
Yapay Zeka
RigNeRF: Nöral Parlaklık Alanlarını Kullanan Yeni Bir Deepfakes Yöntemi

Adobe'de geliştirilen yeni araştırma, ilk uygulanabilir ve etkili deepfake yöntemini sunuyor. Nöral Parlaklık Alanları (NeRF) – 2017'de deepfake'lerin ortaya çıkışından bu yana beş yıl içinde mimaride veya yaklaşımda belki de ilk gerçek yenilik.
başlıklı yöntem RigNeRFKullanır 3D değiştirilebilir yüz modelleri (3DMM'ler), istenen girdi (yani, NeRF oluşturma işlemine empoze edilecek kimlik) ile nöral alan arasında ara bir araçsallık katmanı olarak; Son yıllarda yaygın olarak benimsenen Henüz hiçbiri video için işlevsel ve kullanışlı yüz değiştirme çerçeveleri üretmemiş olan Generative Adversarial Network (GAN) yüz sentezi yaklaşımları tarafından.

Geleneksel derin sahte videoların aksine, burada gösterilen hareketli içeriklerin hiçbiri "gerçek" değil, kısa çekimlerle eğitilmiş keşfedilebilir bir sinirsel alan. Sağda, istenen manipülasyonlar ('gülümseme', 'sola bakma', 'yukarı bakma' vb.) ile Nöral Parlaklık Alanının genellikle zorlu parametreleri arasında bir arayüz görevi gören 3B morflanabilir yüz modelini (3DMM) görüyoruz. görselleştirme Bu klibin yüksek çözünürlüklü versiyonu ve diğer örnekler için bkz. proje sayfasıveya bu makalenin sonundaki katıştırılmış videolar. Kaynak: https://shahrukhathar.github.io/2022/06/06/RigNeRF.html
3DMM'ler, parametreleri başka türlü kontrol edilmesi zor olan NeRF ve GAN gibi daha soyut görüntü sentez sistemlerine uyarlanabilen yüzlerin etkin CGI modelleridir.
Yukarıdaki resimde (ortadaki resim, mavi gömlekli adam) ve doğrudan aşağıdaki resimde (soldaki resim, mavi gömlekli adam) gördüğünüz şey, içine küçük bir ' yamasının yer aldığı 'gerçek' bir video değildir. Sahte 'yüz bindirildi, ancak gövde ve arka plan dahil olmak üzere yalnızca hacimsel bir nöral işleme olarak var olan tamamen sentezlenmiş bir sahne:

Doğrudan yukarıdaki örnekte, sağdaki gerçek hayattan video (kırmızı elbiseli kadın), soldaki yakalanan kimliği (mavi gömlekli adam) RigNeRF aracılığıyla 'kukla' için kullanılır; bu (yazarların iddia ettiği) ilktir. Yeni görünüm sentezleri gerçekleştirirken poz ve ifade ayrımını sağlayan NeRF tabanlı sistem.
Yukarıdaki resimde soldaki erkek figürü, 70 saniyelik bir akıllı telefon videosundan 'yakalandı' ve giriş verileri (tüm sahne bilgileri dahil) daha sonra sahneyi elde etmek için 4 V100 GPU'da eğitildi.
3DMM tarzı parametrik donanımlar şu şekilde de mevcut olduğundan: tüm vücut parametrik CGI proxy'leri (sadece yüz donanımları yerine), RigNeRF, gerçek insan hareketinin, dokusunun ve ifadesinin CGI tabanlı parametrik katmana aktarıldığı ve daha sonra eylemi ve ifadeyi işlenmiş NeRF ortamlarına ve videolarına çevirecek olan tam vücut derin taklitlerinin olasılığını potansiyel olarak açar. .
RigNeRF'e gelince - manşetlerin terimi anladığı mevcut anlamda bir derin sahte yöntem olarak nitelendiriliyor mu? Yoksa DeepFaceLab ve diğer emek yoğun, 2017 dönemi otomatik kodlayıcı derin sahte sistemlerine de koşan başka bir yarı aksak mı?
Yeni makalenin araştırmacıları bu noktada net:
"Yüzleri yeniden canlandırabilen bir yöntem olan RigNeRF, kötü aktörler tarafından derin sahte görüntüler oluşturmak için kötüye kullanılmaya eğilimlidir."
Yeni kâğıt başlıklı RigNeRF: Tamamen Kontrol Edilebilir Nöral 3D Portreler, ve RigNeRF'in geliştirilmesi sırasında Adobe'de stajyer olan Stonybrook Üniversitesi'nden ShahRukh Atha ve Adobe Research'ten diğer dört yazardan geliyor.
Otomatik Kodlayıcı Tabanlı Deepfakelerin Ötesinde
Son birkaç yılda manşetlere konu olan viral deepfake'lerin çoğu, otomatik kodlayıcı-tabanlı sistemler, 2017'de anında yasaklanan r/deepfakes alt dizininde yayınlanan koddan türetilmiştir - daha önce olmasa da kopyalandı şu anda çatallanmış olduğu GitHub'a binden fazla kez, en azından popüler (eğer tartışmalı) Derin Yüz Laboratuvarı dağıtım ve aynı zamanda Yüz nakli projesi.
GAN ve NeRF'nin yanı sıra, otomatik kodlayıcı çerçeveleri, gelişmiş yüz sentezi çerçeveleri için "yönergeler" olarak 3DMM'leri de denedi. Bunun bir örneği, HifiFace projesi Ancak, bu yaklaşımdan bugüne kadar hiçbir kullanılabilir veya popüler girişim gelişmemiş gibi görünüyor.
RigNeRF sahneleri için veriler, kısa akıllı telefon videoları çekilerek elde edilir. Proje için RigNeRF araştırmacıları, tüm deneyler için bir iPhone XR veya bir iPhone 12 kullandı. Çekimin ilk yarısında, kişiden kamera etrafında hareket ederken başını sabit tutarken çok çeşitli yüz ifadeleri ve konuşma yapması istenir.
Yakalamanın ikinci yarısında, konu geniş bir ifade yelpazesi sergilerken başını hareket ettirmesi gerekirken kamera sabit bir konumu korur. Ortaya çıkan 40-70 saniyelik görüntü (yaklaşık 1200-2100 kare), modeli eğitmek için kullanılacak tüm veri setini temsil eder.
Veri Toplama İşlemlerini Azaltmak
Buna karşılık, DeepFaceLab gibi otomatik kodlayıcı sistemler, genellikle YouTube videoları ve diğer sosyal medya kanallarının yanı sıra filmlerden (ünlülerin deepfake'leri söz konusu olduğunda) alınan binlerce farklı fotoğrafın nispeten zahmetli bir şekilde toplanmasını ve iyileştirilmesini gerektirir.
Ortaya çıkan eğitilmiş otomatik kodlayıcı modellerinin genellikle çeşitli durumlarda kullanılması amaçlanır. Bununla birlikte, eğitimin bir hafta veya daha uzun sürmesine rağmen, en titiz "ünlü" deepfaker'lar tek bir video için tüm modelleri sıfırdan eğitebilir.
Yeni makalenin araştırmacılarının uyarı notuna rağmen, yapay zeka pornosuna ve popüler YouTube/TikTok "deepfake yeniden biçimlendirmelerine" güç veren "patchwork" ve geniş bir şekilde birleştirilmiş veri kümelerinin, RigNeRF gibi bir derin sahte sistemde kabul edilebilir ve tutarlı sonuçlar üretmesi pek olası görünmüyor. sahneye özgü bir metodolojiye sahiptir. Yeni çalışmada özetlenen veri yakalama kısıtlamaları göz önüne alındığında, bu, bir dereceye kadar, kötü niyetli derin sahtekarlar tarafından kimliğin kötüye kullanılmasına karşı ek bir koruma sağlayabilir.
NeRF'i Deepfake Videoya Uyarlama
NeRF, çeşitli bakış açılarından alınan az sayıda kaynak resmin keşfedilebilir bir 3D sinir uzayında bir araya getirildiği fotogrametri tabanlı bir yöntemdir. Bu yaklaşım, bu yılın başlarında NVIDIA'nın Anında NeRF NeRF için fahiş eğitim sürelerini dakikalara, hatta saniyelere indirebilen sistem:

Anında NeRF. Kaynak: https://www.youtube.com/watch?v=DJ2hcC1orc4
Ortaya çıkan Nöral Parlaklık Alanı sahnesi, temelde keşfedilebilen, ancak keşfedilebilen statik bir ortamdır. düzenlemesi zor. Araştırmacılar, önceki iki NeRF tabanlı girişimin – HyperNeRF + E/P ve nerface - yüz video sentezinde bir bıçak aldılar ve (görünüşe göre bütünlük ve özen uğruna) RigNeRF'i bir test turunda bu iki çerçeveye karşı koydular:


RigNeRF, HyperNeRF ve NerFACE arasında nitel bir karşılaştırma. Daha yüksek kaliteli sürümler için bağlantılı kaynak videolara ve PDF'ye bakın. Statik görüntü kaynağı: https://arxiv.org/pdf/2012.03065.pdf
Bununla birlikte, bu durumda, RigNeRF'i destekleyen sonuçlar iki nedenden dolayı oldukça anormaldir: ilk olarak, yazarlar 'elma-elma karşılaştırması için mevcut bir çalışma olmadığını' gözlemlemektedir; ikincisi, bu, RigNeRF'in yeteneklerinin sınırlandırılmasını, önceki sistemlerin daha kısıtlı işlevselliğiyle en azından kısmen eşleştirmeyi gerektirmiştir.
Sonuçlar, önceki çalışma üzerinde artımlı bir gelişme değil, NeRF'in düzenlenebilirliği ve yardımcı programında bir 'atılım'ı temsil ettiğinden, test turunu bir kenara bırakacağız ve bunun yerine RigNeRF'in öncekilerden farklı olarak ne yaptığını göreceğiz.
Kombine Güçlü Yönler
Bir NeRF ortamında poz/ifade kontrolü oluşturabilen NerFACE'in birincil sınırlaması, kaynak görüntülerin statik bir kamera ile çekileceğini varsaymasıdır. Bu, etkin bir şekilde, yakalama sınırlamalarının ötesine geçen yeni görüşler üretemeyeceği anlamına gelir. Bu, "hareketli portreler" oluşturabilen, ancak derin sahte tarzı video için uygun olmayan bir sistem üretir.
Öte yandan HyperNeRF, yeni ve hiper-gerçek görünümler üretebilse de, kafa duruşlarını veya yüz ifadelerini değiştirmesine izin veren hiçbir araca sahip değildir, bu da otomatik kodlayıcı tabanlı derin sahteler için yine herhangi bir rakiple sonuçlanmaz.
RigNeRF, 3DMM modülünden gelen girdi aracılığıyla sapmaların ve deformasyonların harekete geçirilebileceği varsayılan bir taban çizgisi olan bir "kanonik alan" oluşturarak bu iki yalıtılmış işlevi birleştirebilir.
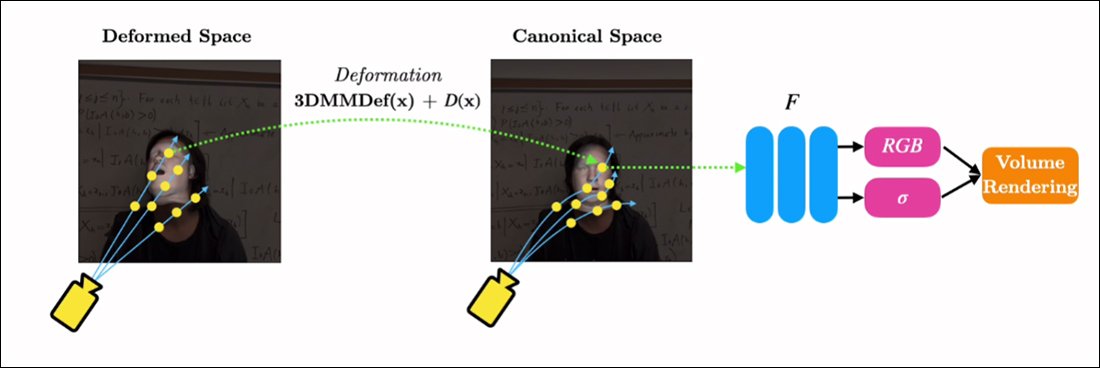
3DMM aracılığıyla üretilen deformasyonların (örneğin, pozlar ve ifadeler) etki edebileceği bir 'kanonik alan' (poz yok, ifade yok) yaratmak.
3DMM sistemi yakalanan özneyle tam olarak eşleşmeyeceğinden, süreçte bunu telafi etmek önemlidir. RigNeRF bunu, önceden hesaplanan bir deformasyon alanıyla gerçekleştirir. Çok Katmanlı Algılayıcı (MLP) kaynak görüntüden türetilmiştir.

Deformasyonları hesaplamak için gerekli kamera parametreleri şu şekilde elde edilir: KOLMAP, her çerçeve için ifade ve şekil parametreleri elde edilirken Kİ.
Konumlandırma daha da optimize edilmiştir dönüm noktası uydurma ve COLMAP'ın kamera parametreleri ve bilgi işlem kaynağı kısıtlamaları nedeniyle, video çıktısı eğitim için 256×256 çözünürlüğe düşürülür (otomatik kodlayıcı derin numaralandırma sahnesini de rahatsız eden donanım kısıtlamalı bir küçültme işlemi).
Bundan sonra, deformasyon ağı dört V100 üzerinde eğitilir; bu, sıradan meraklıların erişemeyeceği müthiş bir donanımdır (ancak, makine öğrenimi eğitimi söz konusu olduğunda, genellikle zamanla büyük miktarda takas yapmak ve bu modeli kabul etmek mümkündür) eğitim birkaç gün hatta hafta sürecektir).
Sonuç olarak, araştırmacılar şunları belirtiyor:
"Diğer yöntemlerin aksine, RigNeRF, 3DMM kılavuzlu bir deformasyon modülünün kullanımı sayesinde baş pozunu, yüz ifadelerini ve tam 3D portre sahnesini yüksek doğrulukla modelleyebiliyor ve böylece keskin ayrıntılarla daha iyi rekonstrüksiyonlar sağlıyor."
Daha fazla ayrıntı ve sonuç görüntüleri için aşağıdaki gömülü videolara bakın.


İlk olarak 15 Haziran 2022'de yayınlandı.















