Yapay Zeka
MagicDance: Gerçekçi İnsan Dansı Videosu Oluşturma

Bilgisayarla görme, çok çeşitli gerçek zamanlı görevlerdeki potansiyel uygulamaları sayesinde yapay zeka endüstrisinde en çok tartışılan alanlardan biridir. Son yıllarda bilgisayarlı görü çerçeveleri hızla gelişti; modern modeller artık yüz özelliklerini, nesneleri ve çok daha fazlasını gerçek zamanlı senaryolarda analiz edebiliyor. Bu yeteneklere rağmen insan hareketi aktarımı, bilgisayarlı görme modelleri için zorlu bir zorluk olmaya devam ediyor. Bu görev, yüz ve vücut hareketlerinin kaynak görüntü veya videodan hedef görüntü veya videoya yeniden hedeflenmesini içerir. İnsan hareketi aktarımı, görüntü veya videoların şekillendirilmesi, multimedya içeriğinin düzenlenmesi, dijital insan sentezi ve hatta algıya dayalı çerçeveler için veri üretmek için bilgisayarlı görme modellerinde yaygın olarak kullanılmaktadır.
Bu makalede, insan hareket aktarımında devrim yaratmak üzere tasarlanmış difüzyon tabanlı bir model olan MagicDance'e odaklanıyoruz. MagicDance çerçevesi özellikle 2 boyutlu insan yüz ifadelerini ve hareketlerini zorlu insan dansı videolarına aktarmayı amaçlamaktadır. Amacı, orijinal kimliği korurken belirli hedef kimlikler için yeni poz sekansına dayalı dans videoları oluşturmaktır. MagicDance çerçevesi, insan hareketlerinin çözülmesine ve cilt tonu, yüz ifadeleri ve giyim gibi görünüm faktörlerine odaklanan iki aşamalı bir eğitim stratejisi kullanır. MagicDance çerçevesini derinlemesine inceleyerek mimarisini, işlevselliğini ve performansını diğer son teknoloji ürünü insan hareketi aktarım çerçeveleriyle karşılaştıracağız. Hadi dalalım.
MagicDance: Gerçekçi İnsan Hareketi Aktarımı
Daha önce de belirtildiği gibi insan hareketi aktarımı, insan hareketlerinin ve ifadelerinin kaynak görüntüden veya videodan hedef görüntüye veya videoya aktarılmasının karmaşıklığı nedeniyle en karmaşık bilgisayarlı görme görevlerinden biridir. Geleneksel olarak, bilgisayarlı görme çerçeveleri, GAN veya Üretken Çekişmeli Ağlar yüz ifadeleri ve vücut pozları için hedef veri kümelerinde. Üretken modellerin eğitimi ve kullanılması bazı durumlarda tatmin edici sonuçlar vermesine rağmen, genellikle iki önemli sınırlamaya sahiptirler.
- Görüntü çarpıtma bileşenine büyük ölçüde güveniyorlar ve bunun sonucunda, perspektifteki bir değişiklik veya kendi kendini kapatma nedeniyle kaynak görüntüde görünmeyen vücut kısımlarını enterpolasyonla bulmakta zorlanıyorlar.
- Özellikle vahşi doğada gerçek zamanlı senaryolarda uygulamalarını sınırlayan, harici kaynaklı diğer görüntülere genelleme yapamazlar.

Modern dağıtım modelleri, farklı koşullar altında olağanüstü görüntü oluşturma yetenekleri sergilemiştir ve dağıtım modelleri artık web ölçeğindeki görüntü veri kümelerinden öğrenerek video oluşturma ve görüntüyü iç boyama gibi bir dizi aşağı yönlü görevde güçlü görseller sunma kapasitesine sahiptir. Yetenekleri nedeniyle difüzyon modelleri insan hareketi aktarım görevleri için ideal bir seçim olabilir. Her ne kadar difüzyon modelleri insan hareketi aktarımı için uygulanabilse de, oluşturulan içeriğin kalitesi açısından, kimliğin korunması veya model tasarımı ve eğitim stratejisi sınırlamalarının bir sonucu olarak zamansal tutarsızlıklar yaşanması açısından bazı sınırlamalara sahiptir. Ayrıca, difüzyona dayalı modeller diğerlerine göre önemli bir avantaj göstermemektedir. GAN çerçeveleri genellenebilirlik açısından
Geliştiriciler, insan hareketi aktarım görevlerinde difüzyon ve GAN tabanlı çerçevelerin karşılaştığı engellerin üstesinden gelmek için, benzeri görülmemiş düzeyde kimlik koruma, üstün görsel kalite, insan hareketi aktarımı için difüzyon çerçevelerinin potansiyelinden yararlanmayı amaçlayan yeni bir çerçeve olan MagicDance'i tanıttı. ve alan genelleştirilebilirliği. MagicDance çerçevesinin temel konsepti, özünde, sorunu iki aşamaya bölmektir: görünüm kontrolü ve hareket kontrolü, doğru hareket aktarım çıktıları sağlamak için görüntü yayma çerçevelerinin gerektirdiği iki yetenek.

Yukarıdaki şekil MagicDance çerçevesine kısa bir genel bakış sunmaktadır ve görülebileceği gibi çerçeve, MagicDance çerçevesini kullanmaktadır. Kararlı Difüzyon modelive aynı zamanda iki ek bileşen daha dağıtır: Görünüm Kontrol Modeli ve Pose ControlNet, burada birincisi, dikkat aracılığıyla bir referans görüntüden SD modeline görünüm rehberliği sağlarken, ikincisi koşullandırılmış bir görüntü veya videodan difüzyon modeline ifade/poz rehberliği sağlar. Çerçeve ayrıca, poz kontrolü ve görünümü birbirinden ayırmak amacıyla bu alt modülleri etkili bir şekilde öğrenmek için çok aşamalı bir eğitim stratejisi kullanır.
Özetle, MagicDance çerçevesi bir
- Görünüm-çözülmüş poz kontrolü ve görünüm kontrolü ön eğitiminden oluşan yeni ve etkili çerçeve.
- MagicDance çerçevesi, poz durumu girdilerinin ve referans görüntülerin veya videoların kontrolü altında gerçekçi insan yüz ifadeleri ve insan hareketi oluşturma kapasitesine sahiptir.
- MagicDance çerçevesi, Kararlı Difüzyon UNet çerçevesi için doğru rehberlik sunan Çok Kaynaklı Dikkat Modülünü sunarak görünümle tutarlı insan içeriği oluşturmayı amaçlamaktadır.
- MagicDance çerçevesi aynı zamanda Stabil Difüzyon çerçevesi için uygun bir uzantı veya eklenti olarak da kullanılabilir ve ayrıca parametrelerde ilave ince ayar gerektirmediği için mevcut model ağırlıklarıyla uyumluluk sağlar.
Ek olarak MagicDance çerçevesi, hem görünüm hem de hareket genellemesi için olağanüstü genelleme yetenekleri gösterir.
- Görünüm Genelleştirme: MagicDance çerçevesi, farklı görünümler oluşturma konusunda üstün yetenekler gösterir.
- Hareket Genelleştirme: MagicDance çerçevesi aynı zamanda geniş bir hareket yelpazesi oluşturma yeteneğine de sahiptir.
MagicDance: Amaçlar ve Mimari
Gerçek bir insan ya da stilize bir görüntünün belirli bir referans görüntüsü için, MagicDance çerçevesinin temel amacı, girdiye ve P'nin insan pozunu temsil ettiği {P, F} poz girişlerine göre koşullandırılmış bir çıktı görüntüsü ya da bir çıktı videosu oluşturmaktır. iskelet ve F yüz işaretlerini temsil eder. Oluşturulan çıktı görüntüsü veya video, poz girdileri tarafından tanımlanan poz ve ifadeleri korurken, referans görüntüde mevcut arka plan içeriğinin yanı sıra dahil olan insanların görünümünü ve kimliğini de koruyabilmelidir.
mimari
Eğitim sırasında MagicDance çerçevesi, referans görüntü ve aynı referans videodan alınan poz girdisi ile temel gerçeği yeniden oluşturmak için bir çerçeve yeniden yapılandırma görevi olarak eğitilir. Hareket aktarımını sağlamak için yapılan testler sırasında poz girişi ve referans görüntüsü farklı kaynaklardan alınır.
MagicDance çerçevesinin genel mimarisi dört kategoriye ayrılabilir: Ön aşama, Görünüm Kontrolü ön eğitimi, Görünüm Çözülmüş Poz Kontrolü ve Hareket Modülü.
Ön aşama
Gizli Difüzyon Modelleri veya LDM, bir otomatik kodlayıcının kullanımıyla kolaylaştırılan gizli alan içinde çalışacak benzersiz şekilde tasarlanmış difüzyon modellerini temsil eder ve Kararlı Difüzyon çerçevesi, Vektör Nicelikli-Varyasyonel kullanan LDM'lerin dikkate değer bir örneğidir. Otomatik Kodlayıcı ve geçici U-Net mimarisi. Kararlı Dağıtım modeli, metin girişlerini yerleştirmelere dönüştürerek metin girişlerini işlemek için metin kodlayıcı olarak CLIP tabanlı bir transformatör kullanır. Kararlı Yayılım çerçevesinin eğitim aşaması, modeli bir metin koşuluna ve görüntünün gizli bir temsile kodlanmasını içeren bir süreçle bir girdi görüntüsüne maruz bırakır ve bunu bir Gauss yöntemiyle yönlendirilen önceden tanımlanmış bir yayılma adımları dizisine tabi tutar. Ortaya çıkan dizi, gürültülü gizli temsillerin gürültüsünü yinelemeli olarak gizli temsillere dönüştürmek olan Kararlı Difüzyon çerçevesinin birincil öğrenme hedefi ile standart bir normal dağılım sağlayan gürültülü bir gizli temsil sağlar.
Görünüm Kontrolü Ön Eğitimi
Orijinal ControlNet çerçevesiyle ilgili önemli bir sorun, genel görünümün ağırlıklı olarak metinsel girdilerden etkilendiği, giriş görüntüsündekilere çok benzeyen pozlara sahip görüntüler üretme eğiliminde olmasına rağmen, uzamsal olarak değişen hareketler arasında görünümü tutarlı bir şekilde kontrol edememesidir. Bu yöntem işe yaramasına rağmen, metin girdilerinin değil, görünüm bilgisi için birincil kaynak olarak hizmet veren referans görüntünün olduğu görevleri içeren hareket aktarımı için uygun değildir.
MagicDance çerçevesindeki Görünüm Kontrolü Ön Eğitim modülü, katman katman bir yaklaşımla görünüm kontrolü için rehberlik sağlamak üzere yardımcı bir dal olarak tasarlanmıştır. Genel modül, metin girişlerine güvenmek yerine, çerçevenin özellikle karmaşık hareket dinamiklerini içeren senaryolarda görünüm özelliklerini doğru şekilde oluşturma yeteneğini geliştirmek amacıyla referans görüntüdeki görünüm niteliklerinden yararlanmaya odaklanır. Ayrıca, görünüm kontrolü ön eğitimi sırasında eğitilebilen yalnızca Görünüm Kontrol Modelidir.
Görünüşe Göre Çözülmüş Poz Kontrolü
Çıkış görüntüsündeki pozu kontrol etmeye yönelik saf bir çözüm, önceden eğitilmiş ControlNet modelini önceden eğitilmiş Görünüm Kontrol Modeli ile ince ayar yapmadan doğrudan entegre etmektir. Ancak entegrasyon, çerçevenin görünümden bağımsız poz kontrolüyle mücadele etmesiyle sonuçlanabilir ve bu da girdi pozları ile oluşturulan pozlar arasında bir tutarsızlığa yol açabilir. Bu tutarsızlığın üstesinden gelmek için MagicDance çerçevesi, Pose ControlNet modelinde önceden eğitilmiş Görünüm Kontrol Modeli ile birlikte ince ayar yapar.
Hareket Modülü
Görünüm-ayrışmış Pose ControlNet ve Görünüm Kontrol Modeli birlikte çalışırken, zamansal tutarsızlığa yol açsa da doğru ve etkili görüntüden harekete aktarım elde edilebilir. Zamansal tutarlılığı sağlamak için çerçeve, birincil Stabil Difüzyon UNet mimarisine ek bir hareket modülü entegre eder.
MagicDance: Eğitim Öncesi ve Veri Kümeleri
Ön eğitim için MagicDance çerçevesi, uzunlukları 350 ila 10 saniye arasında değişen, tek bir kişiyi dans ederken yakalayan ve bu videoların çoğunluğunun yüzü ve vücudun üst kısmını içeren 15'den fazla dans videosundan oluşan bir TikTok veri kümesini kullanır. insan. MagicDance çerçevesi, her bir videoyu 30 FPS'de çıkarır ve poz iskeletini, el pozlarını ve yüz işaretlerini çıkarmak için her karede OpenPose'u ayrı ayrı çalıştırır.
Ön eğitim için görünüm kontrol modeli, 64 x 8 görüntü boyutunda 100 bin adım için 10 NVIDIA A512 GPU'da 512 toplu iş boyutuyla önceden eğitilir ve ardından poz kontrolü ve görünüm kontrolü modellerine ortak olarak ince ayar yapılır. 16 bin adım için parti büyüklüğü 20'dır. Eğitim sırasında MagicDance çerçevesi, görüntülerin aynı yükseklikte ve aynı konumda kırpılmasıyla sırasıyla hedef ve referans olarak iki kareyi rastgele örnekler. Değerlendirme sırasında model, görüntüyü rastgele kırpmak yerine merkezi olarak kırpar.
MagicDance : Sonuçlar
MagicDance çerçevesinde gerçekleştirilen deneysel sonuçlar aşağıdaki görüntüde gösterilmektedir ve görülebileceği gibi MagicDance çerçevesi, tüm ölçümlerde insan hareketi aktarımında Disco ve DreamPose gibi mevcut çerçevelerden daha iyi performans göstermektedir. Adının önünde “*” bulunan çerçeveler, hedef görüntüyü doğrudan girdi olarak kullanır ve diğer çerçevelere göre daha fazla bilgi içerir.
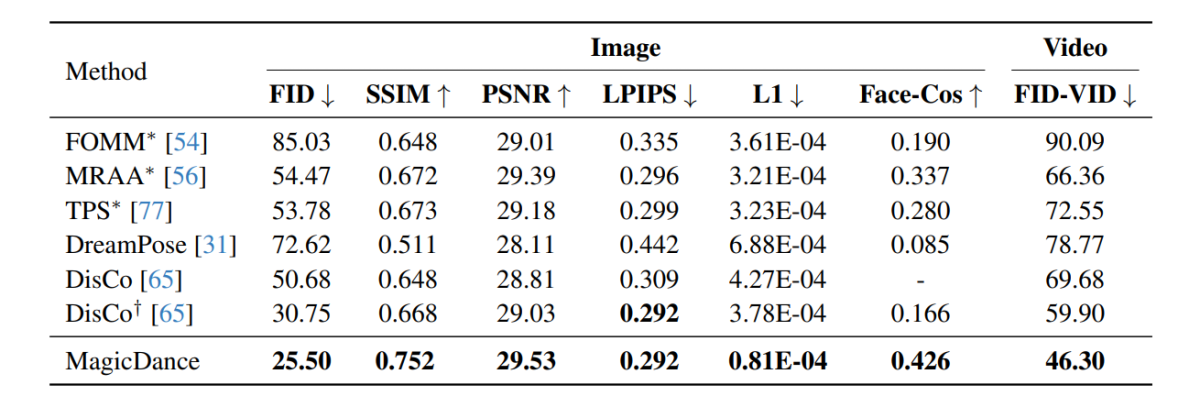
MagicDance çerçevesinin 0.426'lık Face-Cos puanına ulaşması, Disco çerçevesine göre %156.62'lik bir iyileşme ve DreamPose çerçevesiyle karşılaştırıldığında neredeyse %400 artış elde etmesi ilginçtir. Sonuçlar, MagicDance çerçevesinin kimlik bilgilerini korumaya yönelik güçlü kapasitesini gösteriyor ve performanstaki gözle görülür artış, MagicDance çerçevesinin mevcut son teknoloji yöntemlere göre üstünlüğünü gösteriyor.
Aşağıdaki rakamlar MagicDance, Disco ve TPS çerçeveleri arasındaki insan video oluşturma kalitesini karşılaştırmaktadır. Görülebileceği gibi GT, Disco ve TPS çerçeveleri tarafından oluşturulan sonuçlarda tutarsız insan pozu kimliği ve yüz ifadeleri sorunu yaşanıyor.

Ayrıca, aşağıdaki görüntü, MagicDance çerçevesi ile çeşitli yüz işaretleri altında gerçekçi ve canlı ifadeler ve hareketler üretebilen ve referans girişinden gelen kimlik bilgilerini doğru bir şekilde korurken iskelet girdilerini pozlandırabilen TikTok veri kümesinde yüz ifadesinin ve insan pozu aktarımının görselleştirilmesini göstermektedir. görüntü.

MagicDance çerçevesinin, aşağıdaki görüntüde gösterilen sonuçlarla, hedef alanda herhangi bir ek ince ayar yapılmadan bile etkileyici görünüm kontrol edilebilirliğine sahip, görünmeyen pozların ve stillerin alan dışı referans görüntülerine olağanüstü genelleme yeteneklerine sahip olduğunu belirtmekte fayda var. .

Aşağıdaki resimler MagicDance çerçevesinin yüz ifadesi aktarımı ve sıfır atış insan hareketi açısından görselleştirme yeteneklerini göstermektedir. Görüldüğü gibi MagicDance çerçevesi, vahşi insan hareketlerini mükemmel bir şekilde genelleştiriyor.

MagicDance: Sınırlamalar
OpenPose, MagicDance çerçevesinin önemli bir bileşenidir çünkü poz kontrolü için çok önemli bir rol oynar ve oluşturulan görüntülerin kalitesini ve zamansal tutarlılığını önemli ölçüde etkiler. Bununla birlikte, MagicDance çerçevesi, özellikle görüntülerdeki nesneler kısmen görünür olduğunda veya hızlı hareket gösterdiğinde, yüz işaretlerini tespit etmede ve iskeletleri doğru şekilde pozlandırmada hala biraz zorlayıcıdır. Bu sorunlar, oluşturulan görüntüde bozulmalara neden olabilir.
Sonuç
Bu yazımızda insanın hareket aktarımında devrim yaratmayı amaçlayan difüzyon tabanlı bir model olan MagicDance'den bahsettik. MagicDance çerçevesi, kimliği sabit tutarken belirli hedef kimlikler için yeni poz dizisine dayalı insan dans videoları oluşturmak amacıyla zorlu insan dans videolarına 2 boyutlu insan yüz ifadelerini ve hareketlerini aktarmaya çalışır. MagicDance çerçevesi, insan hareketlerinin çözülmesi ve cilt tonu, yüz ifadeleri ve kıyafetler gibi görünümler için iki aşamalı bir eğitim stratejisidir.
MagicDance, yüz ve hareket ifadesi aktarımını birleştirerek gerçekçi insan videosu oluşturmayı kolaylaştıran ve mevcut yöntemlere göre önemli bir ilerleme gösteren, daha fazla ince ayar gerektirmeden vahşi animasyon oluşturmada tutarlılık sağlayan yeni bir yaklaşımdır. Ayrıca MagicDance çerçevesi, karmaşık hareket dizileri ve çeşitli insan kimlikleri üzerinde olağanüstü genelleme yetenekleri göstererek MagicDance çerçevesini yapay zeka destekli hareket aktarımı ve video oluşturma alanında lider konuma getiriyor.












