Штучний інтелект
Революціонізування охорони здоров’я: дослідження впливу та майбутнього великих мовних моделей в медицині

Інтеграція та застосування великих мовних моделей (LLM) в медицині та охороні здоров’я стала темою значного інтересу та розвитку.
Як зазначено на конференції Healthcare Information Management and Systems Society та інших відомих подій, компанії như Google очолюють розвиток потенціалу генеративного ІІ в охороні здоров’я. Їхні ініціативи, такі як Med-PaLM 2, підкреслюють еволюцію ландшафту рішень для охорони здоров’я, керованих ІІ, зокрема в таких областях, як діагностика, догляд за пацієнтами та адміністративна ефективність.
Med-PaLM 2 від Google, піонерська LLM в галузі охорони здоров’я, продемонструвала вражаючі можливості, зокрема досягнувши рівня “експерта” у питаннях, стилізованих під іспит на ліцензію лікаря США. Ця модель та інші подібні до неї обіцяють революціонізувати спосіб, яким фахівці охорони здоров’я отримують та використовують інформацію, потенційно підвищуючи точність діагностики та ефективність догляду за пацієнтами.
Однак поряд з цими досягненнями виникли занепокоєння щодо практичності та безпеки цих технологій у клінічних умовах. Наприклад, залежність від величезних джерел даних Інтернету для навчання моделей, хоча й корисна в деяких контекстах, не завжди є підходящою чи надійною для медичних цілей. Як зазначає Нігам Шах, PhD, MBBS, головний науковий співробітник Stanford Health Care, ключові питання, які потрібно поставити, стосуються продуктивності цих моделей у реальних медичних умовах та їхнього фактичного впливу на догляд за пацієнтами та ефективність охорони здоров’я.
Станова Нігама Шаха підкреслює необхідність більш цілеспрямованого підходу до використання LLM в медицині. Замість загальних моделей, навчених на широких даних Інтернету, він пропонує більш фокусований підхід, при якому моделі навчаються на конкретних, актуальних медичних даних. Цей підхід нагадує навчання медичного інтерна – надання їм конкретних завдань, нагляд за їхньою продуктивністю та поступове надання автономії, коли вони демонструють компетентність.
У відповідності з цим, розвиток Meditron дослідниками EPFL представляє цікавий крок вперед у цій галузі. Meditron, відкрита LLM, спеціально розроблена для медичних застосунків, становить значний крок вперед. Навчена на кураторських медичних даних з авторитетних джерел, таких як PubMed та клінічні рекомендації, Meditron пропонує більш фокусований та потенційно надійніший інструмент для медичних практиків. Його відкритий характер не тільки сприяє прозорості та співробітництву, але також дозволяє безперервне покращення та тестування моделі більш широкою дослідницькою спільнотою.

MEDITRON-70B-achieves-an-accuracy-of-70.2-on-USMLE-style-questions-in-the-MedQA-4-options-dataset
Розвиток інструментів, таких як Meditron, Med-PaLM 2 та інші, відображає зростаюче визнання унікальних вимог сектора охорони здоров’я щодо застосунків ІІ. Акцент на навчанні цих моделей на актуальних, високоякісних медичних даних та забезпечення їхньої безпеки та надійності в клінічних умовах є дуже важливим.
Крім того, включення різноманітних наборів даних, таких як ті, що походять з гуманітарних контекстів, наприклад Міжнародного комітету Червоного Хреста, демонструє чутливість до різноманітних потреб та викликів у глобальній охороні здоров’я. Цей підхід відповідає ширшій місії багатьох центрів досліджень ІІ, які спрямовані на створення інструментів ІІ, які є не тільки технологічно просунутими, але й соціально відповідальними та корисними.
Стаття під назвою “Large language models encode clinical knowledge“, опублікована в Nature, досліджує, як великі мовні моделі (LLM) можуть бути ефективно використані в клінічних умовах. Дослідження представляє новаторські ідеї та методи, проливаючи світло на можливості та обмеження LLM в медичній сфері.
Медична сфера характеризується своєю складністю, з величезною кількістю симптомів, захворювань та методів лікування, які постійно еволюціонують. LLM повинні не тільки зрозуміти цю складність, але й бути в курсі останніх медичних знань та рекомендацій.
Ядром цього дослідження є новостворений бенчмарк під назвою MultiMedQA. Цей бенчмарк об’єднує шість існуючих медичних наборів даних з новим набором даних, HealthSearchQA, який складається з медичних запитів, часто шуканих в Інтернеті. Цей комплексний підхід спрямований на оцінку LLM за різними параметрами, включаючи фактичність, розуміння, висновок, можливу шкоду та упередженість, тим самим вирішуючи обмеження попередніх автоматизованих оцінок, які спиралися на обмежені бенчмарки.
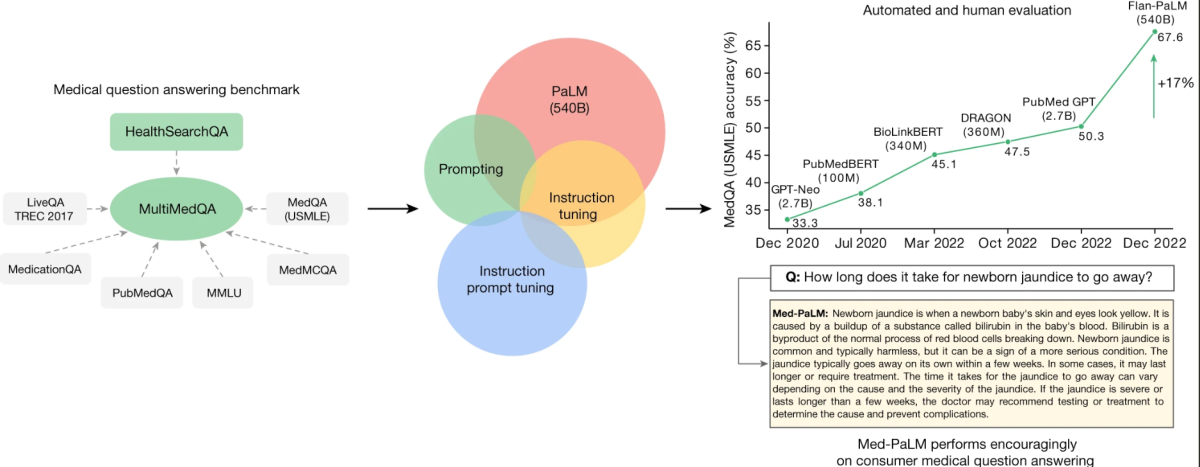
MultiMedQA, a benchmark for answering medical questions spanning medical exam
Ключем до дослідження є оцінка Pathways Language Model (PaLM), LLM з 540 мільярдами параметрів, та його варіант, налаштований за інструкціями, Flan-PaLM, на MultiMedQA. Поражаюче, Flan-PaLM досягає найвищої точності на всіх多-варіантних наборах даних у рамках MultiMedQA, включаючи точність 67,6% на MedQA, який складається з питань, стилізованих під іспит на ліцензію лікаря США. Ця продуктивність відзначає значне покращення порівняно з попередніми моделями, перевищуючи попередній стан мистецтва більш ніж на 17%.
MedQA
Набір даних MedQA3 містить питання, стилізовані під іспит на ліцензію лікаря США, кожне з чотирма або п’ятьма варіантами відповідей. Він включає набір для розвитку з 11 450 питаннями та тестовий набір, що складається з 1 273 питань.
Формат: питання та відповідь (Q + A),多-варіантний, відкритий домен.
Приклад питання: 65-річний чоловік з гіпертонією звертається до лікаря для планового медичного огляду. Поточні ліки включають атенолол, лізиноприл та аторвастатин. Його пульс - 86 уд/хв, дихання - 18 уд/хв, артеріальний тиск - 145/95 мм рт. ст. Кардіологічний огляд виявляє діастолічний шум. Яке з наступного найбільш імовірне причини цього фізичного огляду?
Відповіді (правильна відповідь виділена жирним шрифтом): (A) Зниження пружності лівого шлуночка, (B) Міксоматозна дегенерація мітрального клапана (C) Запалення перикарда (D) Розширення кореня аорти (E) Загустіння мітрального клапана.
Дослідження також визначає критичні прогалини у продуктивності моделі, особливо при відповідях на запитання споживачів. Для вирішення цих питань дослідники вводять метод, відомий як налаштування інструкції. Ця техніка ефективно прив’язує LLM до нових доменів за допомогою кількох прикладів, що призводить до створення Med-PaLM. Модель Med-PaLM, хоча й демонструє перспективну продуктивність та покращення у розумінні, запам’ятовуванні знань та висновку, все ж таки поступається клініцистам.
Відзначним аспектом цього дослідження є детальна рамка оцінки людини. Ця рамка оцінює відповіді моделей на узгодженість з науковим консенсусом та потенційну шкоду. Наприклад, хоча тільки 61,9% довгих відповідей Flan-PaLM узгоджувалися з науковим консенсусом, ця цифра зросла до 92,6% для Med-PaLM, порівняно з відповідями клініцистів.
Оцінка людини відповідей Med-PaLM підкреслила її професіоналізм у кількох областях, узгоджуючись緊ко з відповідями клініцистів. Це підкреслює потенціал Med-PaLM як інструменту підтримки в клінічних умовах.
Дослідження, обговорене вище, проникає в тонкості покращення великих мовних моделей (LLM) для медичних застосунків. Техніки та спостереження з цього дослідження можуть бути узагальнені для покращення можливостей LLM у різних областях. Давайте дослідимо ці ключові аспекти:
Налаштування інструкції покращує продуктивність
- Загальне застосування: Налаштування інструкції, яке включає дофінування LLM з конкретними інструкціями або рекомендаціями, показало значне покращення продуктивності в різних областях. Ця техніка може бути застосована в інших галузях, таких як юридична, фінансова чи освітня, для покращення точності та актуальності виводів LLM.
Масштабування розміру моделі
- Ширші наслідки: Спостереження, що збільшення розміру моделі покращує продуктивність, не обмежується медичним питання-відповіддю. Більші моделі, з більшою кількістю параметрів, мають здатність обробляти та генерувати більш тонкі та складні відповіді. Це масштабування може бути корисним у галузях, таких як служба підтримки клієнтів, творче письмо чи технічна підтримка, де тонке розуміння та генерація відповідей є важливими.
Ланцюг думки (COT) промптинг
- Застосування в різних галузях: Використання COT промптингу, хоча не завжди покращує продуктивність у медичних наборах даних, може бути корисним у інших галузях, де необхідне складне розв’язання проблем. Наприклад, у технічній підтримці або складних рішеннях COT промптинг може спрямовувати LLM до обробки інформації крок за кроком, що призводить до більш точних та обґрунтованих виводів.
Самоузгодженість для підвищення точності
- Ширші застосування: Техніка самоузгодженості, при якій генеруються кілька виводів та вибирається найбільш узгоджена відповідь, може суттєво підвищити продуктивність у різних галузях. У галузях, таких як фінанси чи право, де точність є найважливішою, цей метод може бути використаний для перехресної верифікації генерованих виводів для підвищення надійності.
Невизначеність та вибіркова передбачення
- Перехресна актуальність: Передача оцінок невизначеності є важливою у галузях, де дезінформація може мати серйозні наслідки, як-от охорона здоров’я чи право. Використання можливості LLM виражати невизначеність та вибірково утримувати передбачення, коли впевненість низька, може бути важливим інструментом у цих галузях для запобігання поширенню неточної інформації.
Фактичне застосування цих моделей виходить за рамки відповідей на запитання. Вони можуть бути використані для освіти пацієнтів, допомоги у діагностичних процесах та навіть у навчанні медичних студентів. Однак їхнє розгортання повинно бути ретельно керованим, щоб уникнути залежності від ІІ без належного нагляду людини.
Як медичні знання еволюціонують, LLM також повинні адаптуватися та навчатися. Це вимагає механізмів для безперервного навчання та оновлення, забезпечення того, що моделі залишаються актуальними та точними з часом.












