون النظام باستخدام VGGFace2 وبيانات DeepGlint Asian-Celeb. تم محاذاة الوجوه بواسطة 5 معالم خارجية وتم تقليمها إلى 256×256 بكسل. تم استخدام شبكة تعزيز الصور أيضًا لتوليد نسخة 512×512 بكسل ، لنموذج عالي الدقة إضافي. تم تدريب النموذج تحت Adam.

على الرغم من أن FaceShifter يحافظ على الهوية بشكل جيد ، إلا أنه لا يستطيع معالجة قضايا مثل التعبير ، واللون ، والغموض بشكل فعال مثل HifiFace ، ولديه هيكل شبكة أكثر تعقيدًا. FSGAN لديه مشاكل في نقل الإضاءة من المصدر إلى الهدف.
استخدم الباحثون FaceForensics++ للمقارنات الكمية ، واختبار عشرة إطارات لكل منها في مجموعة من الفيديوهات المحولة عبر الأساليب المت쟁ية ، ووجدوا أن HifiFace حقق درجة استرجاع هوية متفوقة. عند اختبار مجموعة من العوامل الأخرى ، مثل جودة الصورة ، وجد الباحثون أيضًا أن طريقةهم تفوقت على المناهج المتنافسة.

تم إعادة إنتاج معالم الوجه لبينيدكت كومبرباتش بدقة.
يعمل هذا العمل على تحريك المادة المصدرية بحيث تصبح مجرد قالب خشن يمكن نقل الهويات الدقيقة إليه. بعض حزم البرمجيات الحرة الحالية ، بما في ذلك DeepFaceLab ، تتميز بوظيفة بدائية لاستبدال الرأس الكامل ، ولكن مثل HifiFace ، لا تاخذ في الاعتبار الشعر ، وهي أكثر فعالية في “بناء” الوجه بدلاً من نحتها لتناسب مصدر الهدف المطلوب.












