
Штучний Інтелект
RigNeRF: новий метод Deepfakes, який використовує поля нейронного випромінювання

Нове дослідження, розроблене Adobe, пропонує перший життєздатний і ефективний метод deepfakes, заснований на Нейронні поля випромінювання (NeRF) – чи не перша справжня інновація в архітектурі чи підході за п’ять років з моменту появи дипфейків у 2017 році.
Спосіб під назвою RigNeRF, використовує 3D моделі обличчя, які можна морфувати (3DMM) як проміжний рівень інструментальності між бажаним введенням (тобто ідентичність, яка буде накладена на візуалізацію NeRF) і нейронним простором, метод, який був широко поширене в останні роки підходами Generative Adversarial Network (GAN) до синтезу обличчя, жоден із яких ще не створив функціональних і корисних фреймворків заміни обличчя для відео.

На відміну від традиційних глибоких фейкових відео, абсолютно жоден рухомий вміст, зображений тут, не є «справжнім», а скоріше це досліджуваний нейронний простір, навчений на коротких кадрах. Праворуч ми бачимо тривимірну модель обличчя (3DMM), яка діє як інтерфейс між бажаними маніпуляціями («посмішка», «погляд ліворуч», «погляд вгору» тощо) та параметрами поля нейронного випромінювання, які зазвичай не піддаються обробці. візуалізація. Версію цього кліпу з високою роздільною здатністю та інші приклади див Сторінка проекту, або вбудовані відео в кінці цієї статті. Джерело: https://shahrukhathar.github.io/2022/06/06/RigNeRF.html
3DMM фактично є CGI-моделями облич, параметри яких можна адаптувати до більш абстрактних систем синтезу зображень, таких як NeRF і GAN, якими інакше важко керувати.
Те, що ви бачите на зображенні вище (зображення посередині, чоловік у синій сорочці), а також на зображенні безпосередньо внизу (зображення зліва, чоловік у синій сорочці), не є «справжнім» відео, у якому невелика частина « підроблене обличчя було накладено, але повністю синтезована сцена, яка існує виключно як об’ємна нейронна візуалізація – включаючи тіло та фон:

У наведеному вище прикладі реальне відео праворуч (жінка в червоній сукні) використовується для «маріонетки» захопленої особистості (чоловік у синій сорочці) ліворуч за допомогою RigNeRF, який (за твердженням авторів) є першим Система на основі NeRF для досягнення поділу пози та виразу, одночасно маючи можливість виконувати нові синтези поглядів.
Чоловіча фігура ліворуч на зображенні вище була «знята» з 70-секундного відео зі смартфона, а вхідні дані (включаючи всю інформацію про сцену) згодом тренувалися на 4 графічних процесорах V100 для отримання сцени.
Оскільки параметричні установки у стилі 3DMM також доступні як параметричні CGI-проксі для всього тіла (а не просто обладнання для обличчя), RigNeRF потенційно відкриває можливість дипфейків всього тіла, де реальні людські рухи, текстура та експресія передаються на параметричний рівень на основі CGI, який потім переводить дії та експресію у відтворені середовища та відео NeRF .
Щодо RigNeRF – чи кваліфікується він як метод deepfake у нинішньому розумінні, згідно з яким заголовки розуміють цей термін? Або це просто ще одна напівпогана система DeepFaceLab та інші трудомісткі системи глибокого підроблення автокодерів епохи 2017 року?
Дослідники нової статті однозначні з цього приводу:
«Будучи методом, який здатний реанімувати обличчя, RigNeRF схильний до неправильного використання зловмисниками для створення глибоких фейків».
Новий папір має титул RigNeRF: повністю керовані нейронні 3D портрети, і походить від ShahRukh Atha з Університету Stonybrook, стажера в Adobe під час розробки RigNeRF, і чотирьох інших авторів з Adobe Research.
За межами Deepfakes на основі автокодерів
Більшість вірусних дипфейків, які потрапили в газетні заголовки за останні кілька років, створені автокодерсистеми, засновані на коді, який був опублікований на миттєво забороненому субредіті r/deepfakes у 2017 році – хоча не раніше, ніж скопійовано на GitHub, де його наразі розгалужено понад тисячу разів, не в останню чергу в популярний (якщо спірний) DeepFaceLab розподіл, а також Заміна обличчя Проект.
Крім GAN і NeRF, фреймворки автокодерів також експериментували з 3DMM як «керівними принципами» для покращених фреймворків синтезу обличчя. Прикладом цього є Проект HifiFace з липня 2021 року. Однак на сьогоднішній день, схоже, на основі цього підходу не виникло жодних корисних або популярних ініціатив.
Дані для сцен RigNeRF отримують шляхом зйомки коротких відео на смартфоні. Для проекту дослідники RigNeRF використовували iPhone XR або iPhone 12 для всіх експериментів. У першій половині зйомки суб’єкта просять виконати широкий спектр виразів обличчя та мови, зберігаючи голову нерухомою, коли камера рухається навколо нього.
У другій половині зйомки камера зберігає фіксоване положення, тоді як об’єкт зйомки повинен рухати головою, демонструючи широкий спектр виразів. Отримані 40-70 секунд відеоматеріалу (близько 1200-2100 кадрів) являють собою весь набір даних, який використовуватиметься для навчання моделі.
Зменшення збору даних
Навпаки, системи автокодування, такі як DeepFaceLab, вимагають відносно трудомісткого збору та курування тисяч різноманітних фотографій, часто взятих із відео YouTube та інших каналів соціальних мереж, а також із фільмів (у випадку глибоких фейків знаменитостей).
Отримані навчені моделі автокодерів часто призначені для використання в різноманітних ситуаціях. Однак найвибагливіші «знаменитості» дипфейкерів можуть тренувати цілих моделей з нуля для одного відео, незважаючи на те, що навчання може тривати тиждень і більше.
Незважаючи на застереження від дослідників нової статті, «клаптик» і широко зібрані набори даних, які використовують порно з штучним інтелектом, а також популярні «переробки глибоких фейків» YouTube/TikTok, здається, навряд чи дадуть прийнятні та послідовні результати в системі глибоких фейків, такій як RigNeRF, яка має спеціальну для сцени методологію. Враховуючи обмеження на збір даних, викладені в новій роботі, це може виявитися, до певної міри, додатковим запобіжником проти випадкового незаконного привласнення особи зловмисними дипфейкерами.
Адаптація NeRF до Deepfake Video
NeRF — це метод, заснований на фотограмметрії, у якому невелика кількість вихідних зображень, зроблених з різних точок зору, збирається в тривимірний нейронний простір, який можна досліджувати. Цей підхід став популярним на початку цього року, коли NVIDIA представила свій Миттєвий НеРФ система, здатна скоротити непомірний час навчання NeRF до хвилин або навіть секунд:

Миттєвий НеРФ. Джерело: https://www.youtube.com/watch?v=DJ2hcC1orc4
Результуюча сцена поля нейронного випромінювання є, по суті, статичним середовищем, яке можна досліджувати, але яке важко редагувати. Дослідники відзначають, що дві попередні ініціативи на основі NeRF – ГіперНеРФ + Е/П та NerFACE – спробували синтез відео обличчя та (очевидно, заради повноти та старанності) порівняли RigNeRF із цими двома фреймворками в раунді тестування:


Якісне порівняння між RigNeRF, HyperNeRF і NerFACE. Перегляньте пов’язані вихідні відео та PDF для версій вищої якості. Джерело статичного зображення: https://arxiv.org/pdf/2012.03065.pdf
Однак у цьому випадку результати на користь RigNeRF є досить аномальними з двох причин: по-перше, автори зауважують, що «не існує жодної роботи для порівняння яблука з яблуком»; по-друге, це зумовило необхідність обмеження можливостей RigNeRF, щоб принаймні частково відповідати більш обмеженій функціональності попередніх систем.
Оскільки результати не є поступовим покращенням попередньої роботи, а скоріше являють собою «прорив» у редагуванні та корисності NeRF, ми залишимо раунд тестування осторонь і натомість подивимося, чим RigNeRF відрізняється від своїх попередників.
Об'єднані сильні сторони
Основним обмеженням NerFACE, який може створювати контроль пози/виразу в середовищі NeRF, є те, що він передбачає, що вихідний матеріал буде знятий статичною камерою. Фактично це означає, що він не може створити нові погляди, які виходять за межі його обмежень захоплення. Це створює систему, яка може створювати «рухомі портрети», але яка не підходить для відео у стилі deepfake.
З іншого боку, HyperNeRF, здатний генерувати нові та гіперреальні види, не має засобів, які б дозволяли йому змінювати пози голови чи вирази обличчя, що знову ж таки не призводить до будь-якого конкурента для глибоких фейків на основі автокодерів.
RigNeRF здатний поєднати ці дві ізольовані функції, створивши «канонічний простір», базову лінію за замовчуванням, від якої відхилення та деформації можуть бути введені за допомогою вхідних даних від модуля 3DMM.
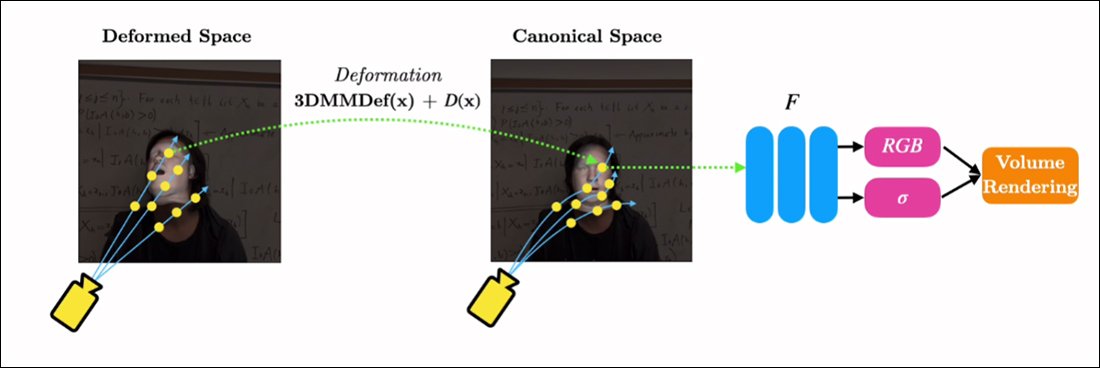
Створення «канонічного простору» (без пози, без виразу), на який можуть діяти деформації (тобто пози та вирази), створені за допомогою 3DMM.
Оскільки система 3DMM не буде точно відповідати знятому об’єкту, важливо компенсувати це під час зйомки. RigNeRF досягає цього за допомогою попереднього поля деформації, яке обчислюється за a Багатошаровий перцептрон (MLP), отримані з вихідного кадру.

Параметри камери, необхідні для розрахунку деформацій, отримують за допомогою COLMAP, тоді як вираз і параметри форми для кожного кадру отримані з DECA.
Позиціонування додатково оптимізоване орієнтир примірка і параметри камери COLMAP, а через обмеження обчислювальних ресурсів відеовихід знижується до роздільної здатності 256 × 256 для навчання (апаратно обмежений процес скорочення, який також заважає сцені глибокого підроблення автокодувальника).
Після цього мережа деформації тренується на чотирьох V100 – потужному апаратному забезпеченні, яке навряд чи буде в межах досяжності звичайних ентузіастів (проте, коли мова йде про навчання машинному навчанню, часто можна обміняти вагу на час і просто прийняти цю модель навчання буде питанням днів або навіть тижнів).
На завершення дослідники стверджують:
«На відміну від інших методів, RigNeRF завдяки використанню модуля деформації, керованого 3DMM, здатний моделювати позу голови, вирази обличчя та повну 3D-портретну сцену з високою точністю, таким чином забезпечуючи кращу реконструкцію з чіткими деталями».
Перегляньте вбудовані відео нижче для отримання додаткової інформації та відеозаписів результатів.


Вперше опубліковано 15 червня 2022 р.















